为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.1.0-beta
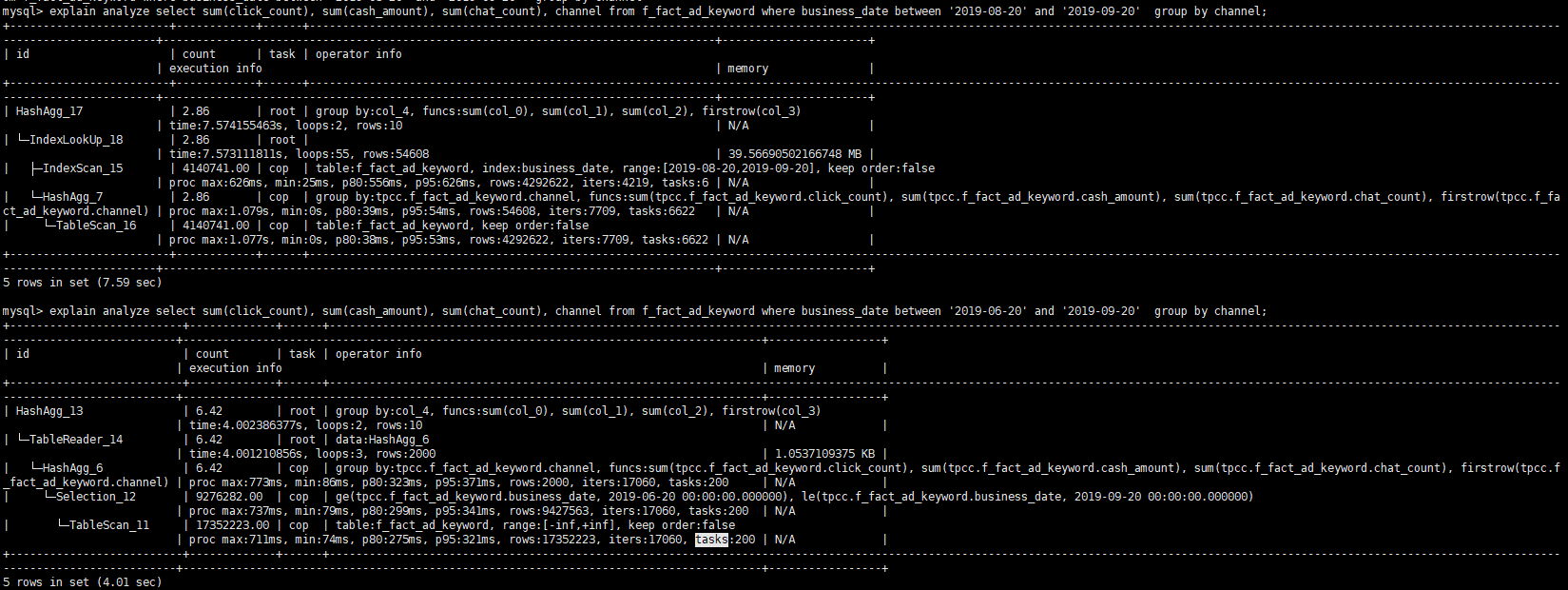
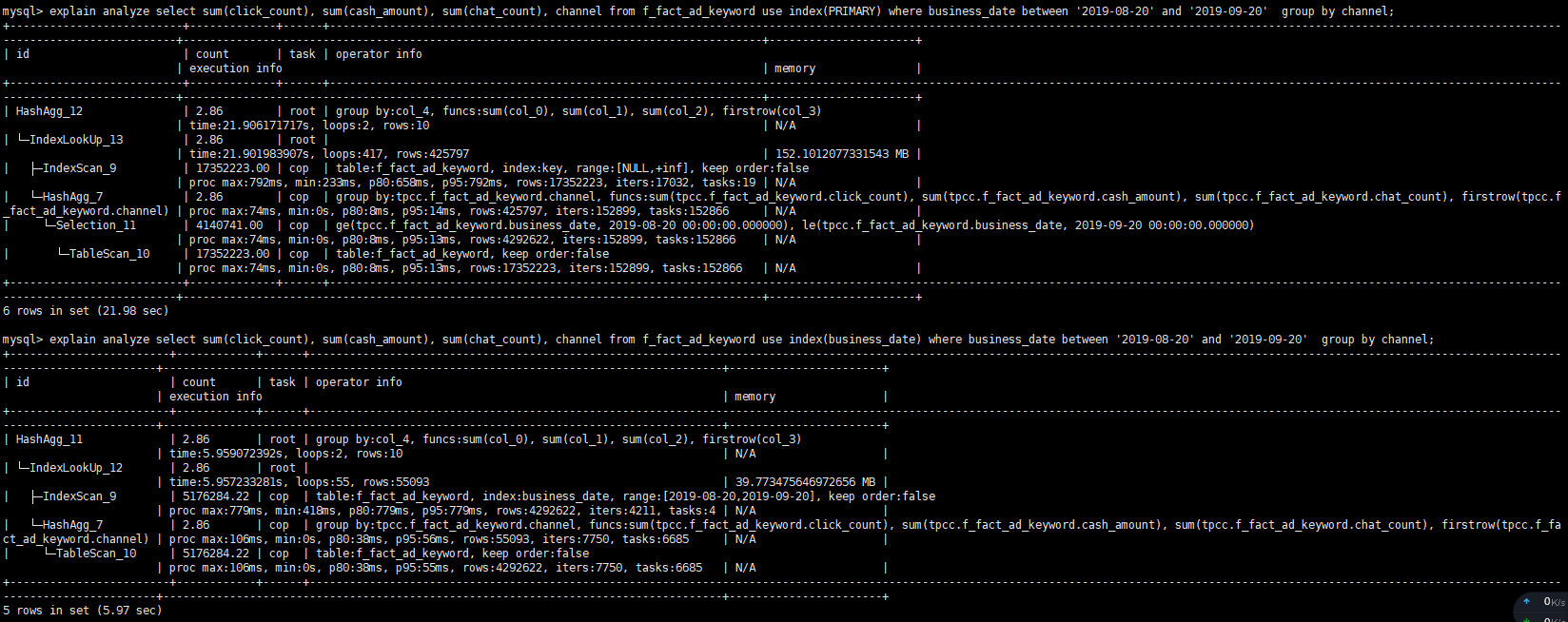
- 【问题描述】:同样的SQL,range范围大查询更快,使用索引比没用索引慢
