kimi
(kimi)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】场景+问题概述
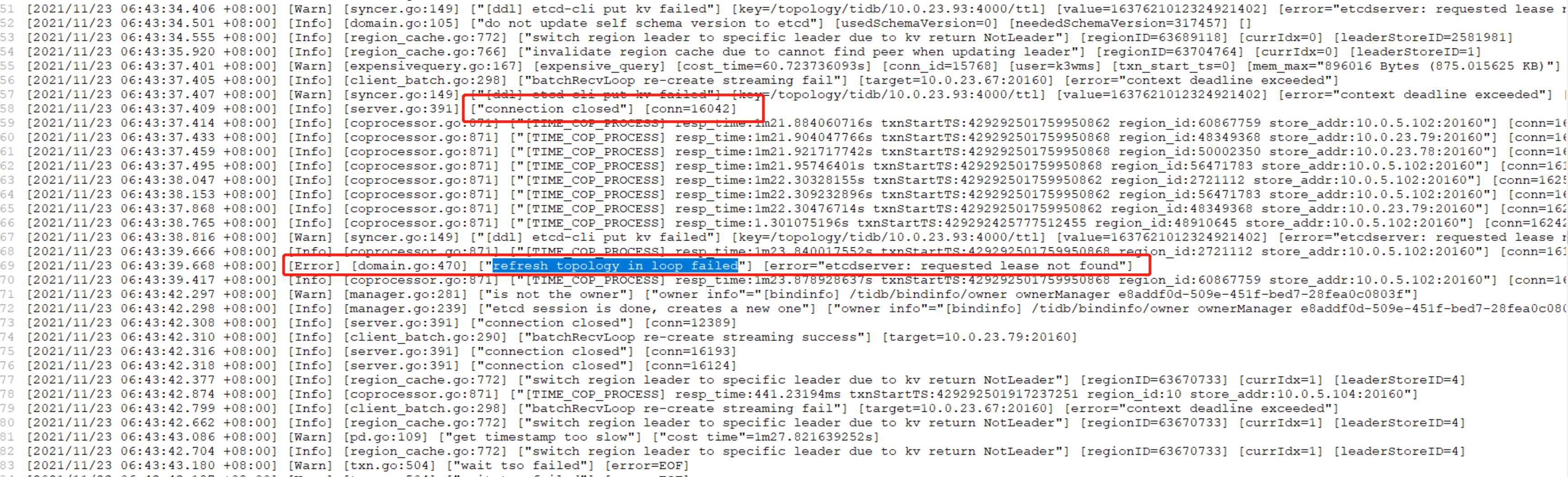
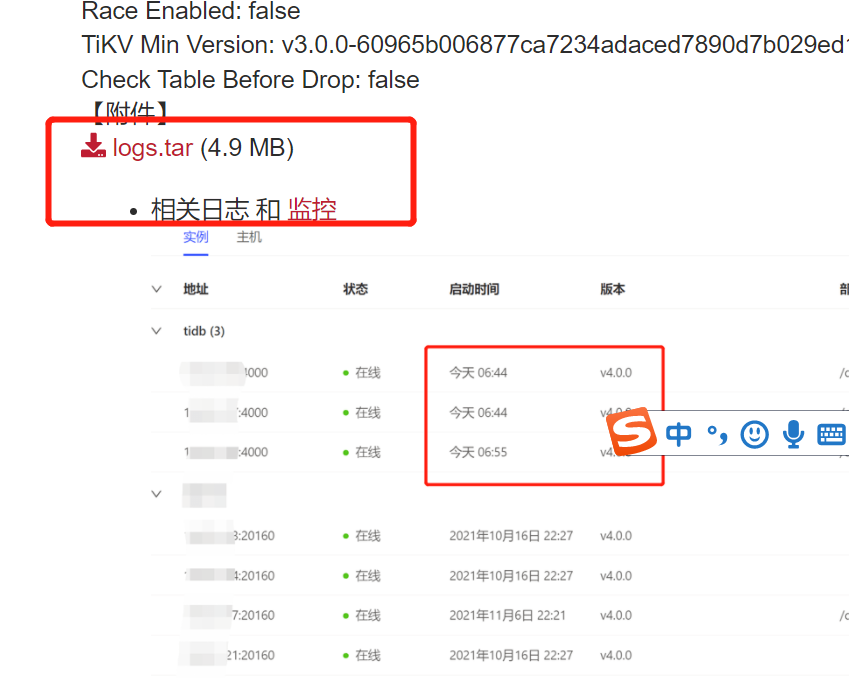
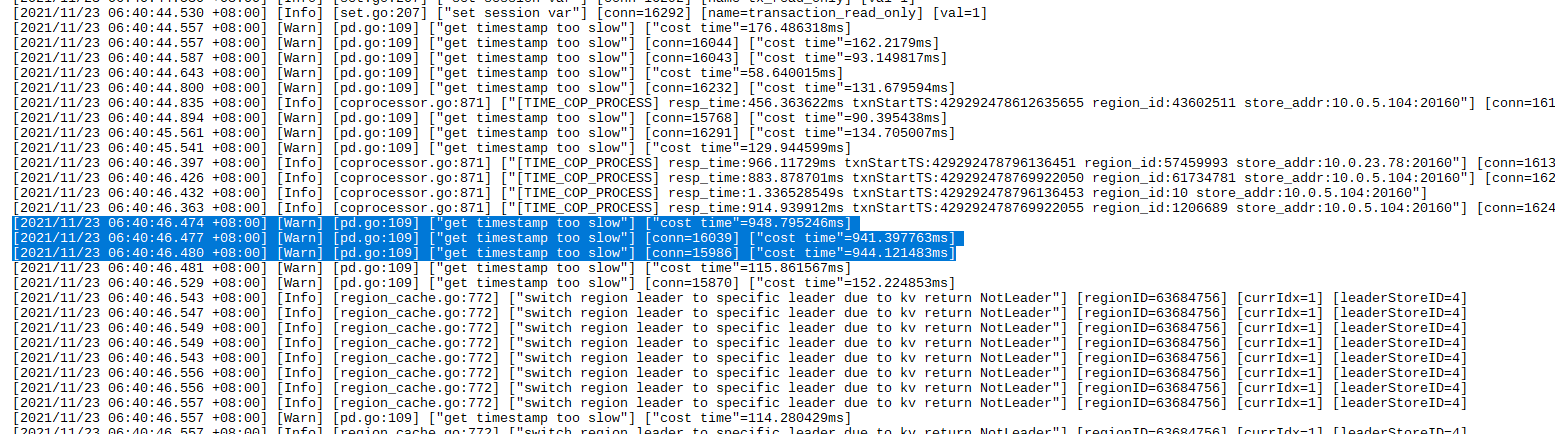
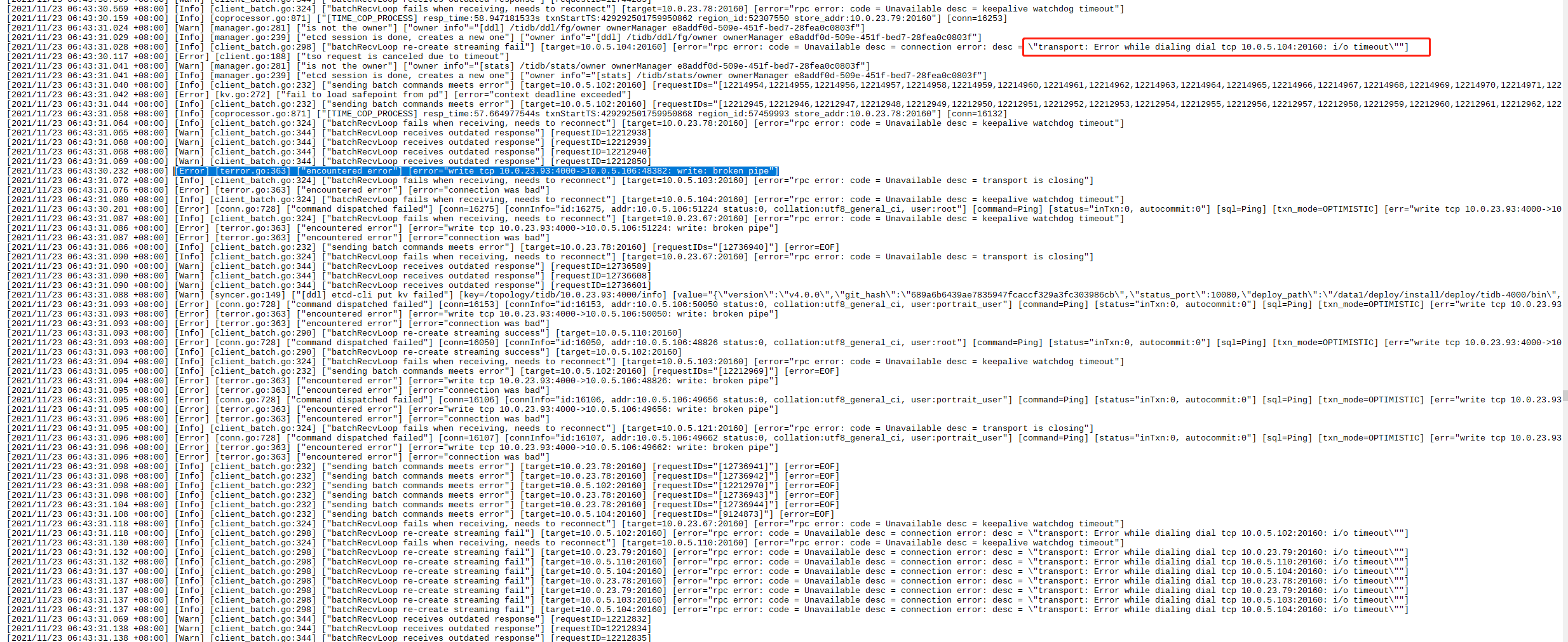
