作者:李乾坤,喜马拉雅 Java 工程师。本文系 2019 年 12 月份上海 “TUG 走进喜马拉雅”活动分享实录。
项目背景
关于推送系统,举个例子,比如说喜马拉雅现在有直播,有的主播有几百万粉丝,那么当他的直播开播以后,需要大量地推送出来,提醒所有的粉丝进入到直播间去观看。所以后面那么复杂的系统,一切目的都是为了这个推送能够快速、准确地到达。
今天分享首先会介绍一下推送的基本原理。因为几十分钟的分享是没有办法完全说清楚推送原理的,所以后面主要讲一下存储相关的东西,传统存储方式的困难,基于 TiDB 存储的优势。最后分享一些关于 TiDB 的实践。
推送业务的基本原理

现在,先说一下基本原理,推送主要就是两个过程:一个是绑定,一个是下发,先说下发。
先跟大家解释一个基本的问题,喜马不是直接给用户设备发推送的。为什么呢?如果我不说的话,很多人可能会以为,比如我有一个设备叫 xx,我订阅的专辑更新了,通过推送系统直接给这个设备去发一个消息。但实际上我们一般都是通过第三方服务商发送设备通知的。为什么?因为大家知道,首先 IOS 后台前一阵子杀后台非常狠,包括安卓很多客户端的系统为了省电,杀后台也杀得非常狠。我们的系统没办法跟 APP 建立一个非常直接的通道,所以说我们是没有办法做这件事情。在国内,如果你想跟 IOS 系统发推送的话,只有去走苹果的官方推送系统。比如说我要给苹果设备发一个推送,那么就是业务方把需求给到我这个推送系统,推送系统处理完之后,再发给苹果,苹果再发给苹果的设备。Google 也有这样一个系统,但在国内没办法用,所以国内有很多第三方服务商去填补 Google 的官方推送服务,比如说小米,个推,还有极光。
回顾一下,我们要给苹果设备推,就发给苹果官方的推送系统,官方的推送系统再发给设备;我们要给安卓设备推,我们公司和第三方合作,就把推送先发给第三方,然后第三方再发给安卓这样一个过程。推送系统绕了一个推送服务的第三方,就带来一个问题:比如业务方说,现在给我的设备发一个通知,业务方只知道我的 UID/deviceID,deviceID 是我们公司内部对一个设备的标识,我们所有的数据行为都是基于 UID/deviceID。那么这时候,我把 UID 直接给了第三方,第三方肯定推不了,人家不认我们这个 UID,他们认什么呢?他们认自己的 Token。