【集群环境】
4.0.8版本,集群A、B都是3tidb 3pd 9tikv架构,共3台服务器,每台1tidb 1pd 3tikv,资源较充足。
目前观察到2个集群(A和B)出现过下述异常现象。其他集群也可能存在不方便一一测试。
集群A从未安装过binlog组件,集群B正在使用到kafka的同步(pump+drainer)。
【异常现象】
通过mysql命令行执行: show pump/drainer status; 3个tidb中有一个会报context deadline exceeded的报错,具体截图见下文。剩下2个tidb节点执行命令无异常。
3个节点执行其他常见指令也都正常。
【错误截图】
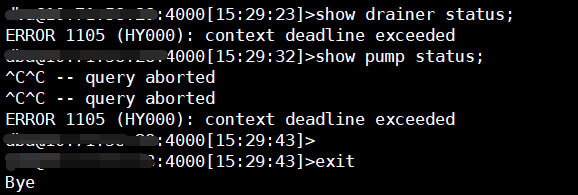
pd日志无异常,命令执行期间全部是正常的INFO级别的leader transfer信息,且频率较低。
tidb日志只有一条相关报错(INFO级别),前后也全部都是正常的INFO日志。
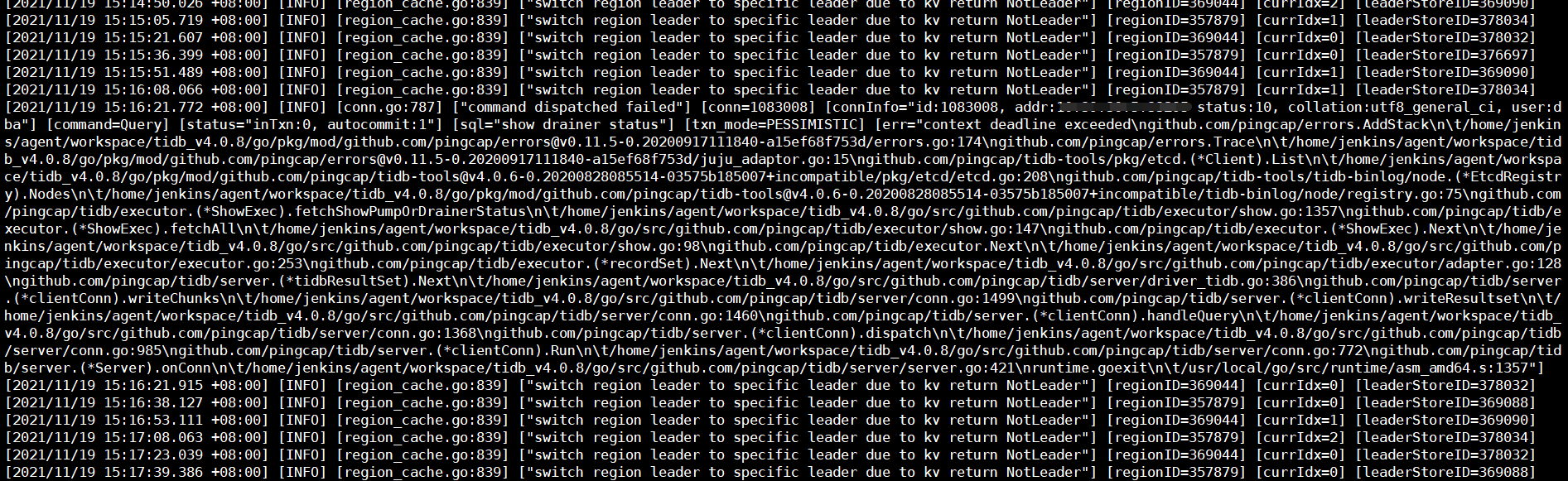
【其他】
出问题的tidb节点,配置文件与其他节点一样,目前看来A、B两集群在此问题上的共同之处为:出问题的节点上都有prometheus和grafana混部。暂未尝试迁走tidb节点。