【 TiDB 使用环境】
【概述】:tikv不能缩容
【背景】:pod tikv-1 pv损坏,扩容修复后(tidbcliuster replica设置为4),缩容(tidbcliuster replica设置为3),无法形成3 pod
【现象】:无
【问题】:无法缩容
【业务影响】:
【TiDB 版本】:5.0.1
【TiDB Operator 版本】:1.1.4
【K8s 版本】:1.12
参考文档:https://docs.pingcap.com/zh/tidb-in-kubernetes/stable/scale-a-tidb-cluster
TidbCluster 对象中的 spec.tikv.replicas修改为3,
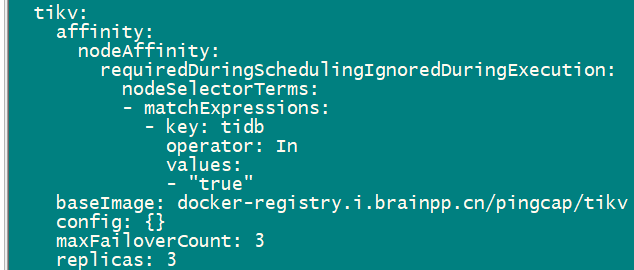
当前tikv 4个pod

1 个赞
tikv 节点的缩容需要 transfter leader 以及 balance region,这个过程跟 region 的数量有关,如果想了解 region 迁移的速度,那么可通过下面的方式:
1、查看被缩容 tikv 剩余的 leader 以及 region 数量
1)grafana pd → Statistics - Balance → Store leader count / Store Region count
2、确认 leader 以及 region 迁移的速度,参考下述文档
https://docs.pingcap.com/zh/tidb/v5.0/pd-scheduling-best-practices#节点下线速度慢
另外,节点中空 region 过多也可能会对调度产生影响 ~~
3、查看被下线 tikv 节点状态,下线过程中为 offline,理论上该节点线下完成后变为 tombstone

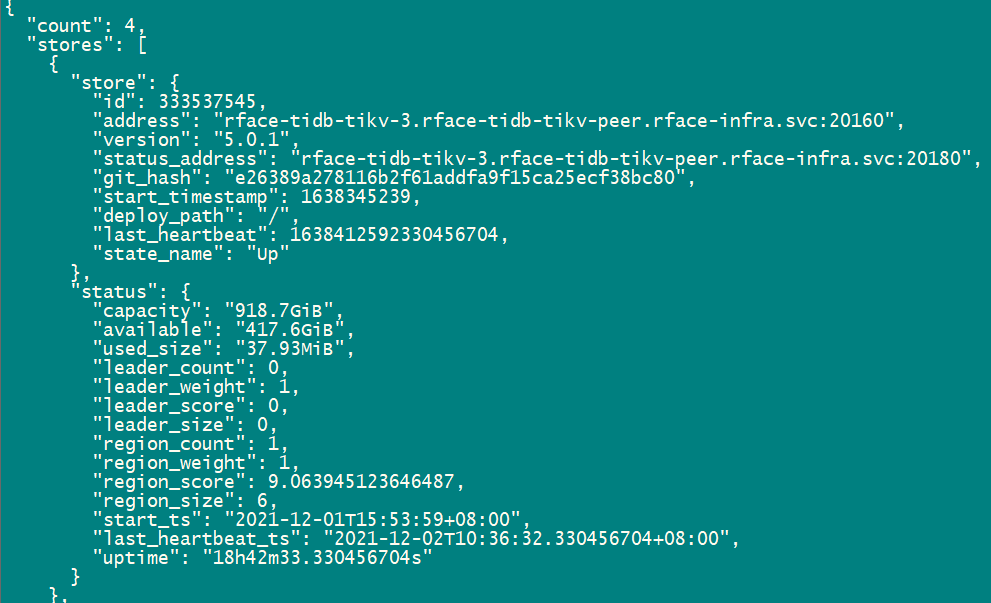
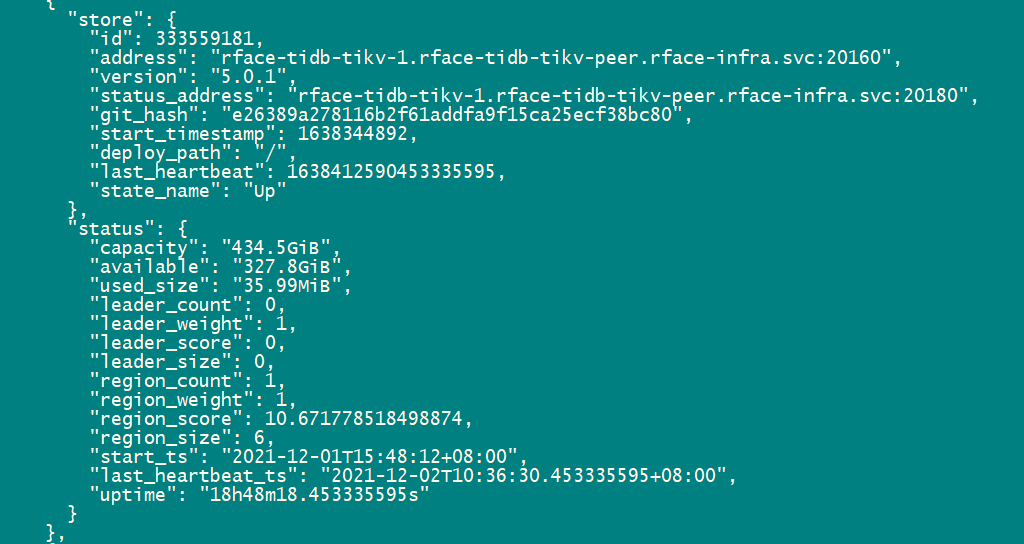
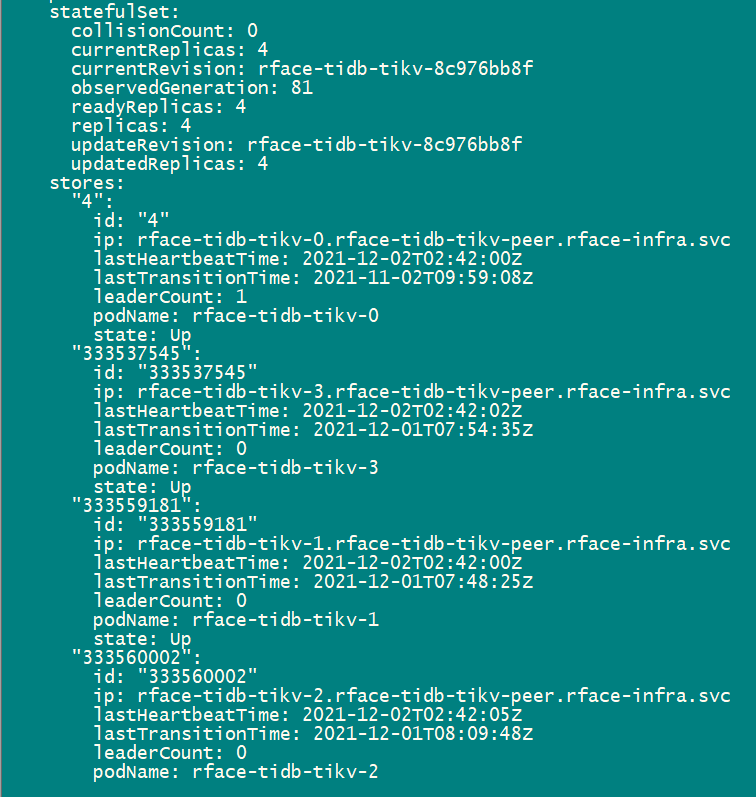
现在看如果是确认节点在缩容的过程中,那么该 store 的 state 状态会变为 offline。通过上面的截图可见,集群中应该是没有处于缩容状态中的 store~