他们自己的设备也有自己的标识,这就产生一个过程,就是推送系统业务方说,给设备推一个通知,然后业务方把 UID 传给推送系统,推送系统在这个时候做一个转换,把 UID/deviceID 转换为第三方能够识别的 Token,然后第三方拿着这个 Token 设备再做推送。有转换的过程,就有绑定的问题,我们是怎么解决的?我们的 APP 在启用的时候,因为客户端能拿到第三方的 Token,也能拿到我的 UID/deviceID,那么客户端在启动的时候,同时把 UID 还有 Token 发给我的推送系统。
刚才说那个绑定和下发的流程,如果再细化一下,大概是这样一个系统:绑定服务拿到 UID,Token 的绑定,会存在一个设备管理存储问题。然后呢,我们推送系统对外使用一个推送的接口给到业务方,比如专辑更新的时候,专辑订阅的程序员拿到这个用户信息,使用接口直接就推就好了。这个接口之后接着消息队列,消息队列有个削峰作用,队列收到之后,会经过一个转化,就我刚才说的,把我们 UID 转成第三方 token,当然中间还有一些过滤的一些服务,比如说频控什么的,比如说我们约定好一天不能给用户发超过三个推送。
推送里面有大量的技术难题,比如说直播,我们相关的人员统计下来说我们一个直播一般是一个小时,那么这个时候你要给一个主播的所有的粉丝发开播提醒,必须半个小时内推到,所以说直播业务时效性会非常高。但有些业务,比如专辑更新,一个小时还是两个小时之后告诉用户专辑更新,不是特别的关键,所以说这个时候就有一个隔离的问题,这个是我们花了很大了精力但今天不是我们主要的话题。
原存储方案
分库分表
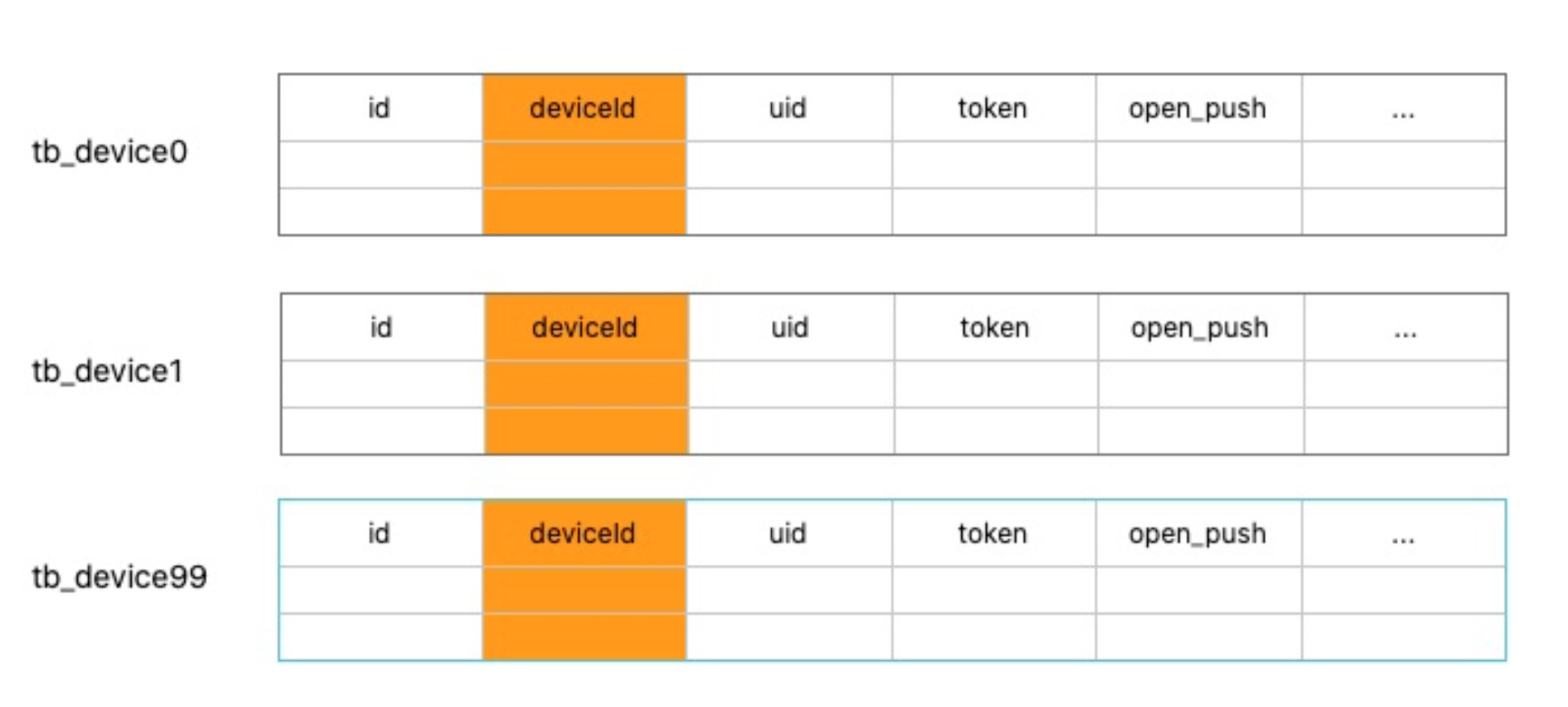
今天主要讲存储这块设备表的处理,先说一下我们存储的第一个痛点,就是我们要做分库分表。喜马拉雅现在有六亿的用户,将近三千万的日活用户,用户不管他打开我们 APP 之后,是允许推送还是拒绝推送,我们都要把这个数据记录下来,因为我们有一些服务,他想知道,用户到底把推送打开了没有。也就是公司每天新增几十万的用户,我们这个表里面每天新增几十万,一直累计到现在大概六亿的用户。当然常规的想法就是用 MySQL 去存,大家都知道,MySQL 单表去扛一个六亿级别的数据量,反应就很感人了,上游稍微有点压力就受不了,很可能会挂。我们最直接的想法就是对 MySQL 进行分库分表,内部的习惯是把它弄成一百张分表。每一个分表记录了 UID,deviceID,token,Open _push(推送开关),还有一些其他的我们内部认为有意义的一些字段。
