设置过2个参数
set global tidb_analyze_version = 1
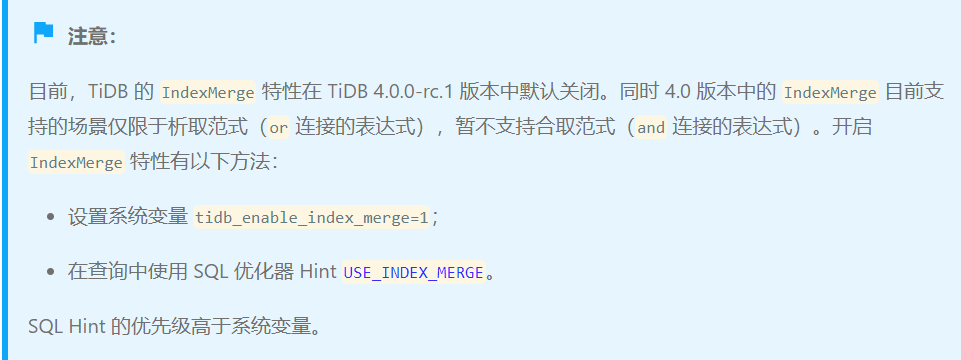
set global tidb_enable_index_merge = 1;
并且tidb和服务器都重启过
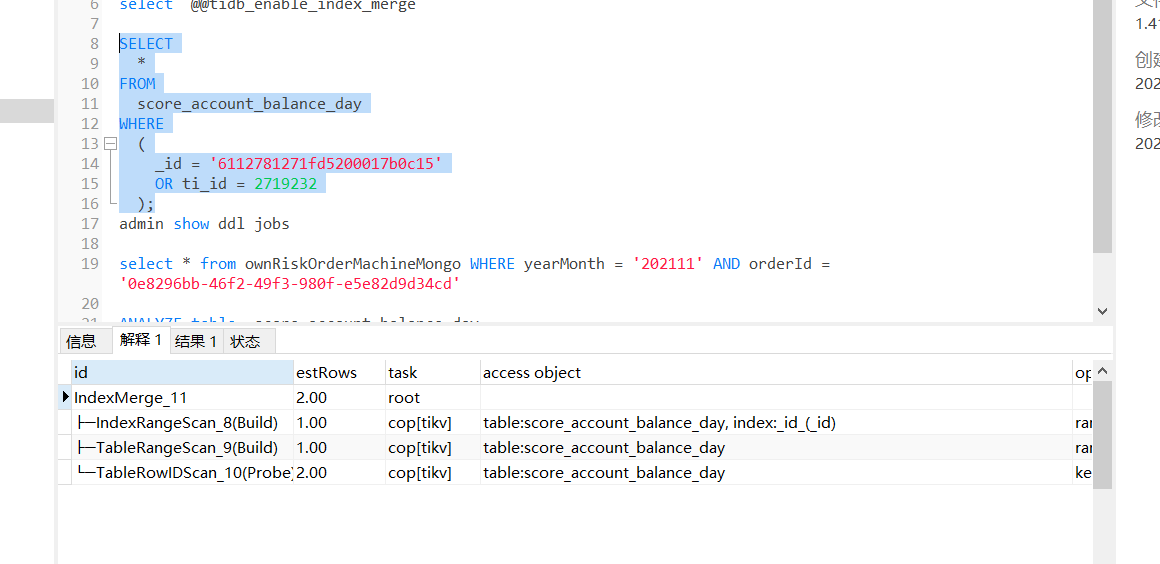
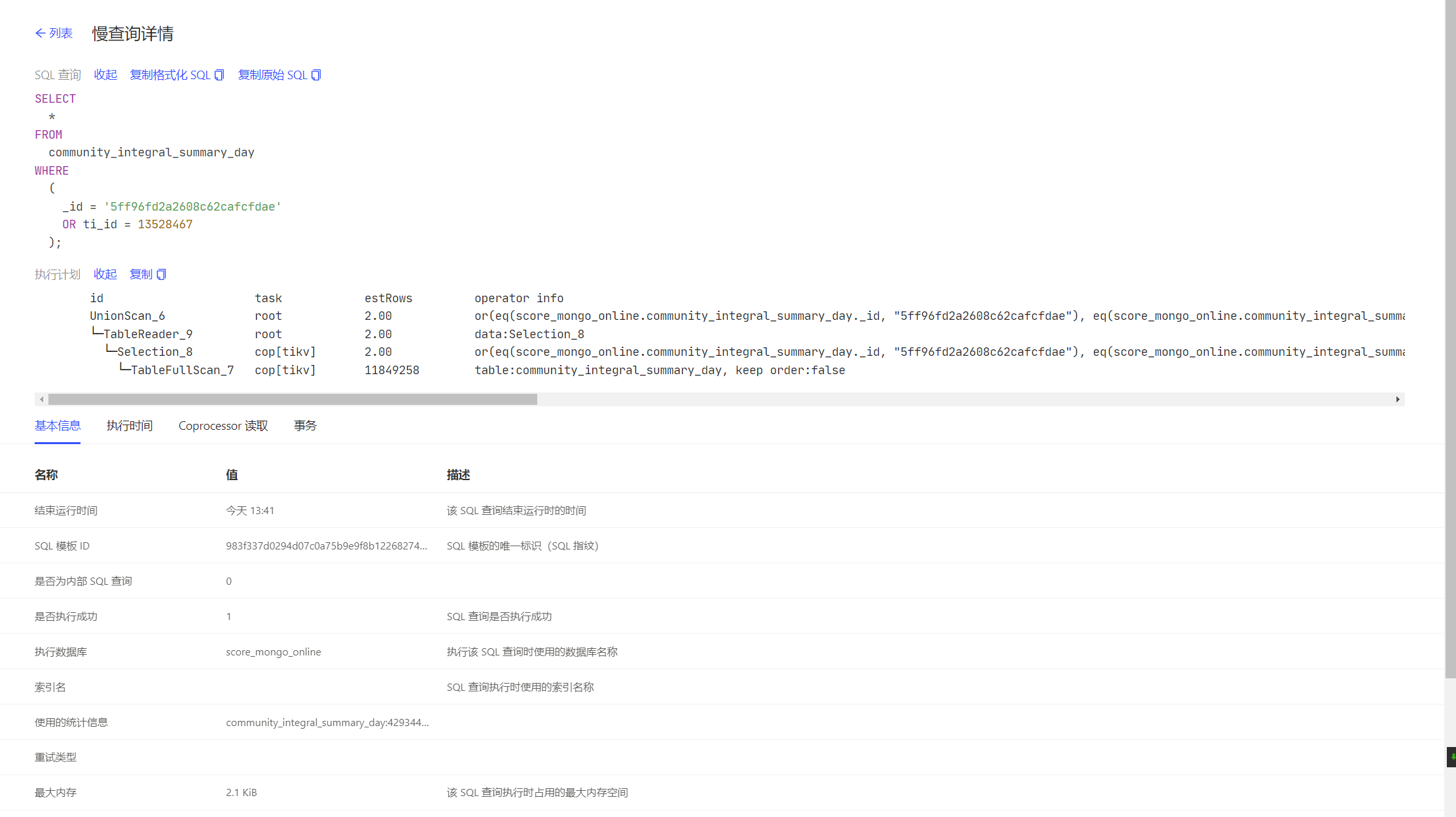
在navicat里执行以下sql
SELECT
*
FROM
score_account_balance_day
WHERE
(
_id = ‘6112781271fd5200017b0c15’
OR ti_id = 2719232