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
这两条 SQL 的查询范围不一样,第一条 SQL 加上 use index() 让他走全范围的 table scan 看看 explain analyze 的执行结果呢?
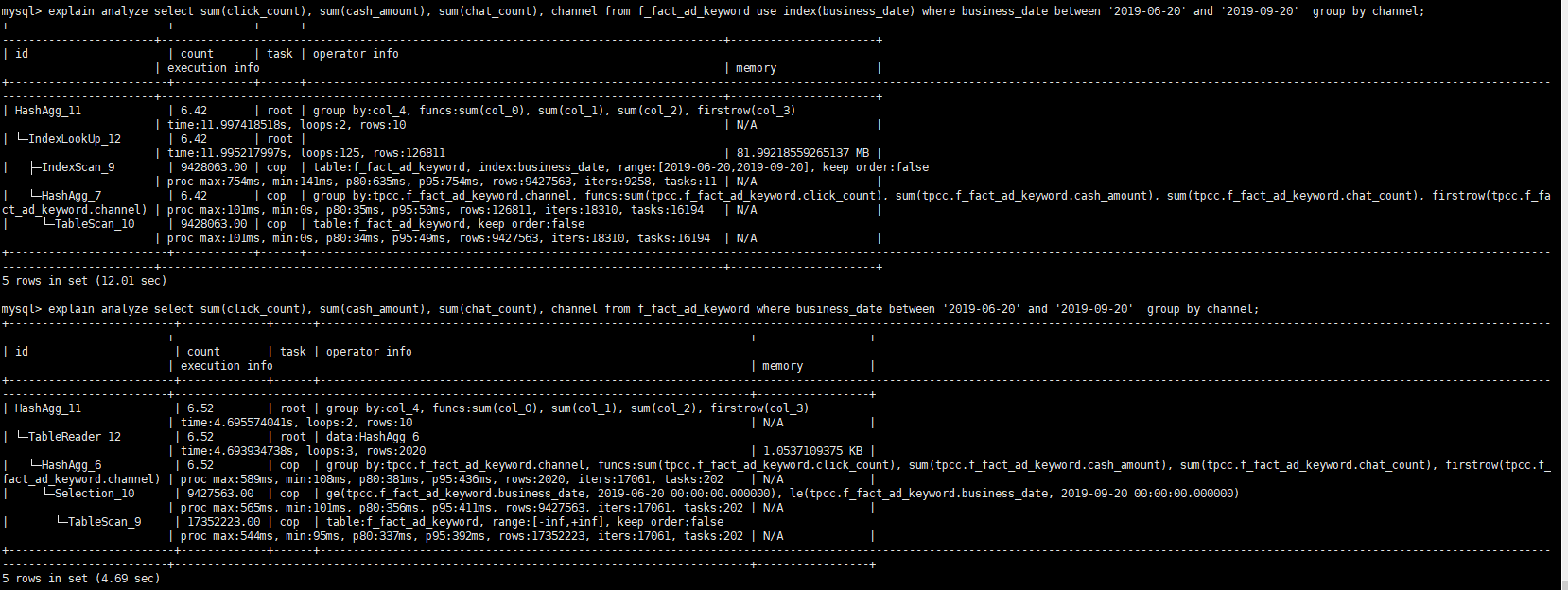