分库分表有一个基本的问题是,要指定一个分表列,比如说一个用户过来,我把它存到哪张表里面。我们用的是 deviceID,也就是说一个新用户过来,我们会根据它的 deviceID,先计算一下它到底在哪个分表里。当然分库分表现在业界方案很成熟,只是麻烦一点。
第二个痛点就让人非常难受了,我刚才说过,我们这边是分库分表之后是根据 deviceID 分库分表,但是有的业务,它非得按 UID 去查,一旦 deviceID 分了表之后,我想判断一下某个 UID 是否打开推送,只能每张表都查一遍,一百张表要查一百次,这个就很难让人接受了。我们还有个场景就是按照 Token 去更新设备数据,因为用户会一直不停的卸载、重装,导致 Token 会改变,老的 Token 会失效,为了解决这个问题,苹果还有小米,他们会提供一个回调的服务,把那些失效的 Token 告诉我们,这时候我们要根据 Token 把那个设备的 Open_push 改成 false。
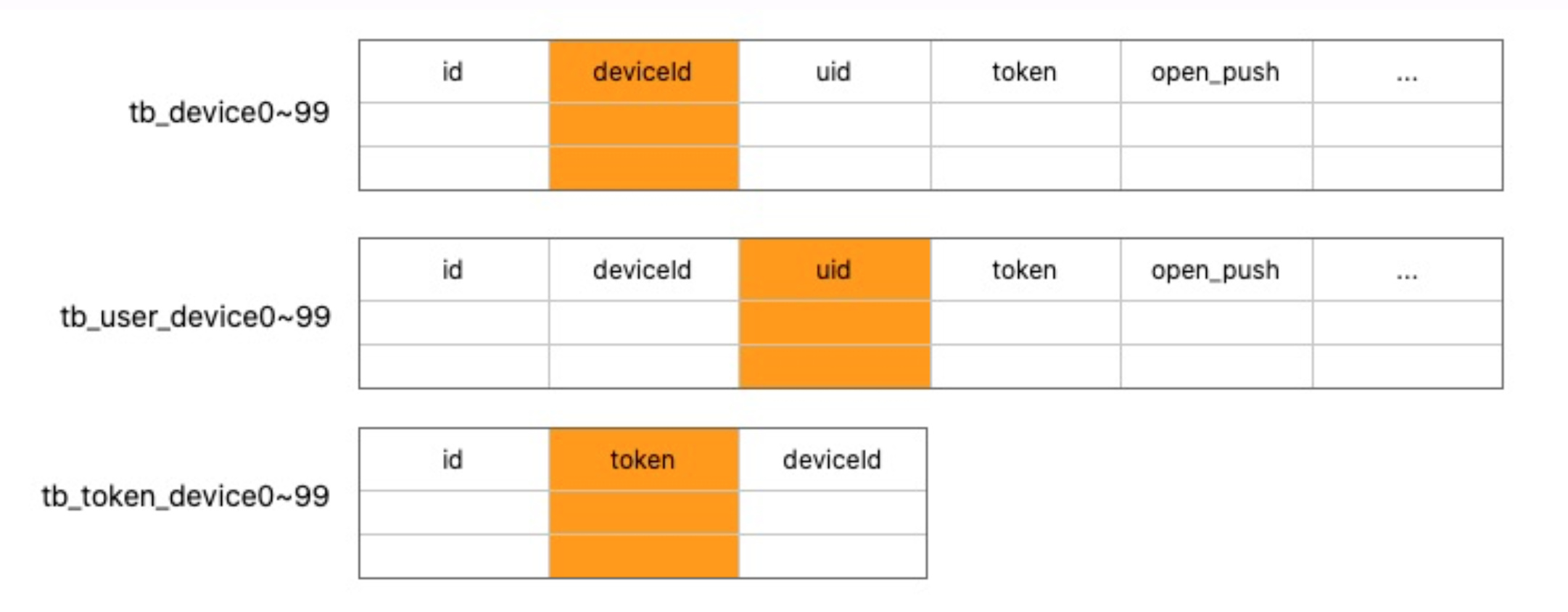
这就是分库分表之后常见的困难,为了解决这个问题,最简单最直接的想法,就是把 UID 到 deviceID,Token 到 deviceID 的映射关系再存储一下。
MySQL 与 Pika 数据同步
大家可以发现我们数据都存了三份,每份都是一百个分表,其实非常浪费存储空间的,处理性能也很感人。光这个还不算完,因为即便是我们分了一百张表,要 MySQL 直接去扛查询性能还是不行。就像我刚才说的,我们直播要求 30 分钟就把所有的粉丝都要推到,有的主播上百万的粉丝,开播时一下子上百万的请求过来,对性能要求非常高,拿 MySQL 直接去扛请求受不了。
那么怎么办呢?当然还是直接上 Redis,在 MySQL 前面加个 Redis,把数据缓存一下,但 Redis 是基于内存的,容量就比较有限,扛不住六亿。为了解决这个问题,我们用了 Pika,Pika 是 360 开源的一个基于磁盘的 Redis,大家可以认为它还是一个存储,支持 Redis 协议,只不过是基于磁盘的。容量问题解决了还不算完,推送不存在热点,我们一般用 Redis,都是利用数据的局部性原理。但是我们有个业务是全局推送,每天早上要所有用户全部推一遍,这个时候就没有热点了。不过好在,我们 Pika 基于磁盘容量也比较大,把所有的数据全部又存了一份。

