为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.0
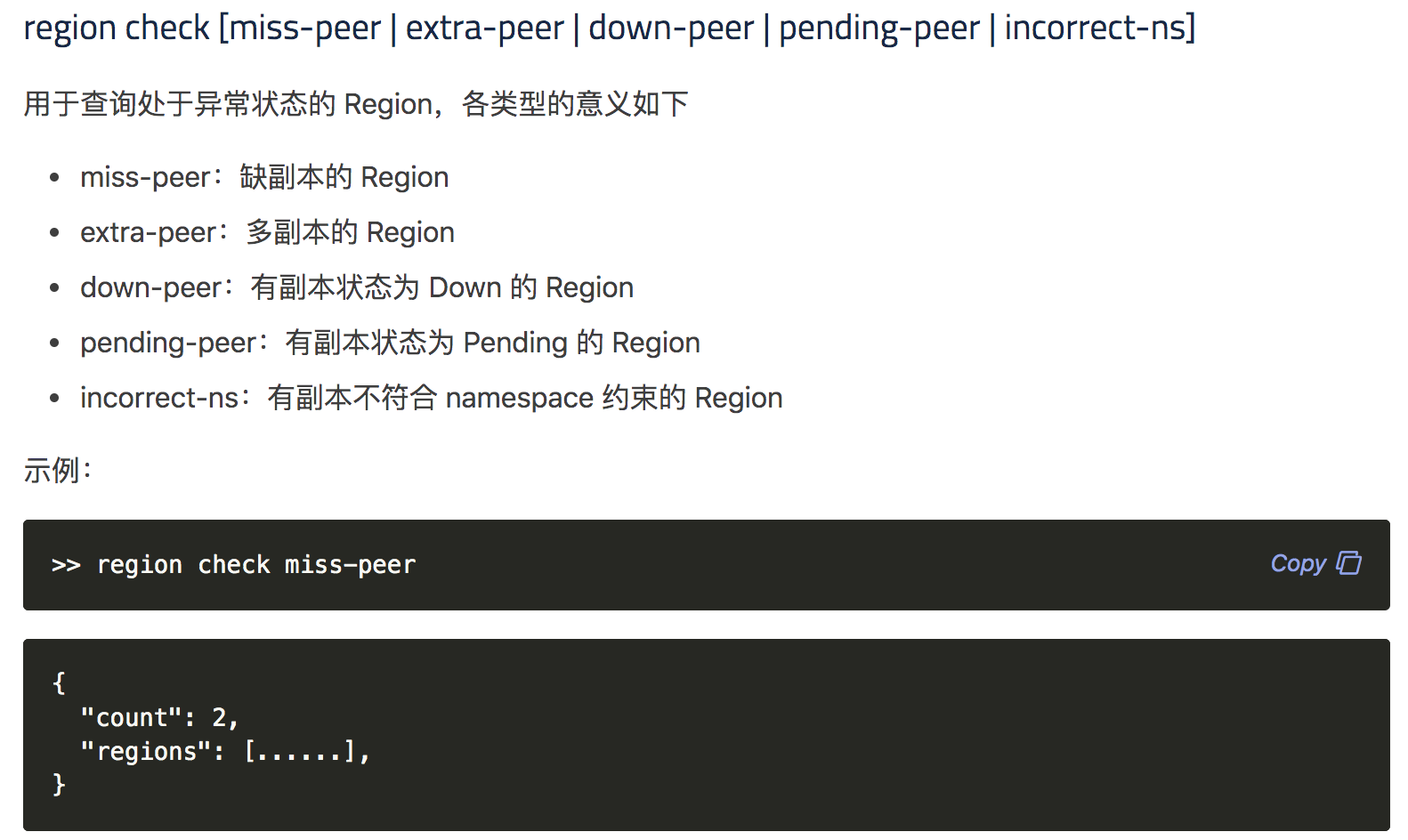
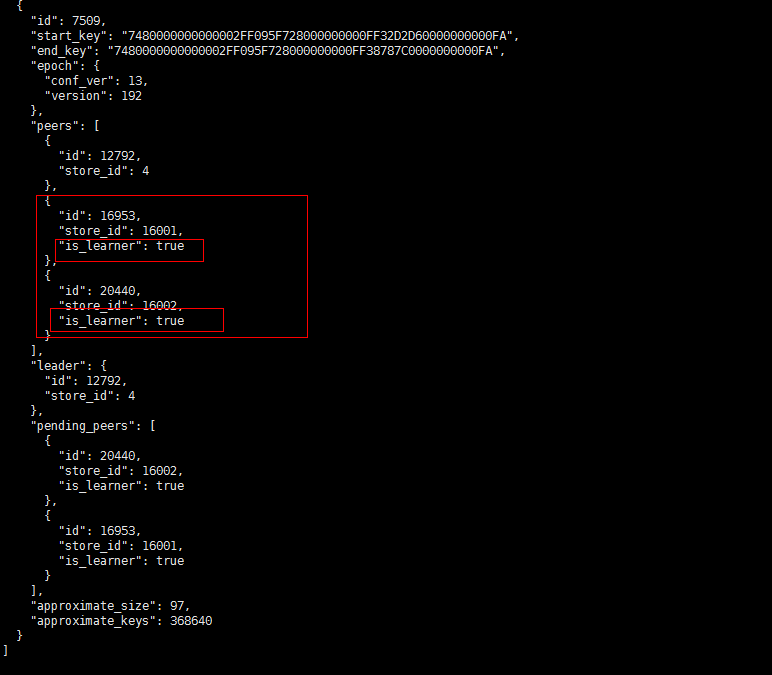
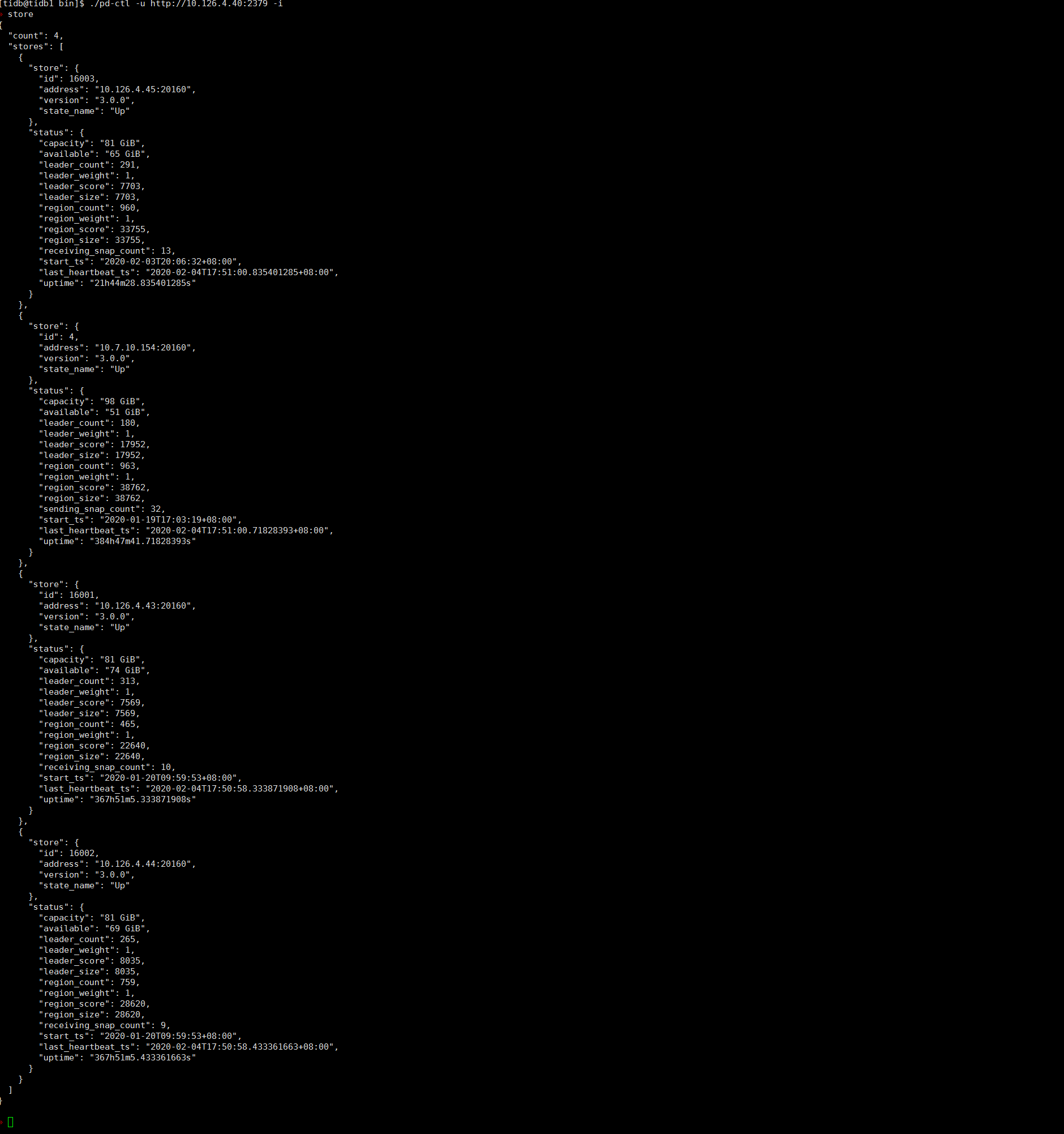
