zzw6776
(bug发现者)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
v5.2.1
【概述】场景+问题概述
同时缩容6个tikv和4个pd和4个tidb和3个tiflash,现在tikv一直为Pending Offline状态,pd,tidb,tiflash已成功下线,通过store xxx观看,发现最后剩余的region迁移极慢,重启过后照样非常慢,同时控制台一直有error日志
日志如下
logs (2).zip (55.9 KB)
看着速度1分钟1个region
现在调整了以下参数 并重新reload
split-region-on-table 为false
pd-ctl config set max-merge-region-size 20
pd-ctl config set max-merge-region-keys 200000
pd-ctl config set merge-schedule-limit 8
1 个赞
xfworld
(魔幻之翼)
2
能描述下你的操作过程么?
这个是模拟快速缩容的场景么?
1 个赞
zzw6776
(bug发现者)
3
执行tiup cluster scale-in tidb-online --node 192.168.10.146:20161,192.168.10.146:20162,192.168.10.146:20163,192.168.10.146:4001,192.168.10.146:4000,192.168.10.146:2381,192.168.10.146:2379
执行
执行tiflash设置replace为0
缩容tiflash
执行
tiup cluster scale-in tidb-online --node 192.168.10.147:20161,192.168.10.147:20162,192.168.10.147:20163,192.168.10.147:4001,192.168.10.147:4000,192.168.10.147:2381,192.168.10.147:2379
睡了个午觉回来发现还没有缩容完
执行tiup cluster reload tidb-online
然后现在就卡在这了
2:不是 因为这三台物理机磁盘要重新格式化分配,所以现在想到的办法是把148,147的全部缩容 然后调整磁盘后再扩回去,然后再去调整146的磁盘
1 个赞
xfworld
(魔幻之翼)
4
那你要先驱逐 147 ,和 148 副本的 leader,然后才能缩容了
我不知道你的副本是怎么安排的? 5副本? 3副本?
1 个赞
zzw6776
(bug发现者)
5
3副本 在剩下这1000来个之前的驱逐速度一直是正常的 只有最后才卡在这
xfworld
(魔幻之翼)
6
关键是单节点多个 tikv 实例,然后 不知道副本是否有迁移完成
现在集群能正常访问么?
xfworld
(魔幻之翼)
8
参考一下这个帖子,我估计是有资源竞争的问题,没办法快速的完成region 的调度
https://asktug.com/t/topic/93996
zzw6776
(bug发现者)
9
这个文章看过了,没有给出实际解决方案,错误日志我在主贴里贴了,目前不知道怎么处理这个情况
xfworld
(魔幻之翼)
10
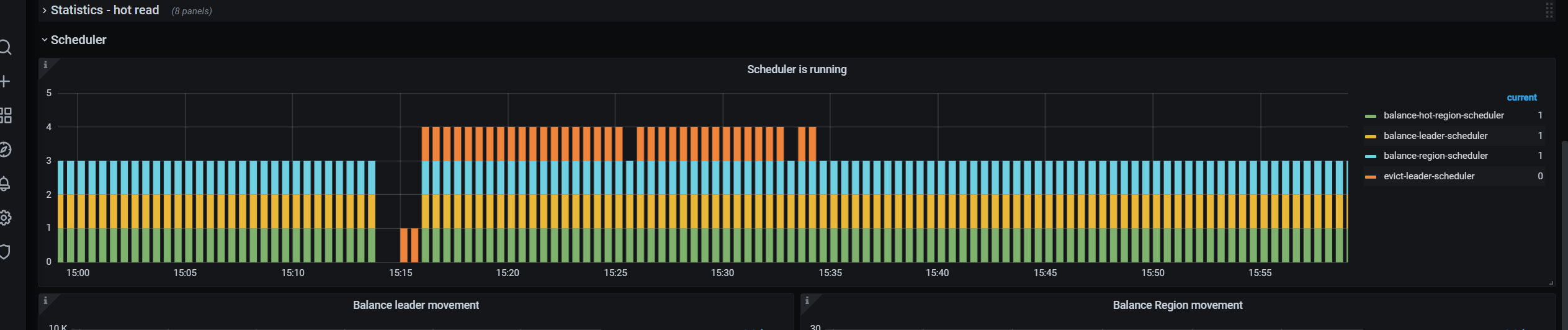
观测下 grafana 的 指标: PD -> Scheduler -> Scheduler is running
然后确认下 evict - leader - scheduler 是否正常
通过 pd-ctl config show all 确认下 evict - leader 的 tikv
xfworld
(魔幻之翼)
11
看你提供的图,leader 还在迁移呢,是不是数据量很大?那估计要等会
你想要加速,可以调高
leader-schedule-limit
max-pending-peer-count
观察下调整后的结果,最后迁移完了,记得还原就行
zzw6776
(bug发现者)
13