麻烦在 business_data range 相同的情况下 通过 use index() 提供下走索引以及全表( primary key )的 explain analyze 的结果。
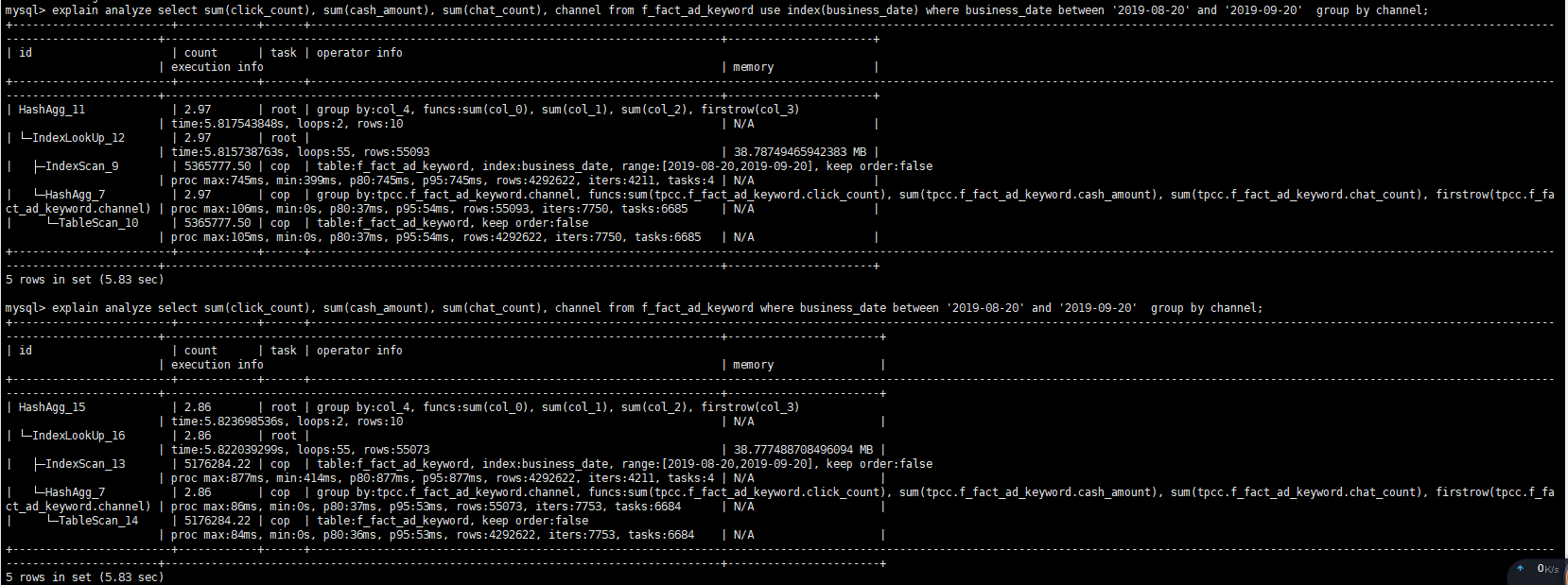
能否再提供下基于 between ‘2019-08-20’ and ‘2019-09-20’ 的 explain analyze 的两种结果?