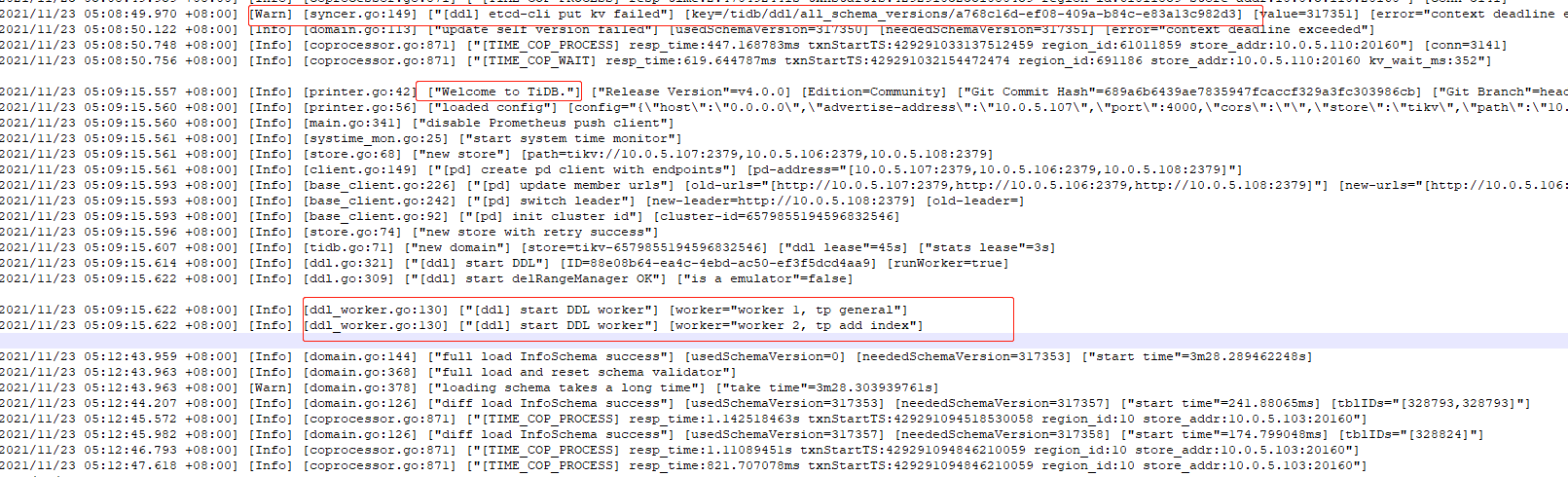
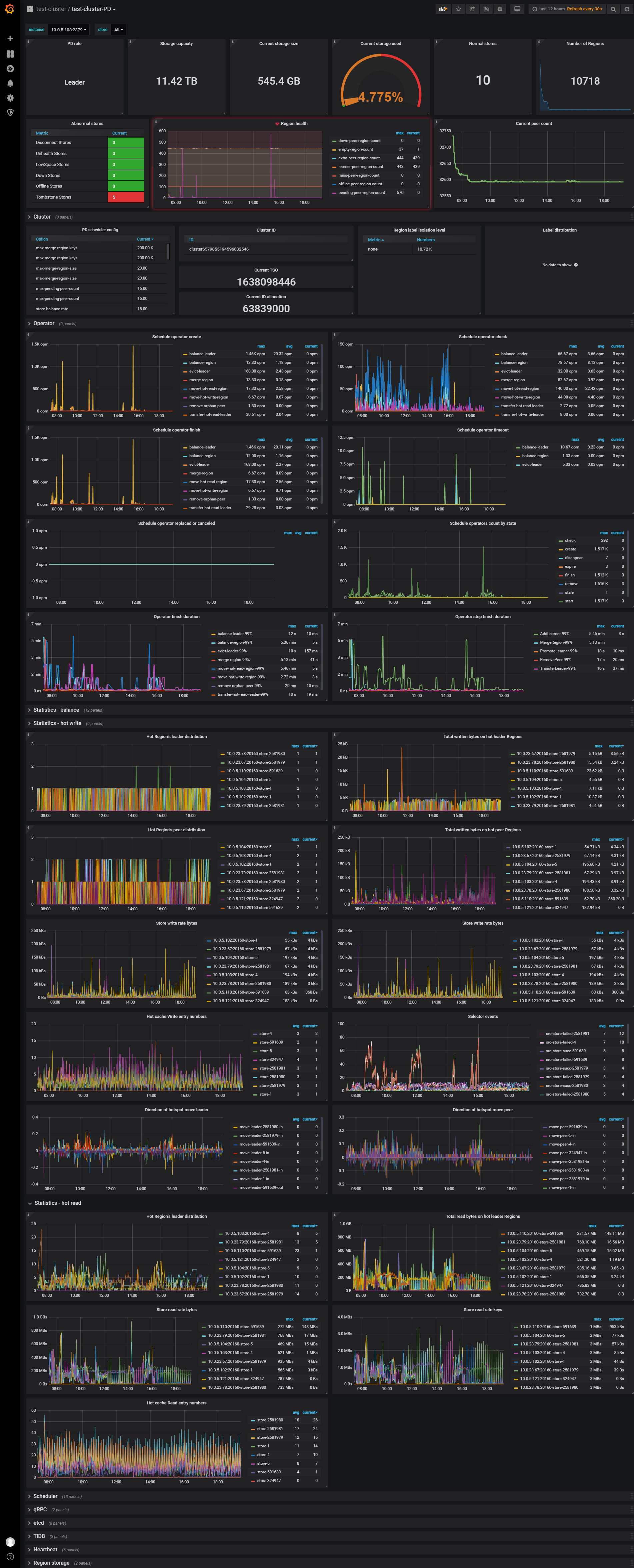
凌晨tidb-server 经常会自动重启,从dashboard上发现是6:44左右重启了,我从dashboard上下载了日志,链接是关闭了,这期间有其他工具或代码在访问,发现连接不上了
【背景】做过哪些操作
【现象】业务和数据库现象
【业务影响】
【TiDB 版本】
Release Version: v4.0.0
Edition: Community
