你好,如果我再添加两个800G的TiKV节点,会自动把216的数据均摊到新节点上吗?
会的,可以看看grafana里balance的速度
话说只剩一个tikv,你的集群应该hang住了吧?(不能写数据)
只一个tikv不行的啊,3副本丢2副本岂不是不能用了。
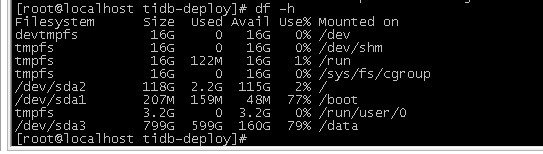
加完两个节点后,216的数据开始往其他TiKV节点上漂移了,刚才是100%,现在是79%
1 个赞
计划的是3个TIKV节点,11号挂了一个,剩余2个节点时还可以使用TIDB,现在剩下1个节点了,还是可以连接上TIDB,但没有数据了,刚才增加了2两TIKV节点,等一会看看数据会不会回来……
缩容后,再扩容,提示 :Error: port conflict for ‘20160’ between ‘tikv_servers:192.168.0.214.port’ and ‘tikv_servers:192.168.0.214.port’
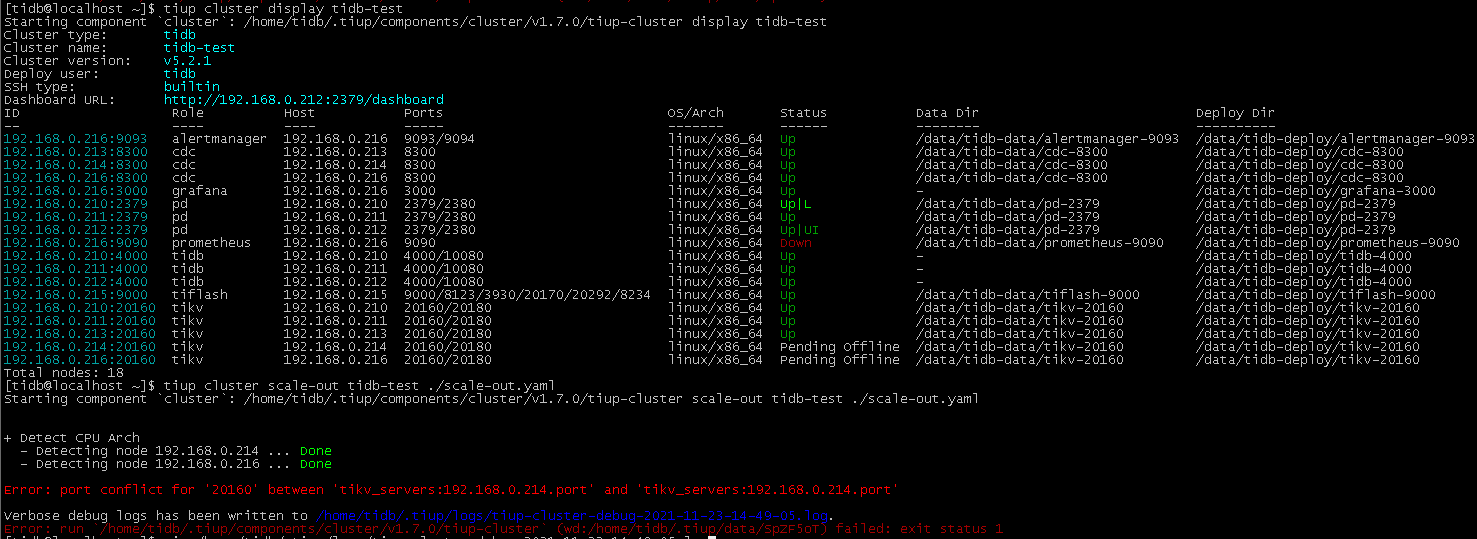
原来挂掉的2个tikv得起来一个,否则只靠一个跑着的tikv不能正常工作,额外扩两个也不行。除非通过故障恢复手段恢复。
1 个赞
贴下你的扩容的yaml文件内容
[tidb@localhost ~]$ cat scale-out.yaml
tikv_servers:
- host: 192.168.0.214
- host: 192.168.0.216
你刚刚缩容是不是一次性删了两个?![]()