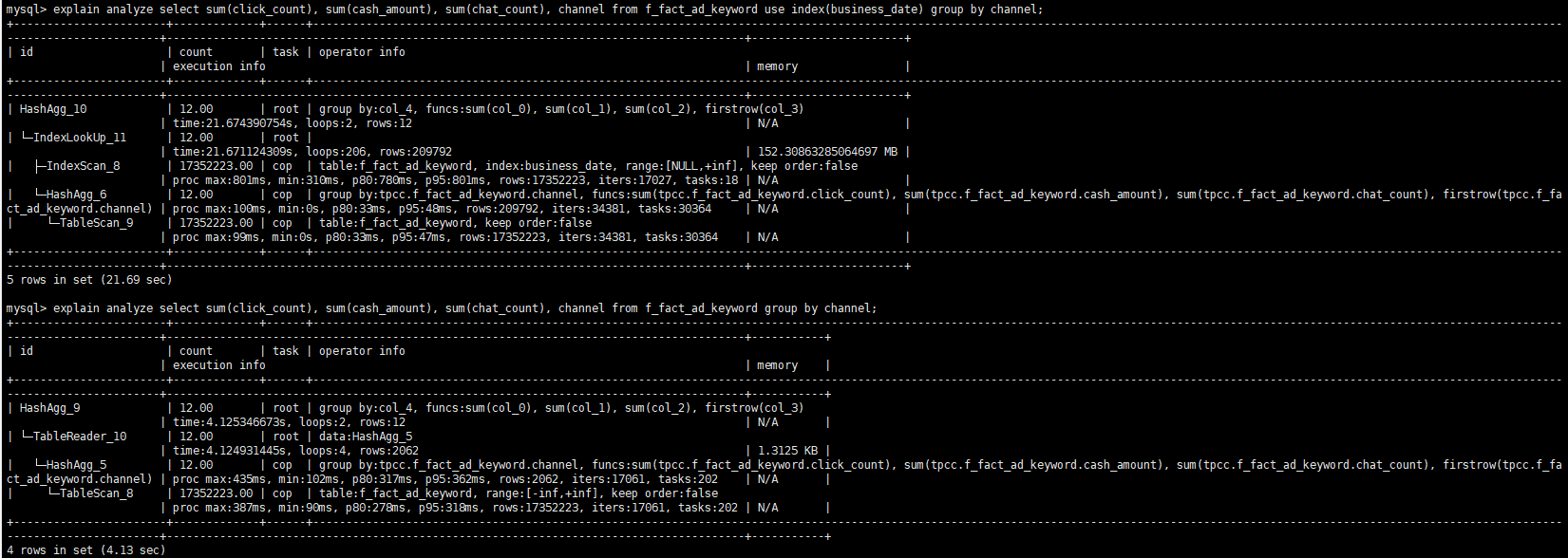
麻烦把 use index 部分改成 use index (PRIMARY) 看下效果。
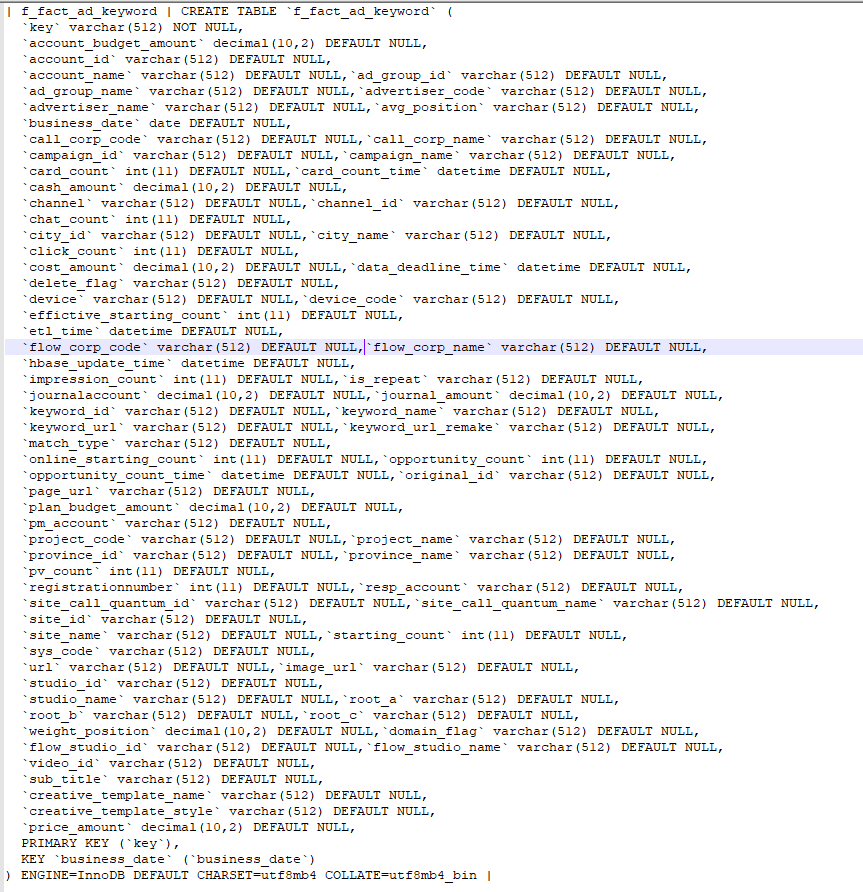
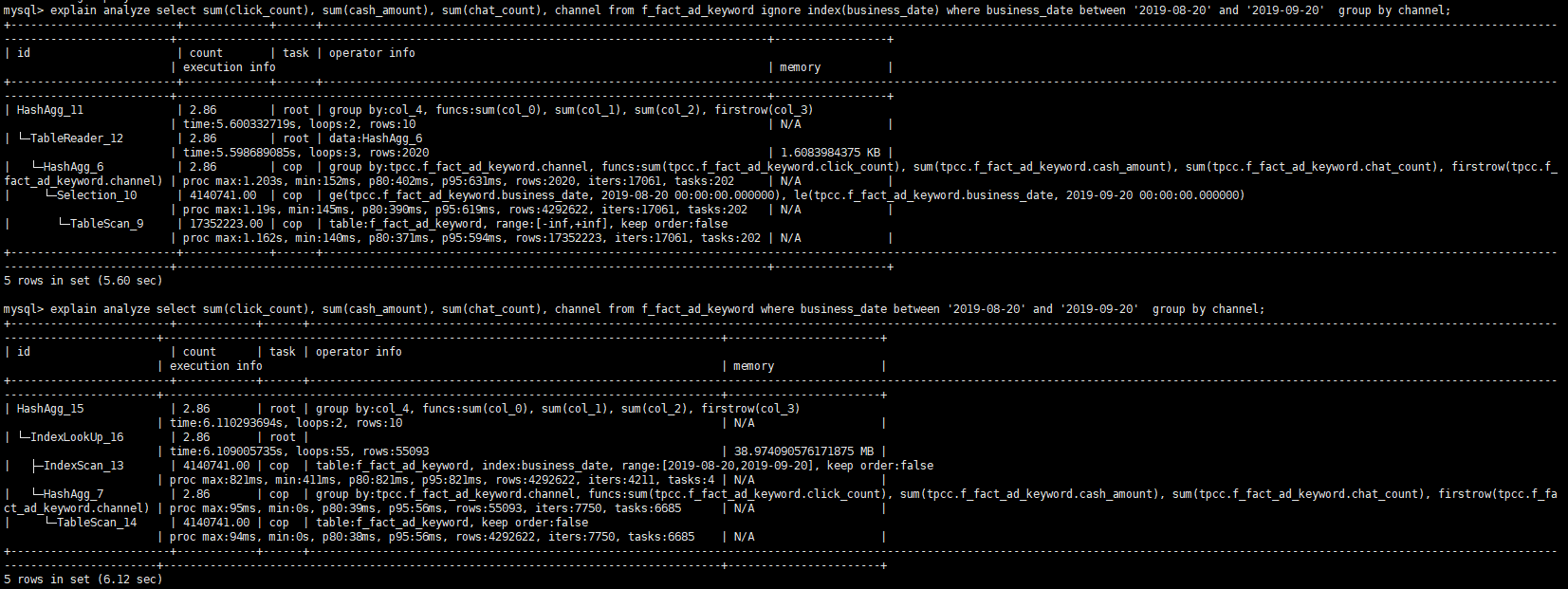
show create table的结果use index (PRIMARY) 的 hint 改成用 ignore index (business_date , {other_index_name} ) 