所以,辛苦再确认下,下面的信息:
1、replica 3 --> replica 4,是 kubectl edit tidbcluster ${cluster_name} -n ${namespace} 修改,完成 tikv 节点的扩容
2、 kubectl get tidbcluster ${cluster_name} -n ${namespace} -oyaml 辛苦再看下这个结果
缩容:replica 4 → replica 3 ,store 的 state 状态没有变为 offline
kubectl get tidbcluster ${cluster_name} -n ${namespace} -oyaml 结果如下:tidb-cluster.yaml (36.3 KB)
1.kubectl describe tc ${cluster_name} -n ${namespace} 输出内容看下。
2.另外把最近的 controller 的日志也发下
tc.log (9.6 KB)
controller 日志帮给个命令
kubectl logs blade-controller-manager-xxxx-xxxxx -n xxxxx
抓个 10 分钟看下,cluster_name和 kv pod name 都提供下
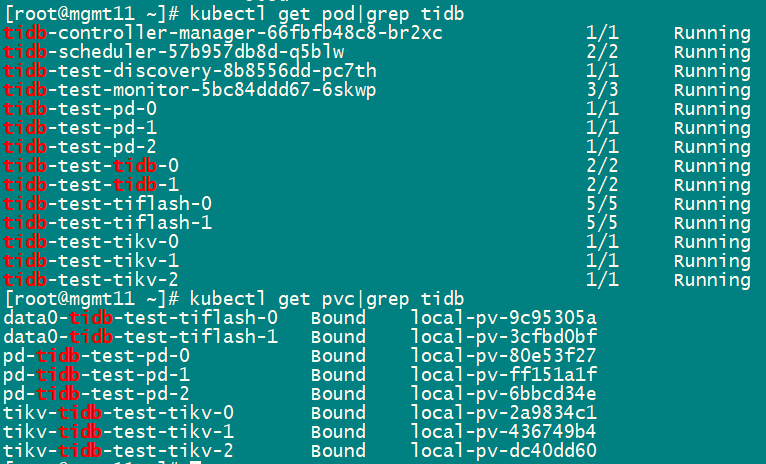
E1203 15:34:38.570870 1 tidb_initializer_controller.go:133] TiDBInitializer: rface-infra/tidb-test-init, sync failed, err: syncTiDBInitConfigMap: failed to get tidbcluster tidb-test for TidbInitializer rface-infra/tidb-test-init, error: tidbcluster.pingcap.com “tidb-test” not found, requeuing