没有,我去缩容214的时候,我先查了一下,集群状态: tiup cluster display tidb-test,发现216也down了,能连上TIDB,没有数据,然后缩容214和216 -> 扩容210和211(正常扩容) -> 发现216的磁盘从100%下降上82% -> 再扩容214和216,就出现现在这个局面了,目前214和216的状态显示:Pending Offline
我找到了一篇文章:TIKV扩容失败 和我的情况类似,我先试试……
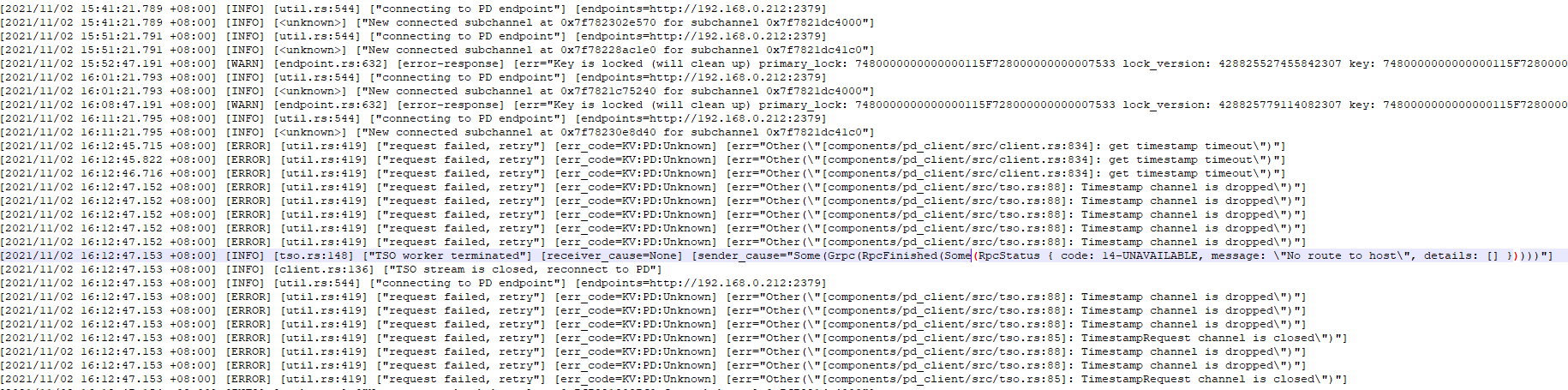
现在你这个集群需要unsafe修复,会丢数据,可以参考:
https://asktug.com/t/topic/183387
1 个赞
11月2号,做写压测,那天有1台TIKV压down了,记不清是哪台了,压测结束后执行了:tiup cluster reload tidb-test 又恢复服务了
步骤反了,应该是先扩再缩或者是只缩一个再扩再缩;
因为你先缩两个可能导致副本丢失(按理说3节点只剩两个的情况下,不应该缩容成功,bug?![]() )
)
2 个赞
3个TiKV节点,损坏了2个,感觉恢复的意义不大,最终让“tiup cluster destroy tidb-test”扛下了一切,多亏是测试数据,重新安装了TiDB集群,这次搞了5个TiKV节点,测试了200W数据,扩容、缩容都没问题,数据也会飘到新节点上,接下来准备把生产库往测试环境TiDB导一份,看看有没有什么问题……
多谢各位这几天的帮助![]() ,提供的文档和想法对我很有帮助,也学习到了很多
,提供的文档和想法对我很有帮助,也学习到了很多
结贴
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。