Git Commit Hash: 689a6b6439ae7835947fcaccf329a3fc303986cb
Git Branch: heads/refs/tags/v4.0.0
UTC Build Time: 2020-05-28 01:37:40
GoVersion: go1.13
Race Enabled: false
TiKV Min Version: v3.0.0-60965b006877ca7234adaced7890d7b029ed1306
Check Table Before Drop: false
【附件】
logs.tar (4.9 MB)
-
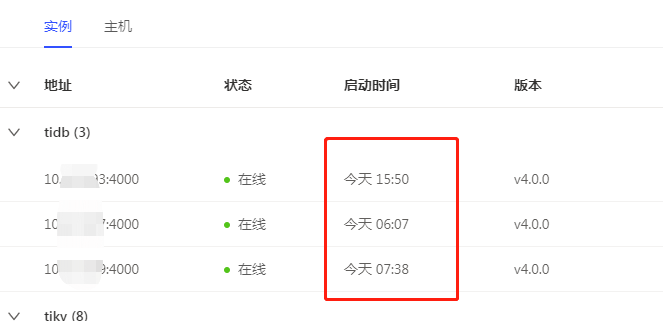
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
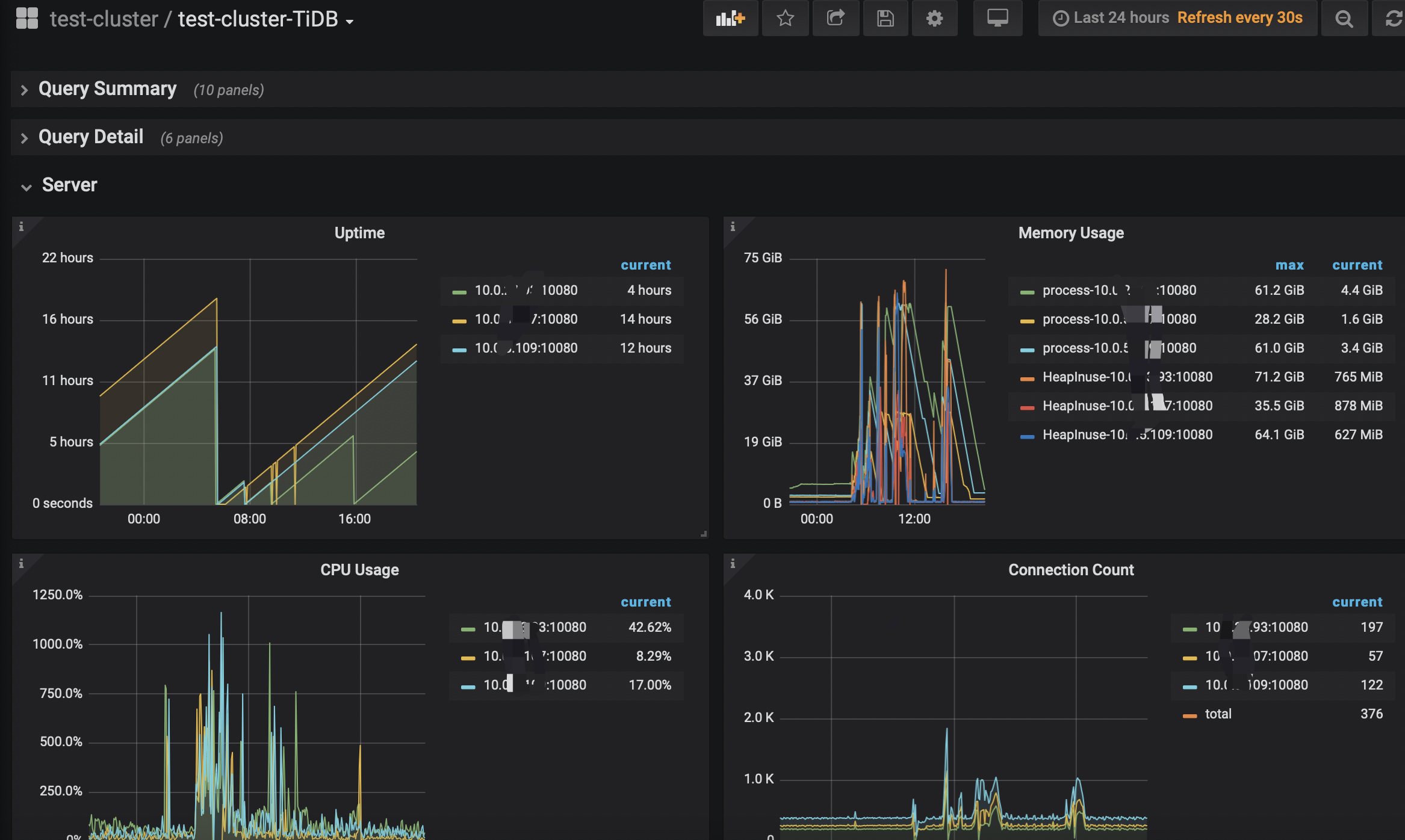
TiDB- Overview 监控
xfworld
(魔幻之翼)
2
你可以看看 10.0.23.93 这个tidb 的日志么?