I1203 15:34:40.613058 1 tidbcluster_control.go:66] TidbCluster: [rface-infra/rface-tidb] updated successfully
E1203 15:34:41.554134 1 pd_member_manager.go:213] failed to sync TidbCluster: [r-lab/tidb-face]'s status, error: Error response 503 URL http://tidb-face-pd.r-lab:2379/pd/health,body response: no leader
tc 同步报错,pd 也报没有 leader,这一块先看下 pd 有 leader 嘛
pd-ctl 查看是有的leader的
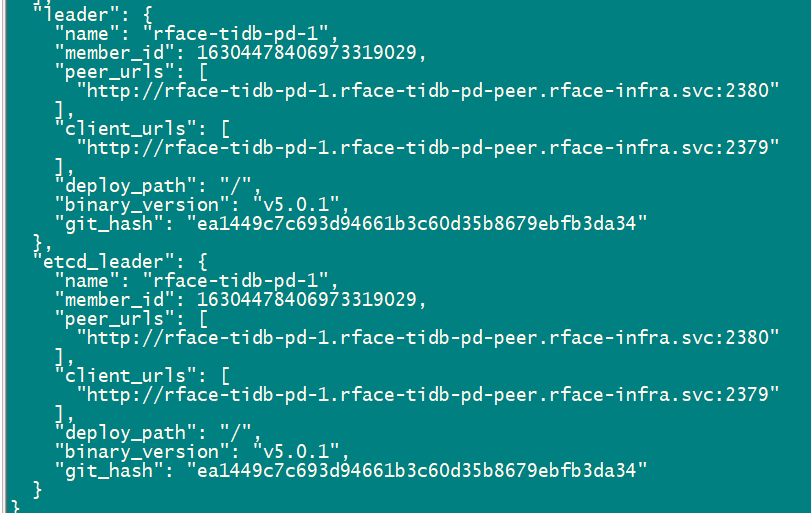
没看到报错什么意思
这个operator有2个tidbcluster,缩容的是rface-infra,为啥报另一个“tidb-test” not found呢?
具体在如何排除?

这个是r-lab namespace下的和rface-infra 下的tidb集群无关。
你好,请问你的部署Operator 流程和tidb cluster 流程是按照规范部署的么?问题是否还在?
https://docs.pingcap.com/zh/tidb-in-kubernetes/stable/use-auto-failover/#tikv-故障转移策略 参考这里面,确认一下是否配置了recoverFailover:true
帖子回复有些慢,部署流程规范之类回复有些泛泛哦;已部署多次,部署后,可以正常使用。扩容测试时出现出现问题
默认是true,无调整。
默认值为 False 请帮忙确认一下,配置 spec.tikv.recoverFailover: true 可能会解决你的问题
Operator 在发现有 TiKV 挂掉之后,会自动补充 TiKV 节点,且不会被缩容掉,配置这个参数可以缩容掉自动扩容的节点
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。