);
执行速度很快,并且能走上indexmerage,并且不会走到tiflash
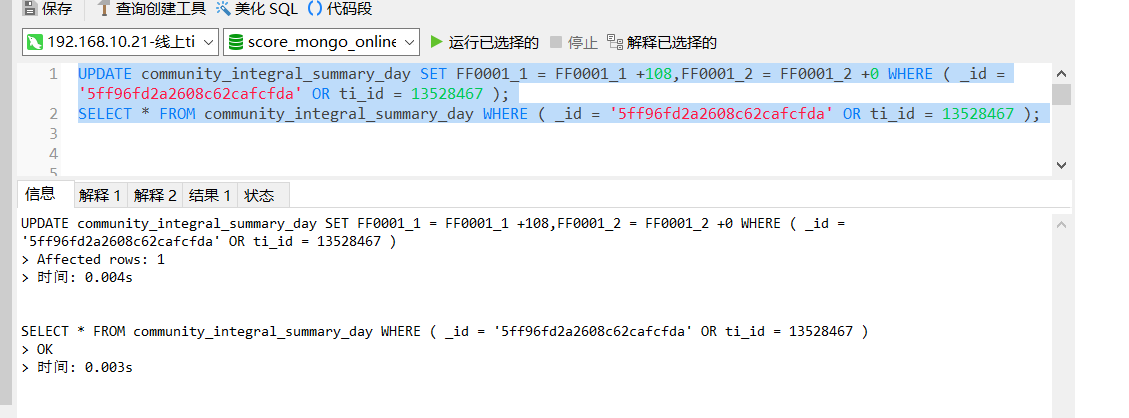
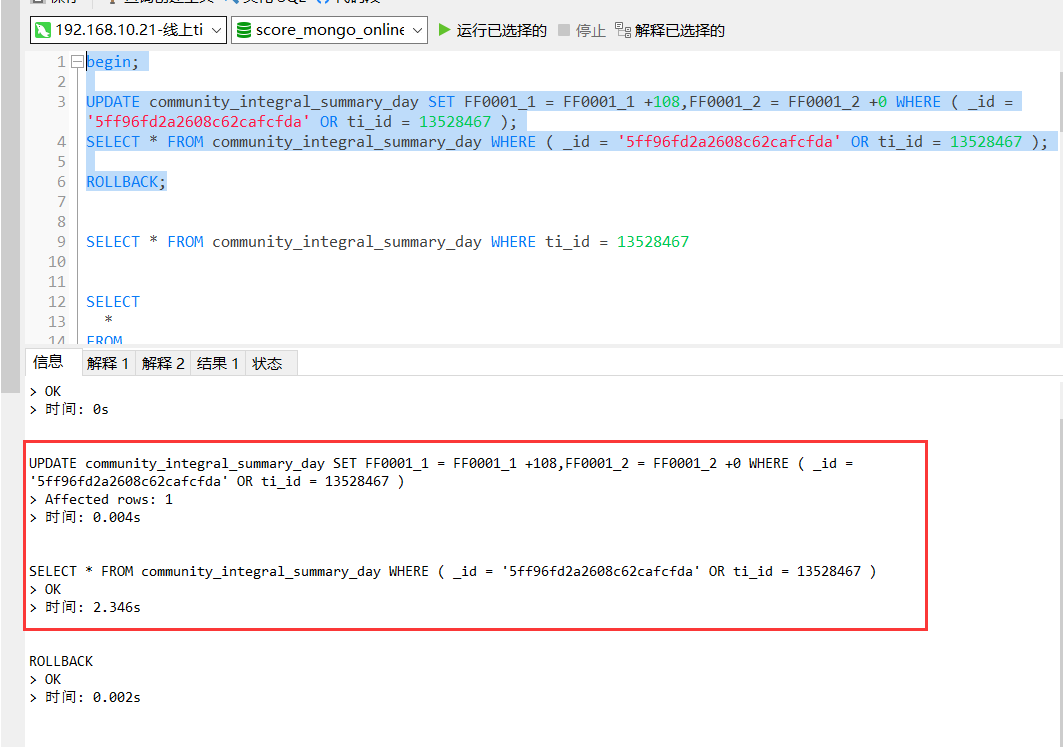
但是在java里执行时会有几率(刚重启完服务器测过,是能走上索引merge的,不知道触发了什么就不行了)先走tiflash,我把tiflash关了后(replace置为0)开始走全表扫描,还是没有走indexmerage,而且在这个情况下,几乎所有的同类型sql都无法走indexmerge,截图如下
现在 IndexMerge 不支持在有写操作的事务里面使用。 https://github.com/pingcap/tidb/pull/29875 所以当前这种暂时没法在事务里使用 indexmerge。
Problem Summary: We need UnionScan to read dirty buffer when we got write operation in transaction. But there is no implementation for IndexMergeReader to scan buffer. So we disable the usage of IndexMerge in this situation. So we need to implement memIndexMergeReader just like memIndexLookupReader