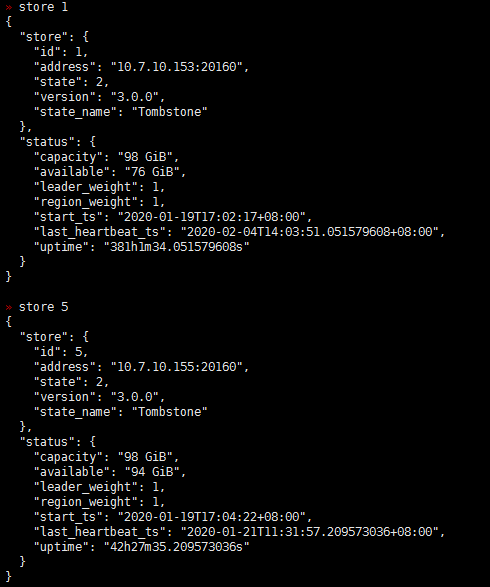
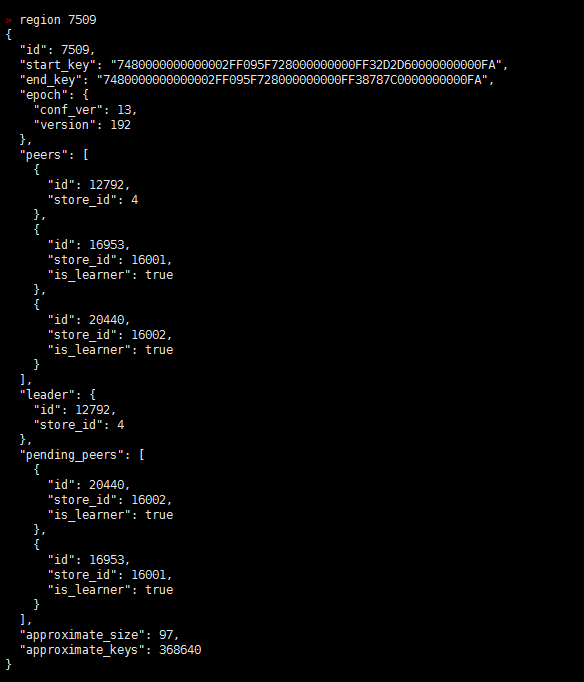
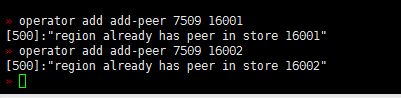
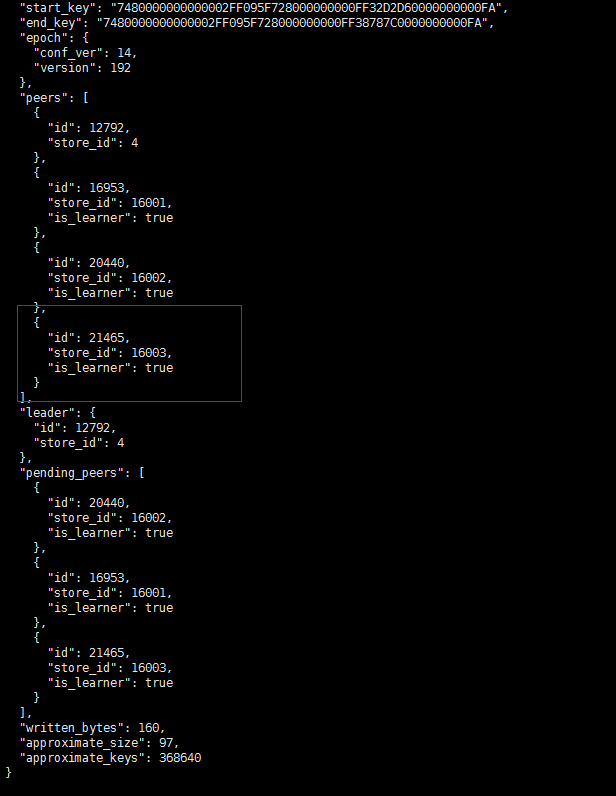
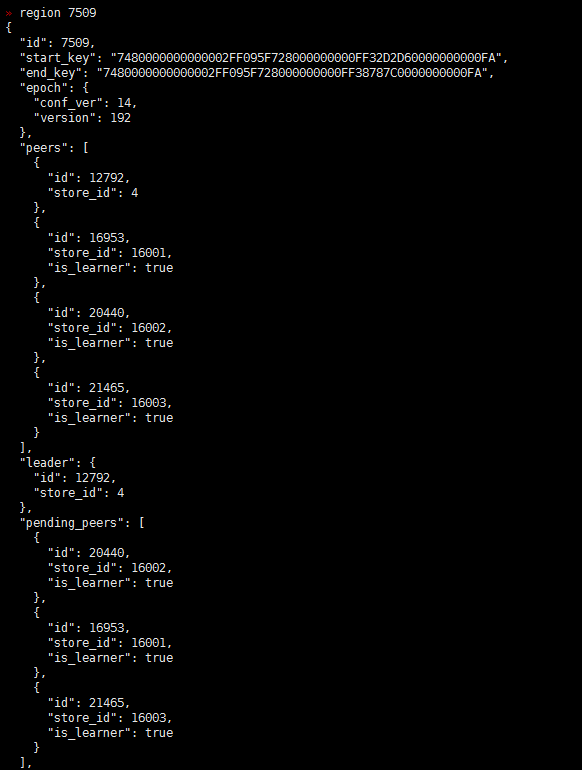
- 【问题描述】:(集群是有arm和x86的机器的混合,之前上线了几个arm 的tikv)现在做x86 tikv节点下线过程中有一些region 无法下线,于是手动执行了operator add transfer-leader operator add remove-peer operator add add-peer 等操作,但是发现补充副本后一直是learner状态,目前集群中还有一些learner_peer 和pending_peer状态的region,这个是如何产生的?如何处理掉?
之前为了快速下线修改了 max-pending-peer-count max-snapshot-count replica-schedule-limit参数


若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。