pangyana
(Pangyana)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.9
- 【问题描述】:
利用sysbench插入1亿的数据,发现插入数据过程 和 创建索引过程消耗的时间差不多,并且创建索引的时候,占用的cpu更高。
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Creating table ‘sbtest1’…
Inserting 100000000 records into ‘sbtest1’
Creating secondary indexes on ‘sbtest1’…
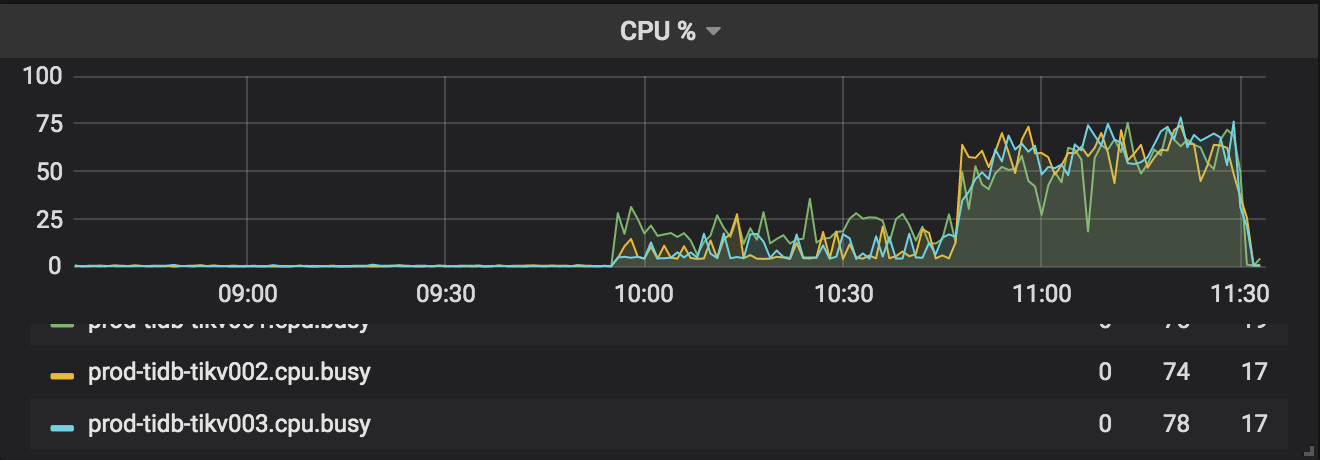
前面的曲线是Inserting 100000000 records,后部分曲线是Creating secondary indexes
这个监控图表是机器的监控,不是tidb集群自带的监控。基本加索引要消耗75%的cpu。这是为什么呢?
tikv机器配置是8核32G
1 个赞
add index 的操作,对于 TiDB 来说主要是做两个事情:
- 修改 table 的元信息,把
indexInfo 加入到 table 的元信息中去。
- 把 table 中已有了的数据行,把
index columns 的值全部回填到 index record 中去。
这个是 tikv 的机器还是 tidb 的机器?
具体 DDL 的介绍可以参考这篇文章:
加快造数过程可以调整 sysbench 造数步骤,具体可以参考:
https://pingcap.com/docs-cn/dev/benchmark/how-to-run-sysbench/#数据导入
wink
(winkyao)
3
这主要是因为加索引还需要读取行数据,再把索引数据写入,所以可能会在 sysbench 的时候比写入数据更耗费时间。另外一点是 CPU 使用量,这个是符合预期的,Add index 操作是一个低优先级操作,在集群没有其他负载的时候。会尝试用更多的资源来加速写入。
pangyana
(Pangyana)
4
Add index 操作是一个低优先级操作,在集群没有其他负载的时候。会尝试用更多的资源来加速写入。
—有控制加索引这个操作资源占用的参数吗
wink
(winkyao)
5
如果有其他的问题,麻烦提新的 asktug 问题。感谢
system
(system)
关闭
8
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。