经过刚才铺垫,大家可以发现,现在的存储就已经很复杂了,首先数据要存三份,每份是一百张分表,然后 Pika 是三个实例,它的 KeyValue 也分别按照UID,deviceId,Token 又存了三份,多维多份。我们刚才说过 Pika,你可以认为是 MySQL 的一个从库,日常的绑定请求改了 MySQL 之后,还得同步下Pika。我们自己写了一个服务,消费 MySQL 的 Binlog 日志同步到 Pika,理论上应该是一致的,但有的时候,发现同步的数据不太对,然后有一个全量同步的服务。
我们总结一下原来存储方案的问题:
第一,就是业务复杂,新人要一个月的熟悉才能接手。我们推送今年换了两波人,新过来一个人我问他,你什么时候可以开始接需求?他说不行,你再给我一个月的时间。大家可以看到存储是分库分表的,Pika 是分库分表的,中间还有全量增量的同步,一个新人接手要花一个月。
第二,用户数据更新的时候,要更新三个表,理论上,要用事务去保证一致的,但是因为请求量比较大,没有用事务,存在数据不一致的可能性。
第三,就是批量推送一千个 deviceID 的时候,为了优化使用了 Redis 的 Pipeline,代码很复杂。
第四,MySQL Pika 同步的问题,两者有的时候不一致。我回答分析师疑问的时候,就不硬气,因为 Binlog 量大的时候会有延迟,随便一想,就十几个原因导致用户没收到推送。运营问一次查一次,经常无疾而终,不硬气。
第五,每日推送总量在十亿量级,一次批处理的请求处理耗时是比较长。推送本质上是个数据处理系统,它跟 Web 请求的处理是有差异的。举个例子,比如一个请求,耗时是一毫秒还是两毫秒,用户是无感知的。但是推送是一个消息队列,如果消息平均下来能从两毫秒优化到一毫秒,意味着一次全局推的时间可以节省一半。我们在三四月份的时候,一次全局推要三四个小时,五六亿用户扫表处理一次,它是累加的,只要稍微优化一下,整体的响应时间就可以很客观的缩减。
新存储方案 – TiDB
在今年的六七月份的时候开始去想新的存储方案,推送有互相矛盾的几个特点:
首先,它的业务是有多种多样的,有大量的 KV 查询,根据 deviceID 查 Token就可以。