再看下结果麻烦在业务低峰的时候执行一下 analyze table {table_name} ,之后再执行一下看下不加 hint 的 explain analyze 的结果。
我们分析了下执行计划,business_date粒度太粗,每个有差不多20万条数据,走索引的话,root task执行的时候会拉取很多数据,有差不多5.5万条数据,而不走索引的root task只会拉取2000多条数据,这个应该是变慢的真正原因。索引粒度过粗对于查询并不一定有帮助
建议 analyze table 之后再看下结果
analyze也没有什么问题
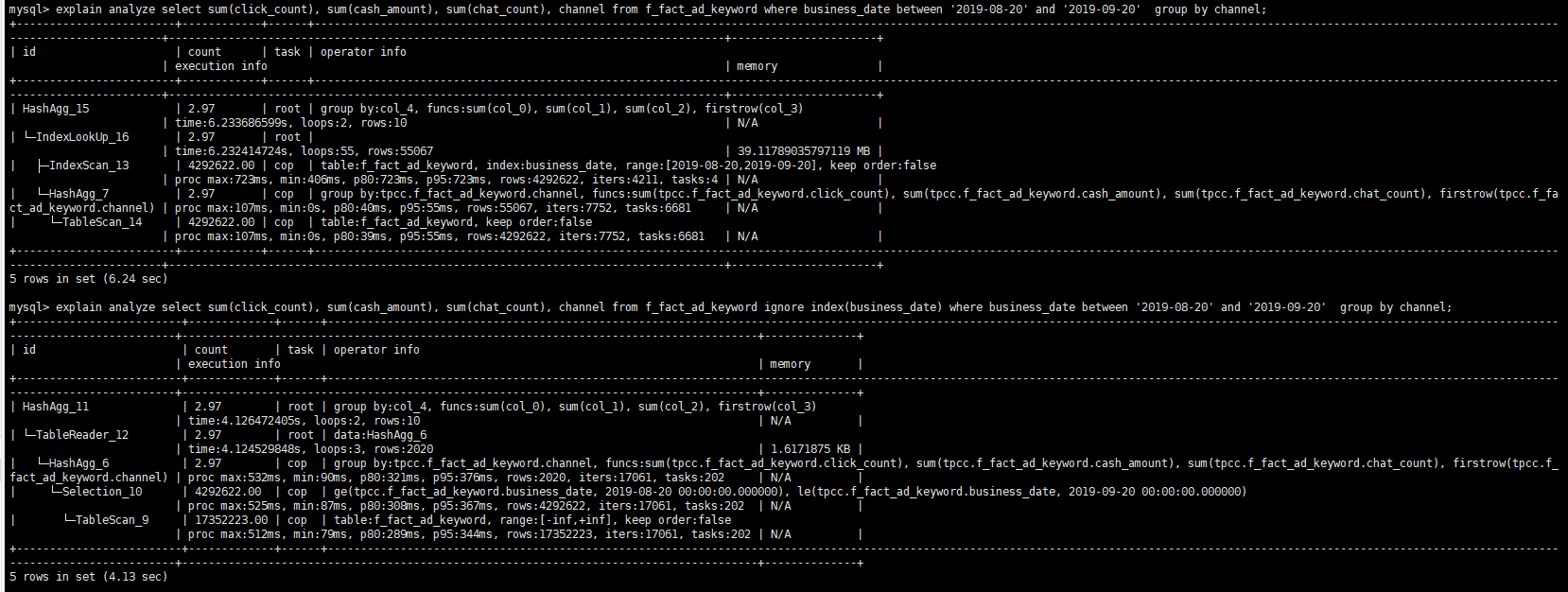
再提供下 explain analyze 的结果看下。不加 hint 的。
看起来两个查询的时间相差不远,应该是优化器对于当前 cost 的评估人为 index scan 比较小,所以走的 index scan 了。而且 index scan 与 tablescan 的估算应该是差不多,所以后续如果 where 条件的 date range 再调大的话会自动选择 tablescan。
对,这种情况可以通过建分区表来规避。
![]()