就发生问题这段时间的日志
kimi
(kimi)
9
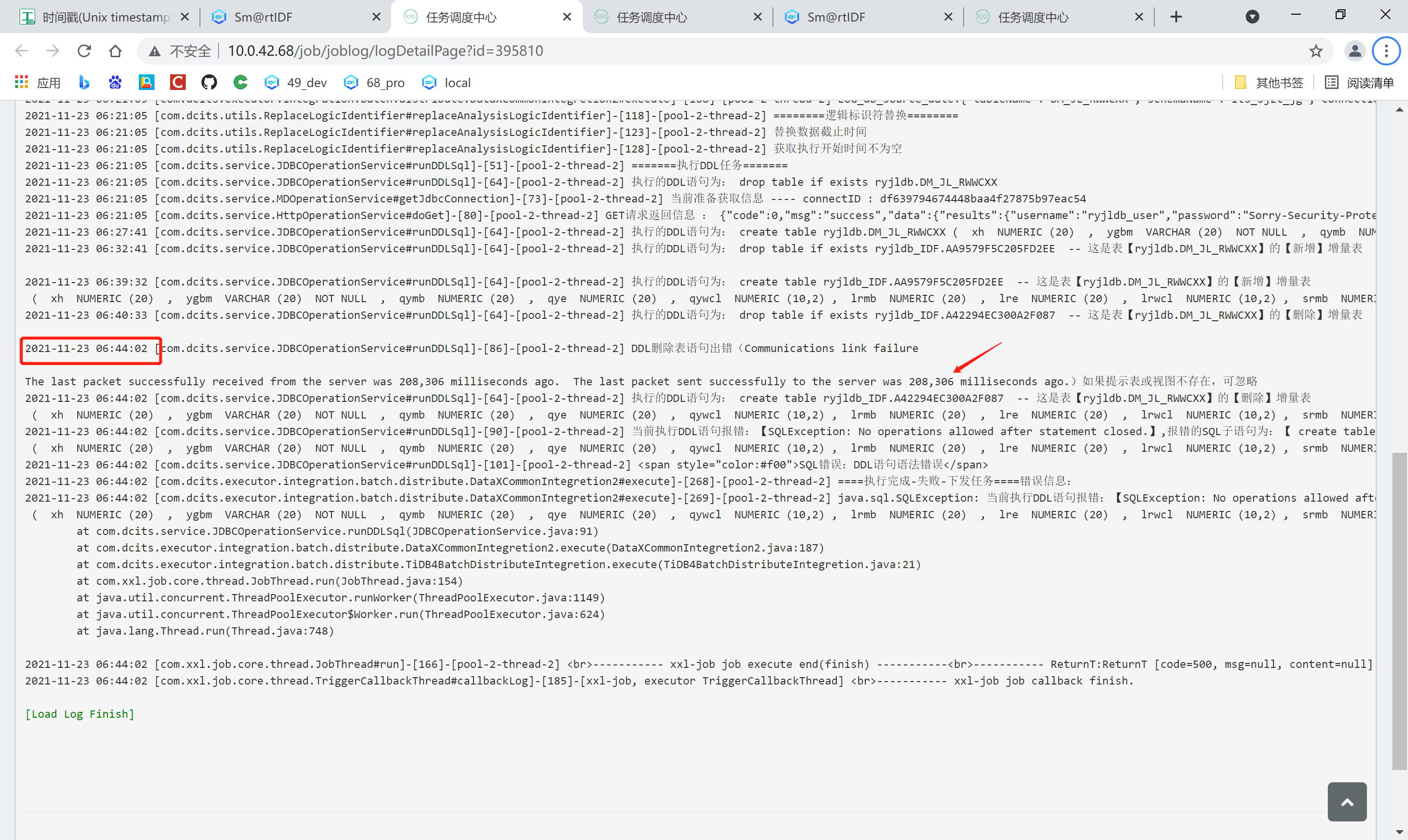
又出现了,大神帮忙看看logs.tar (7.2 MB)
应用那边有批量的drop表重建表的动作
Meditator
(Wendywong020)
10
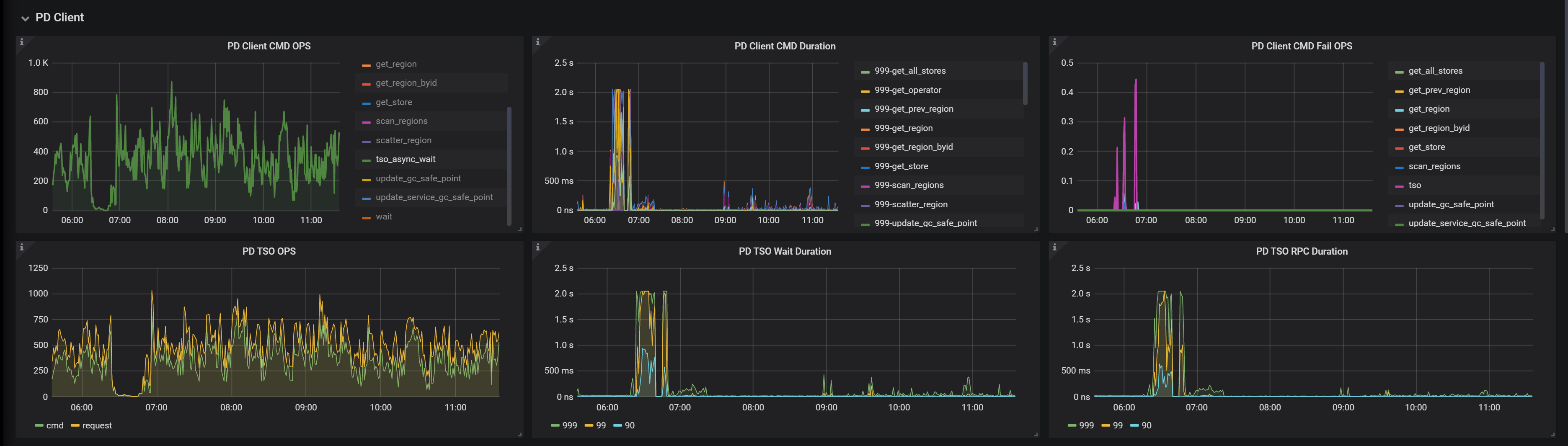