第二,有的时候只需要安卓的 6.3 以上的版本才需要发推送,这需要关系型条件查询。我们优化产品的时候,直觉上你可以换个更大的,比如 Hbase,但是它没有办法支持关系型查询。我们需要关系型查询,还希望它性能好一点,基于这样一个考虑我们选用了 TiDB。
关于 TiDB,我简单说一下,大家可以认为它是一个无限容量的 MySQL。它支持 MySQL 协议,如果有一个 TiDB 实例,还有一个本来访问 MySQL 的项目代码,你只要把 MySQL 的 IP 改成 TiDB 的 IP,就可以直接用。除非有些特别的语句,一般都没有关系。其次,无限也不是说无限容量,容量不够加个机器,支持横向扩展。
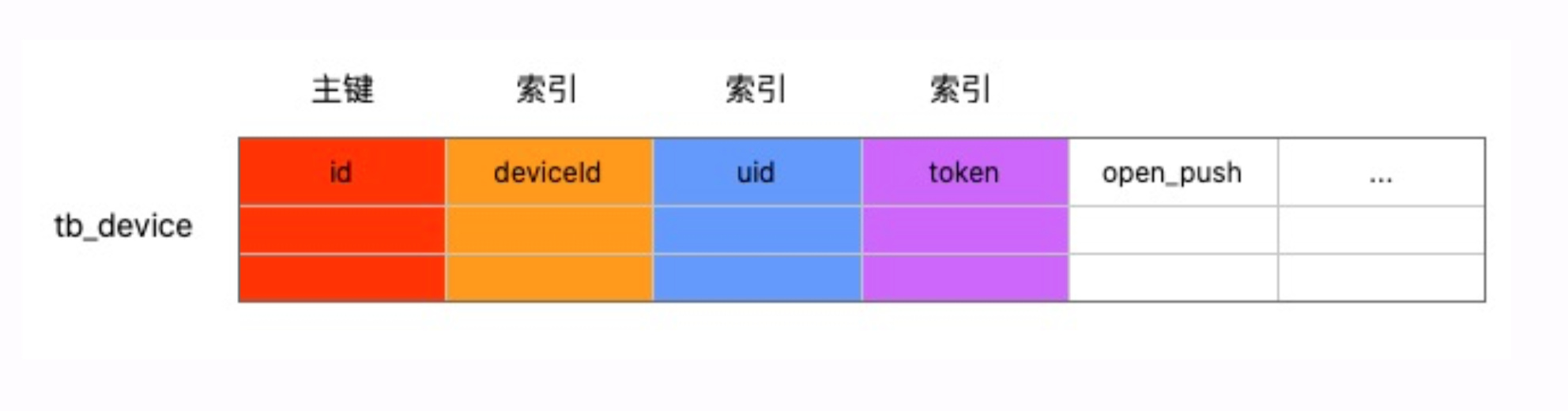
TiDB 可以认为是个无限的 MySQL,首先分库分表的事就不用了,我们就一个表就好了,多维查询的事怎么搞呢?我们 UID、deviceID、Token 都建了索引,就搞定了。绑定和查询请求直接打到 TiDB 里边。因为只有简单的 SQL 访问,任何一个新手过来,看一看就知道这个是怎么回事。
然后说一下 TiDB 的优点。
第一,代码的复杂性大大下降,一个人就可以维护。 TiDB的本质是什么?它的分库分表,多维索引,事务,副本,这些基本特性,下沉到数据库层面,之前我们做的那么多工作,相当于在业务层去解决这些问题。
第二,我们认为它的性能基本满足要求,它底层是固态硬盘,四个九的响应时间大概是 70 毫秒,并且这个 70 毫秒通常也是写操作,整体是满足需求的。
应用实践
全局分页遍历
我们先不说TiDB,常规的 MySQL 怎么分页呢?大家最直接的想法就是用 Limit,从一页开始,长度是一千。我们遍历的时候,通常还要加个条件,比如 iOS大于某个版本,这时 Limit 效率非常低。一般分页如何优化呢?在遍历的时候给它一个起始的 ID,然后比如现在能查到最大的 ID 是—亿,决定分页是一千,相当于每页起始的 ID 是直接可以算出来的。但是这个方式在 TiDB 上不成立了,因为 TiDB 索引不是 B+ tree ,于是我们干脆遍历的时候,直接写起始 ID、结尾 ID。假设你有一亿,分页是一千,那么你每次起始 ID,直接可以算出来的。但是这样有个缺点:你不能保证每一次分页,刚好是一千条记录,好在这个对我们业务影响不大。除此之外,即便是分页,也不可能说一个线程慢慢分,通常你要用多线程,我们 MySQL 时代 100 个分表,干脆一百个线程,每个线程管一个表。在 TiDB 时代,每次广播的时候,先找到这个 ID 的最大值,计算每个线程 ID 的范围。以前用 MySQL 一次全局推要三四小时,现在 TiDB 30 分钟就可以完成。