所有表加起来差不多2.几亿的数据把,我试下这两个参数,我奇怪地是如果是数据量的问题,为什么刚开始的时候迁移那么快
xfworld
(魔幻之翼)
14
这种情况,应该选择性的,先驱逐 要下线节点的所有的 leader,驱逐完了直接下线,这样就省了后面这种调度性的迁移
集群是线上生产环境么? 如果还有业务再跑,会有其他的调度和 迁移这块进行资源竞争
zzw6776
(bug发现者)
15
是的 线上生产环境 你的意思是指手动迁移leader 然后强制下线 直接不要这个tikv节点的数据了么
xfworld
(魔幻之翼)
16
不是,把这个要下线的节点的 leader 全部驱逐走,这个节点的就是标准的副本了,没有leader了
这样子下线,就不需要做leader 迁移了
做强制升级的时候,也可以考虑这种操作,这个官方文档上有介绍
xfworld
(魔幻之翼)
18
可以参考下
https://docs.pingcap.com/zh/tidb/stable/upgrade-tidb-using-tiup#42-升级过程中-evict-leader-等待时间过长如何跳过该步骤快速升级
zzw6776
(bug发现者)
19
总结下:
从之前的图表迁移很快,我猜测是因为有一堆空的region,所以那一部分迁移非常快,后面慢是因为有真实数据,开启空regionmerge后磁盘占用和region量明显降低
我所做的处理
1:开启空regionmerge
1.1设置
tikv:
coprocessor.split-region-on-table: false
1.2pd-ctl设置
pd-ctl config set max-merge-region-size 20
pd-ctl config set max-merge-region-keys 200000
pd-ctl config set merge-schedule-limit 8
//该参数不调整不会触发调整,原理未知
config set max-pending-peer-count 64
然后适当调小了部分参数,参数如下,具体是哪个参数起了效果…未知,反正现在是正常了
{
“replication”: {
“enable-placement-rules”: “true”,
“isolation-level”: “”,
“location-labels”: “”,
“max-replicas”: 3,
“strictly-match-label”: “false”
},
“schedule”: {
“enable-cross-table-merge”: “true”,
“enable-joint-consensus”: “true”,
“high-space-ratio”: 0.7,
“hot-region-cache-hits-threshold”: 3,
“hot-region-schedule-limit”: 4,
“leader-schedule-limit”: 16,
“leader-schedule-policy”: “count”,
“low-space-ratio”: 0.8,
“max-merge-region-keys”: 200000,
“max-merge-region-size”: 20,
“max-pending-peer-count”: 64,
“max-snapshot-count”: 16,
“max-store-down-time”: “30m0s”,
“merge-schedule-limit”: 8,
“patrol-region-interval”: “100ms”,
“region-schedule-limit”: 16,
“region-score-formula-version”: “v2”,
“replica-schedule-limit”: 16,
“split-merge-interval”: “1h0m0s”,
“tolerant-size-ratio”: 0
}
}
1 个赞
system
(system)
关闭
20
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。