测试目的:在某个节点CPU负载较高的情况下集群稳定性
测试拓扑:三台机器,每台1个tikv-server节点,pd-server单独部署
测试过程:
1、go-ycsb工具写入初始数据
2、服务器CPU无特殊负载情况下读已经写入的数据(go-ycsb工具)
3、某个节点使用stress工具占用大部分CPU资源,读已经写入的数据(go-ycsb工具)
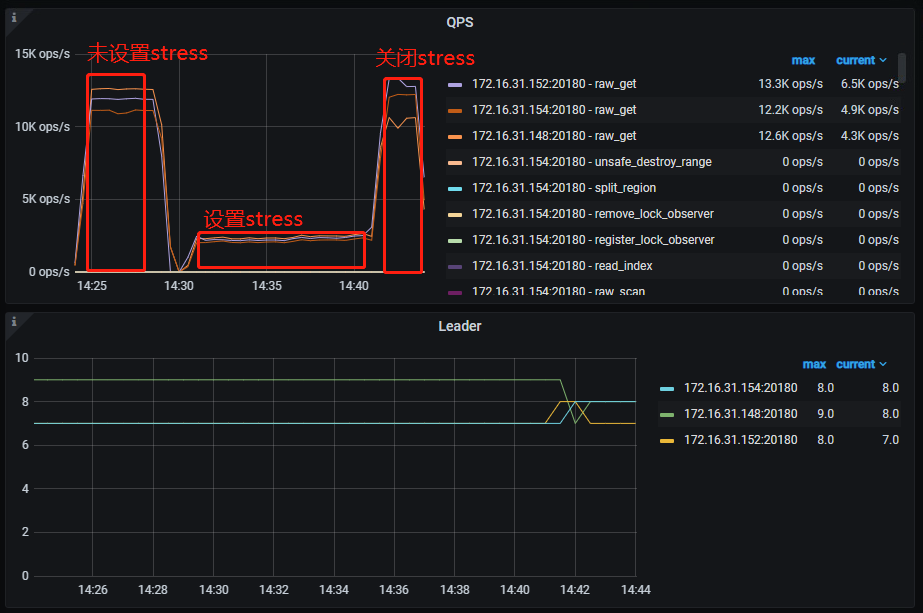
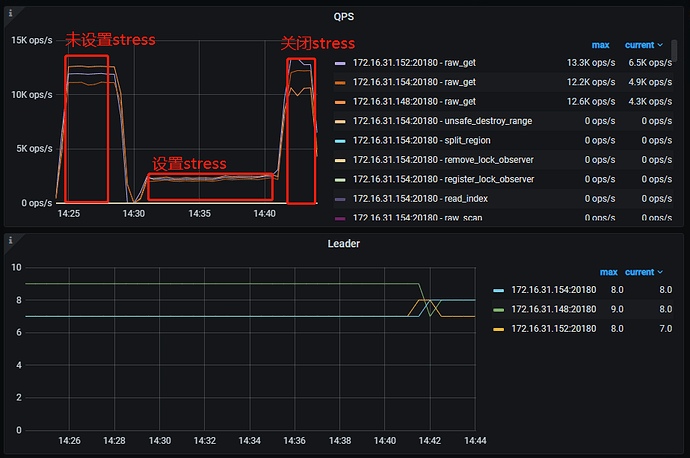
前后QPS对比,发现集群CPU空闲情况下集群比CPU繁忙情况下的QPS高很多,按自己理解:某个节点CPU高,这个节点上的region读请求慢是正常的,不应该影响其他节点的读,实际测试结果是某个节点CPU资源不足,直接影响了当前整个集群的请求,是我理解错了吗,读操作和整个peer节点都有关系?还是集群配置有问题?
CPU无压力QPS:
stress加压QPS:
1 个赞
听风吹雨
(听风吹雨)
6
1、TiDB集群某节点CPU高了,慢了是有可能影响到整个集群的吞吐的。
2、某个节点上TiKV CPU高了,那么你的读如果有需要读到这台压力大上面的Leader Region,一样需要等待这个返回的,所以整体的性能会降低。
3、可以通过查看监控,排查下现在的瓶颈出现在哪里。
CPU高的那个节点慢是能理解的,我主要的疑问是,这台慢了,其他CPU正常的节点从QPS上看感觉也变慢了,按region的leader分别来说,CPU繁忙的点占1/3,总体QPS是不是最多降1/3?
听风吹雨
(听风吹雨)
8
并不完全是的:
1、要看你在这台机器上Region leader是否只占用了1/3
2、而且即使是占用了1/3,还得根据你这些QPS是否有请求到这台机器的Leader,是否有热点打到这些Region
3、而且这是一个整体的系统,某些节点慢可能触发流控的。
所以不能简单这么计算,应该分析下这个节点为什么,进行优化。
嗯嗯,看监控leader差不多是1/3,我测试是故意让一个点CPU繁忙,被流控了有监控可以看吗?
听风吹雨
(听风吹雨)
11
我主要是想理解,为什么一个节点的CPU繁忙,会导致整个集群的QPS慢下来,从图可以看到,设置了某个节点CPU被打满,另外2个节点的QPS也下降了,测试是只读哦,应该不涉及raft的3副本过程,望大佬指正:pray:。
spc_monkey
(carry@pingcap.com)
13
一般不会,但遇到锁冲突/或 pd 资源高,会导致 tso duration 时间较长时,会影响全局
看你的截图,是某台tikv的cpu高。
个人理解,针对某次查询,算子会下到tikv,再在tidb汇总,如果某个tikv慢,整个查询都会慢
system
(system)
关闭
16
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。