在线和离线业务共用
在线和离线业务共用这个问题现在还没有解决,我们只是给大家分享一下这个问题。我们希望在支持 toC 请求的时候,能够支持一下离线计算,什么意思呢?比如说刚才前面有一个 tb_device 表,每时每刻它都在应付推送查询,但这个时候,想去做一个数据库的分析,聚合设备数据的时候,相当于 toc 正查着,大数据系统也在查。我们曾经试过一次,直接就超时了。大家可能会有疑问,为什么 TiDB 不建一个从库,基于从库做 OLAP?这个其实是经济上的考量,要是数据量小,没必要放在 TiDB 上,能放在 TiDB 的业务数据量都很大,另搭一个成库的成本很高。
然后我们说一下为什么会相互影响,我们可以认为这边是 KV 的协议,这边是 MySQL 的协议,tidb server 在过程中起一个解释/转化的作用,所有的用户请求最终去查询 tikv server,每一个 region 三个副本,分为 Leader 和 Follower 两个角色,Leader 扛峰值的请求。因为所有的请求都要过这个 Leader,就会相互影响。
好在,这个问题后续也会得到解决,我们跟 TiDB 官方沟通下来,他们会在一个比较新的版本里面为副本再抽象一个角色,正常的请求走 Leader,被标记的请求(比如数据分析)走新的副本角色,这样实现 toC和 toB 的请求不共用 Leader 节点,不相互影响。
未来的设想
今年发现一个特点,我们喜马拉雅用户对新闻的需求点非常高。之前有一个非常爆款的一个新闻,直接把日活比平常带高了五六十万,为此对全局推的性能提出了更高的要求。现在一次全局推要三四十分钟,能不能十分钟推完?大家知道,一般用户手机装了好几个 APP,如果说我们比别人推的慢了,别家推送先到了,用户就不点我们了。当有这个更苛刻的要求的时候,以前一些无所谓的性能优化的点,现在就可以搞一搞。TiDB 有一个跨节点的通信问题,通信了两次,直觉的优化想法就是减少一次通信。TiDB 外层是 tidb server,内层是 tikv server,如果说我们可以直接查 TiKV,是有机会把这个速度给提高的。