要发下对应时间段pd的日志,目前看是跟pd失联导致。
然后发下grafana上pd的监控面板信息。
听风吹雨
(听风吹雨)
11
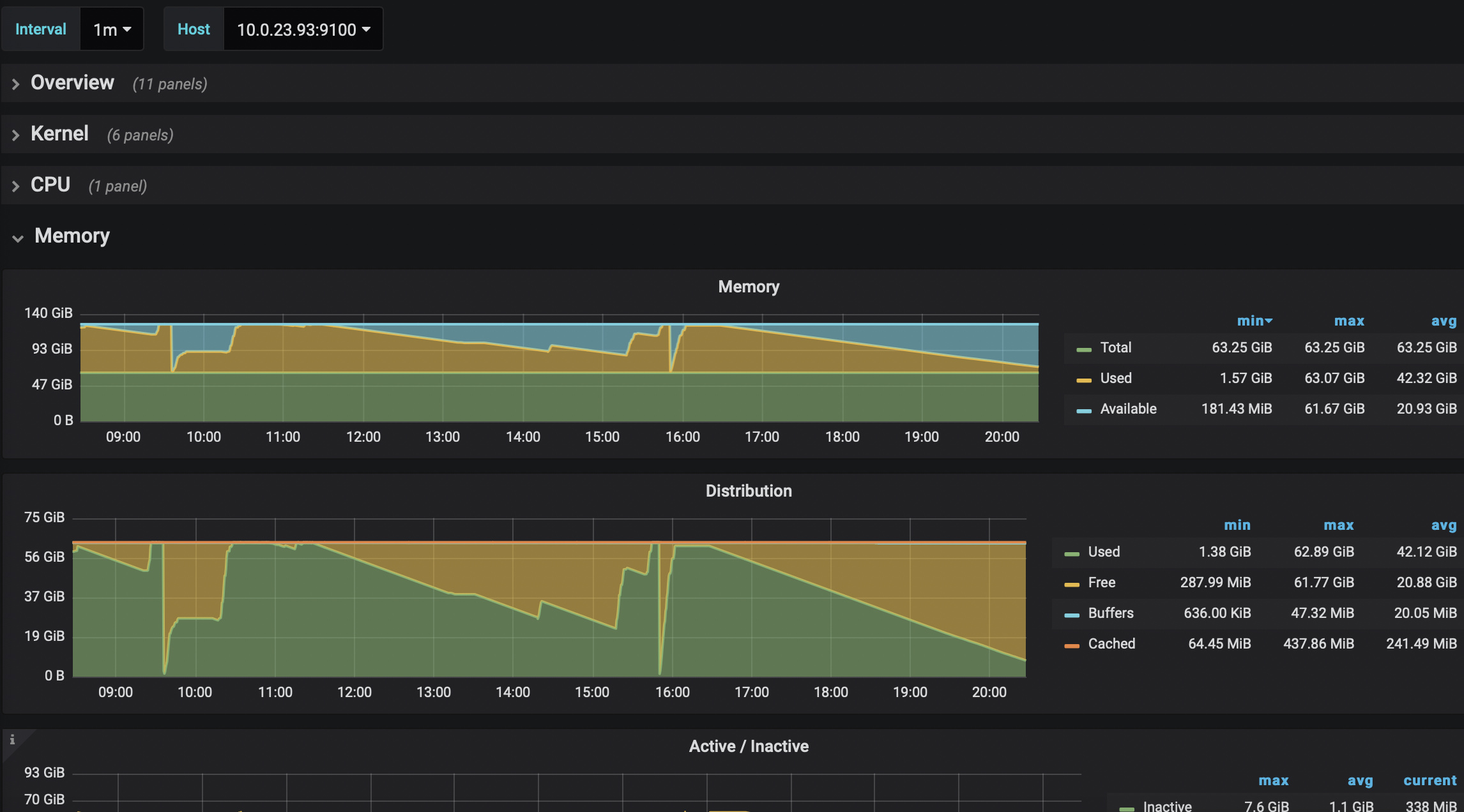
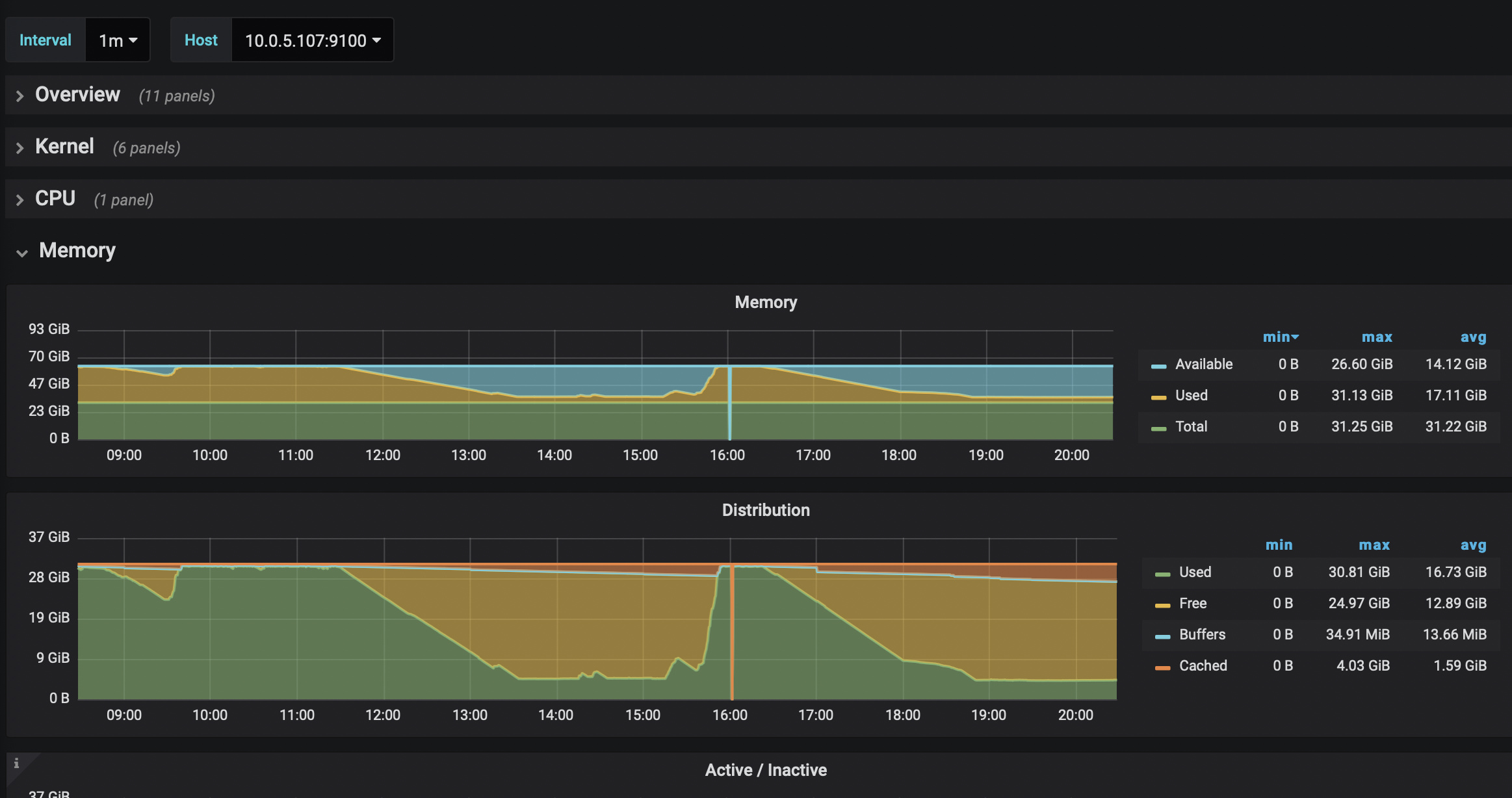
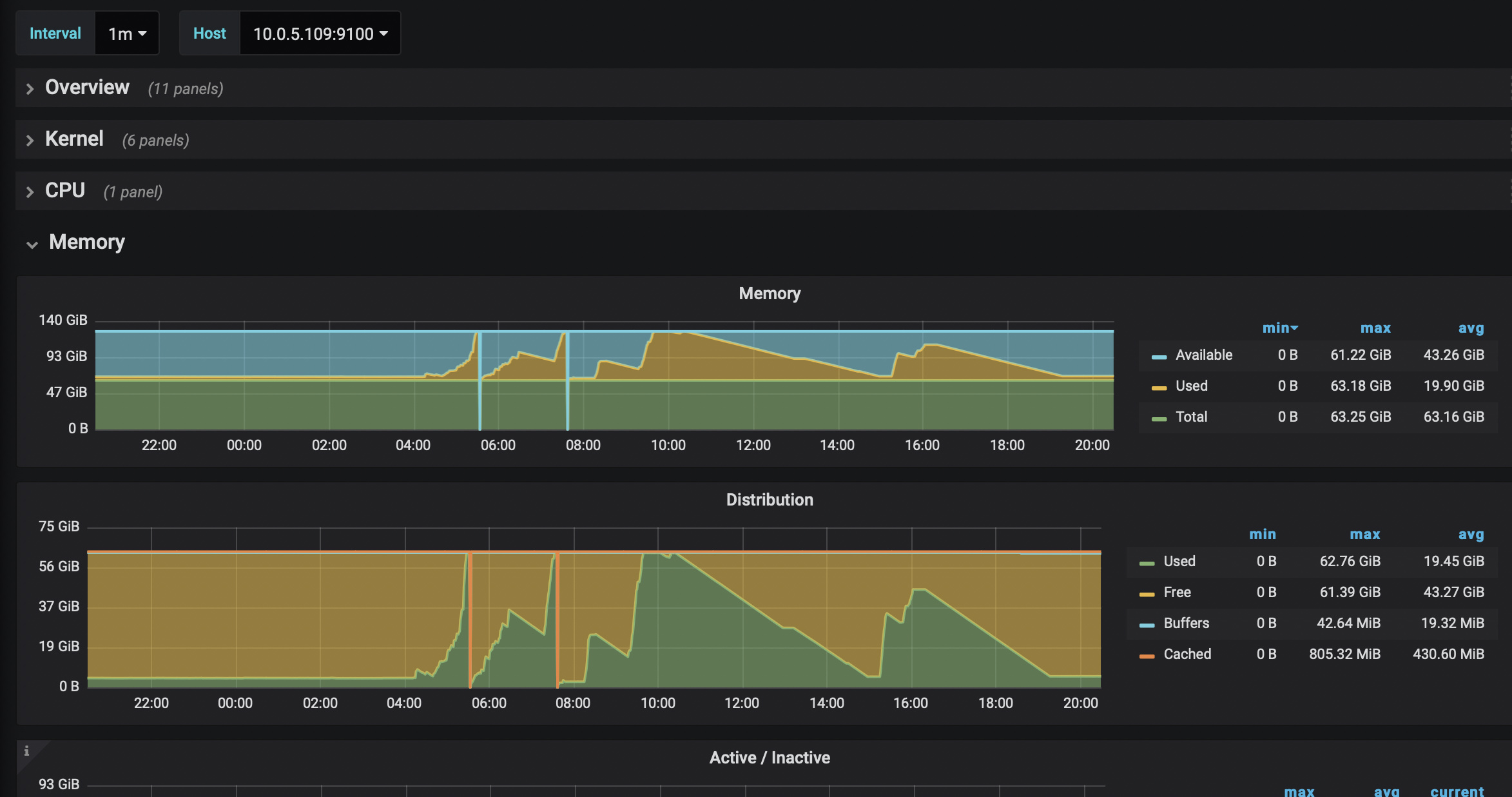
1、查看下TiDB-Server是不是OOM了?
2、查看下TiDB-Server的监控内存
kimi
(kimi)
12
logs (1).tar (9.8 MB)
目前有一台机器pd和tidb-server在同一台机器上部署着
kimi
(kimi)
16
有两个tidb-server是64G,一个是32G还tidb-server和pd在一台部署的,今天准备把这个分开
托马斯滑板鞋
(托马斯滑板鞋)
17
看看tidb_stderr.log里有没有oom的报错
听风吹雨
(听风吹雨)
18
kimi
(kimi)
19
logs.tar (3.9 MB)
昨天从新扩容了一台tidb-server,把另一台和pd部署在一起的下线了,问题依旧
system
(system)
关闭
20
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。