【概述】 使用TiCDC同步数据到MySQL。
相关配置(cdc-report-task.toml):
case-sensitive = false
enable-old-value = true
force-replicate = true
[filter]
rules = [‘report_center.*’]
[cyclic-replication]
sync-ddl = true
启动:
tiup ctl:v5.2.2 cdc changefeed create --pd=http://172.20.31.14:2379 --sink-uri=“mysql://ticdc:ticdc123@172.20.31.13:15381/?worker-count=64&max-txn-row=100000” --changefeed-id=“cdc-report-task” --sort-engine=“unified” --config cdc-report-task.toml
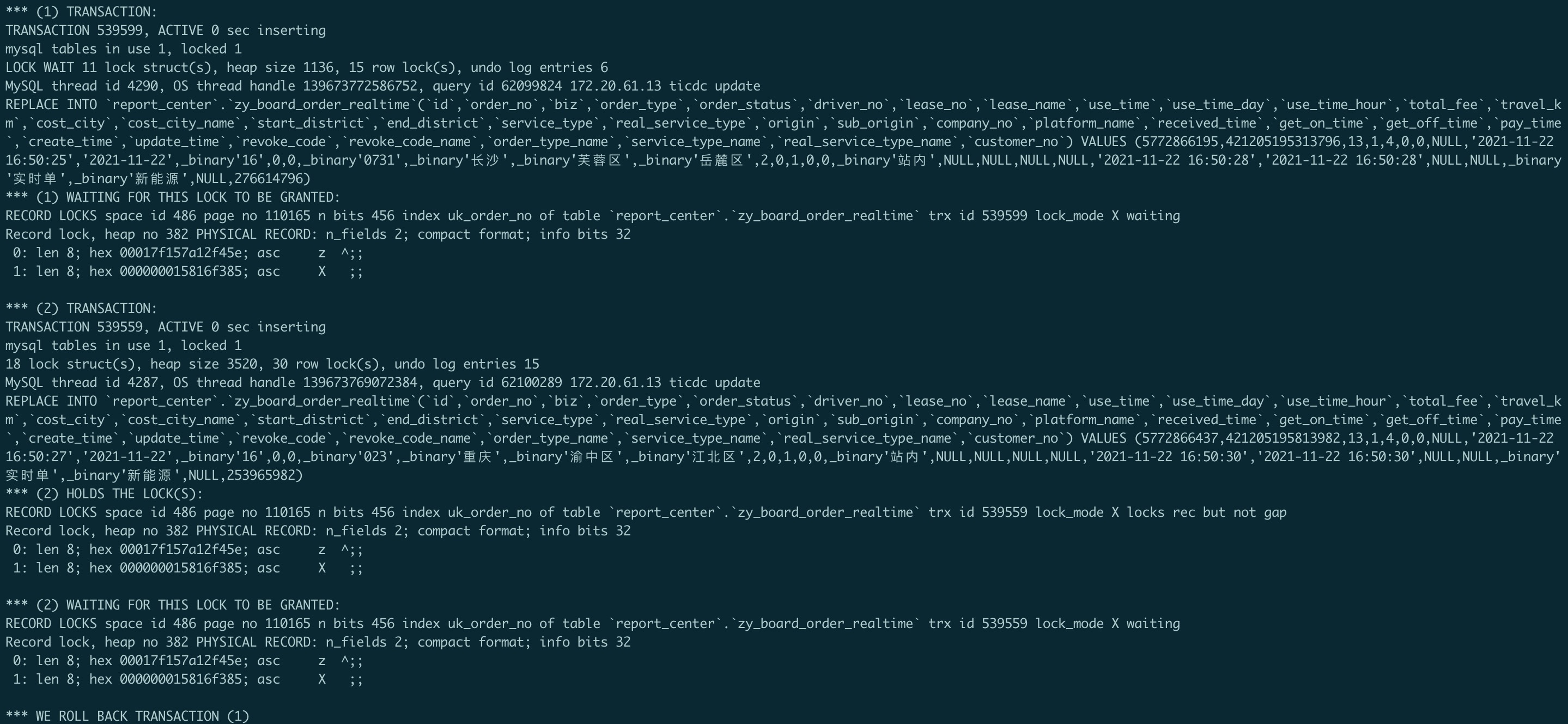
【问题】 同步出现死锁,如图:
出现死锁的原因是mysql中replace into并发高时会引起死锁,worker-count改为1后恢复正常
ticdc日志:ticdc.log (3.7 MB)
问题:
由于mysql中replace into在高并发时会出现死锁,导致同步变慢,ticdc有没有配置项可以改变replace into的行为,比如改为into ignore into…;同样也会出现其他语句的死锁。
【TiDB 版本】
TiDB v5.2.2、MySQL 5.7.20
听风吹雨
(听风吹雨)
2
麻烦查看下下游的MySQL的innodb_autoinc_lock_mode参数是什么值?可以尝试设置innodb_autoinc_lock_mode = 2是否有帮助。可以查看下innodb_autoinc_lock_mode参数的使用注意事项。
听风吹雨
(听风吹雨)
3
TiDB与MySQL的表结构是否有区别?需要提供表结构
听风吹雨
(听风吹雨)
7
1、产生的数据中order_no大部分都是递增是吧?
