tikv集群缩容,直接kill了进程,发现stores API发现一直还有(状态是down),再通过pd api delete节点之后节点处于offline。
现在想恢复节点,重新将节点启动后,还是一直保持offline,如何恢复成up?
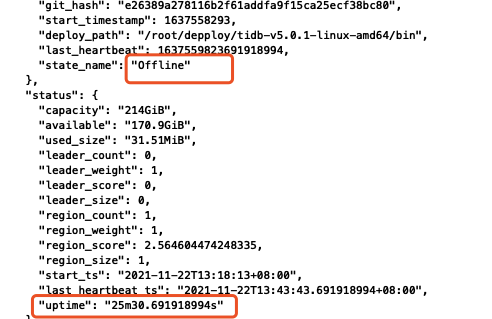
tikv集群缩容,直接kill了进程,发现stores API发现一直还有(状态是down),再通过pd api delete节点之后节点处于offline。
现在想恢复节点,重新将节点启动后,还是一直保持offline,如何恢复成up?
现在这个offline状态的store上的region已经前迁移完成,推荐用scale-in、scale-out方式来进行恢复
1)tiup cluster scale-in cluster_name -N ip:port --force
2)tiup clsuter prune cluster_name
3) tiup cluster scale-out cluster_name yyy.yaml
其中yyy.yaml文件为新扩的节点信息
tikv_servers:
请问下原生API呢,由于没有外网,没有使用tiup做部署~
正常你这种情况是可以这个store是可以变成 tombstone状态的
登录pd-ctl
store delete {store_id}
store {store_id} #查看store状态
之前就是这么操作的,不过我是先kill了进程,然后再 store delete,这样会有问题吗?还是直接使用delete API?
直接用api 来delete store操作

还有一个region没有迁移走
region store {store_id}
看看剩下的region peer 为什么没有迁移走
建议剔除节点重新扩容
看起来是因为节点数量原因,我只有三个节点,数据总共也是3个副本,我多起一个节点之后,那个老的节点就改状态了(没有执行delete API)
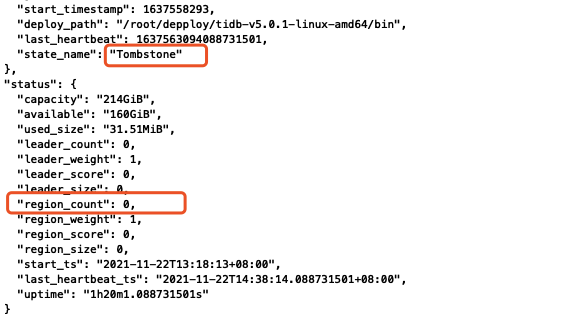
还有两个疑问请教一下:
1.Tombstone 这个是最终状态吗?到了这个状态是不是就算是下线完成了,不需要做其他的了?
2.我把进程kill,状态变成down,然后delete,状态变成offline,再把进程启起来,这个节点依然处于offline(由于还有region),这个起来的异常进程是能提供服务的吗?到底是个什么状态呢
刚刚的问题就是剔除不了~一直offline,然后写了个测试程序,会报错,现实找不到leader;
在老节点在起来,状态还是offline,但是测试程序已经可以跑通了
如果是三个tikv,replica为3,这样在挂一个tikv的情况下,是不会做region迁移调度的,但是此时不影响集群的可用性。但是需要再补一个tikv,down掉的tikv上的region才会调度走,down掉的store才能正常下线。
1)tombstone是最终状态,下线完成;
2)理论上offline状态的store 并且leader_region count为0,都是可以对外提供服务的;
至于store的down、offline、tombstone几个状态关系,可以参考这里 [FAQ] TiKV 各状态 Up/Offline/Down/Tombstone/Disconnect 的关系
感谢支持~
还有两点请教下~
1.pd/delete store API 到底做了什么事情,比如我下次下线节点,直接使用delete API,发现节点数量问题无法迁移region,这样执行delete API是执行失败?还是做了其他的动作,比如先杀死进程,然后维持offline状态等待被迁移…
2.理论上offline状态的store 并且leader_region count为0,都是可以对外提供服务的;
这句话有点没懂,节点offline了(进程没有死),该节点没有leader region,那怎么提供服务呢,tikv的读写好像都在leader上…
1)我的理解,delete store api 只是标记store状态,触发调度。
如果是正常的机器故障导致tikv失联,会经过up–》disconnected–》offline这些过程,其中offline阶段是leader和replica调度;
如果是api delete store,则进入offline状态,直接进行leader和replica调度;
2)上面说的可能有点歧义,虽然这个store 是offline状态,并且leader count为0,此时集群有效store数满足(2n+1)/2个,整个集群还是可以对外正常提供服务的。不是offline的store对外提供服务。
好的,了解了,感谢~~
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。