2、max-txn-row可以调小一些试试。比如5000、10000
order_no是生成器生成的;调小也是会出现的,只有 worker-count改为1才不会出现死锁;
死锁出现的根本原因是多个事务对order_no加锁顺序不一致导致的,这个你们有办法解决吗?不然只有把worker-count改为1了,不过同步效率比较低,大概率会出现延迟
1 个赞
liuzix
(Liuzix (PingCAP))
9
可以试一下把隔离级别调成 read committed
没有用,一样出现, worker-count只要大于1就会出现死锁,越大出现死锁的概率越大
HHHHHHULK
(好好学习,天天向上)
11
是有死锁这个问题。不过因为我们下游不需要查询,所以会把下游mysql表中唯一索引删了
neilshen
(Neil Shen)
12
请问下在使用 TiCDC 同步前下游出现 deadlock 的表是否已存在数据?
neilshen
(Neil Shen)
14
最近内部测试发现当下游 MySQL 存在数据时,TiCDC 多线程同步可能会使 MySQL 产生 deadlock。
比如用 tiup bench tpcc 同时向上游 TiDB 和下游 MySQL 灌入数据,然后再用 TiCDC 将上游 TiDB 的数据同步到下游,同步过程中可能会遇到 Deadlock 报错。
同样的,如果用 TiCDC 反复同步同一批数据到 MySQL 也有可能产生 Deadlock。
具体原因还在调查中。
@Haaahei,您好,您这边可否提供一下死锁信息的文本日志,我们这边尝试复现一下
感觉 @Haaahei 说的情况类似于 MTS 并行复制引发的死锁类似, 前段时间我也在排查类似该方向的问题。有一些参考资料您可以参考下。
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import time
import pymysql
mgr1conf ={
"host": "xxxxxx",
"user": "gyz",
"password": "123456",
"db": "gyz",
"port": xxxx
}
def connDb(sql, dbconf=mgr1conf,fetchopt="all"):
try:
conn = pymysql.connect(**dbconf)
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql)
if fetchopt == "all":
res = cursor.fetchall()
elif fetchopt == "one":
res = cursor.fetchone()
conn.commit()
cursor.close()
conn.close()
return res
except Exception, e:
print(e)
return e
while 1:
for i in range(1,101):
sql = "replace into t1(col1) values('col{0}');".format(i)
connDb(sql)
表结构
CREATE TABLE `t1` (
`id` int NOT NULL AUTO_INCREMENT COMMENT 'ID',
`col1` varchar(100) NOT NULL DEFAULT '' COMMENT 'col1',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_col1` (`col1`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='test1'
您可以尝试在上游创建相应表结构,然后用脚本压测时,在下游 TiCDC的表现
3 个赞
目前我们的解决方式是以表为单位将同步拆分为多个changefeed任务并将 worker-count设置1,来避免死锁,而且可以达到多线程并发的效果。不过有个问题需要注意即:如果数据变更集中在某张表上,那么这个拆分的意义不大。
1 个赞
MSGJC
19
问题解决了吗,按你现在的方式,上千张表,不就GG了