- 【TiDB 版本】:
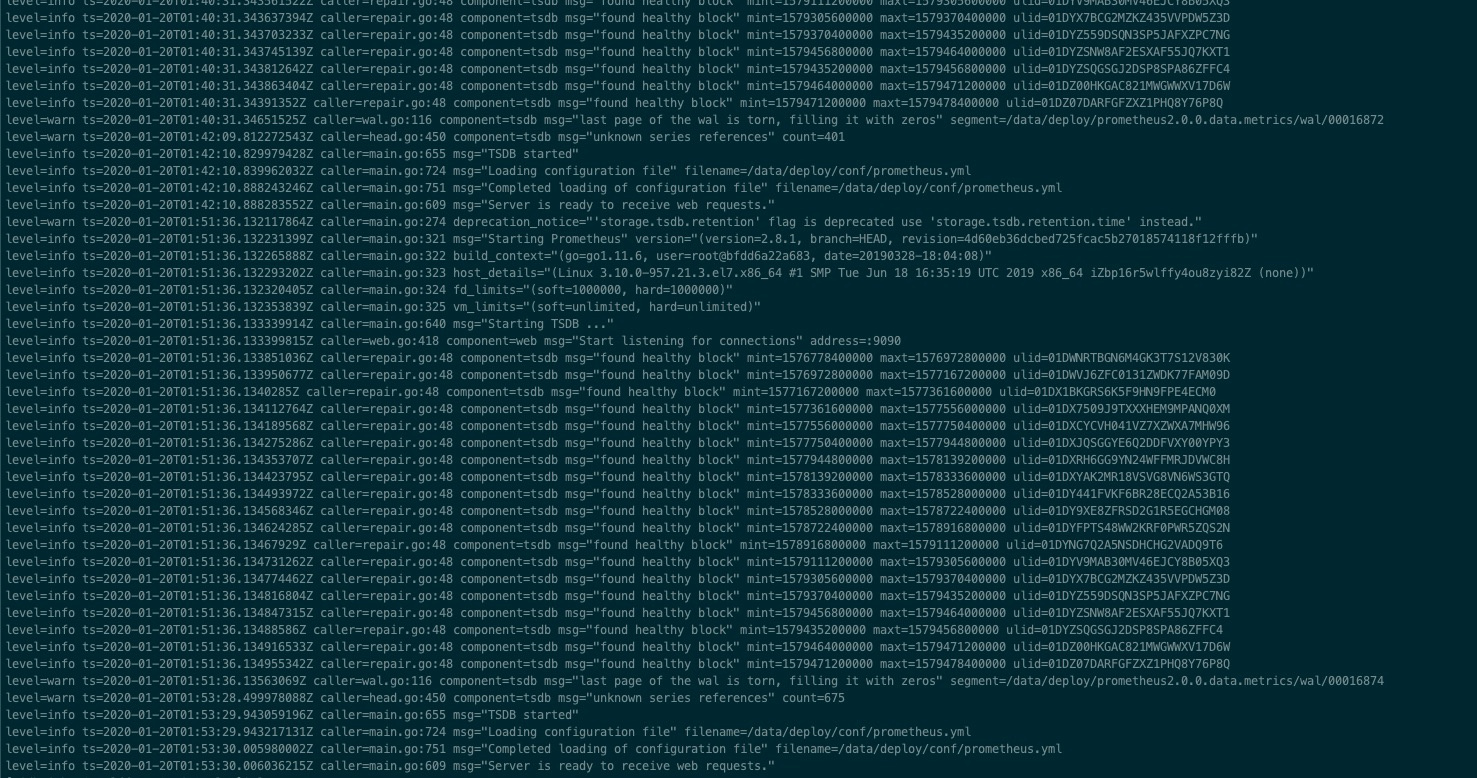
- 【问题描述】:在pd与tidb的机器上,出现一个巨大的目录,以前没有请问可以删除嘛,以下为截图
目录为 /data/deploy/prometheus2.0.0.data.metrics
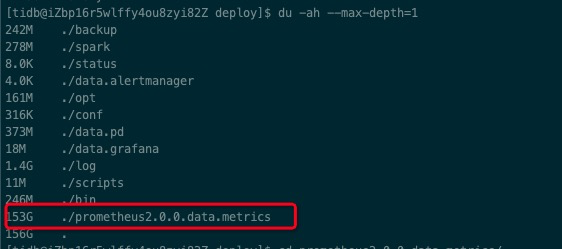
目前服务没啥问题,只是这个容量过于庞大,需要进行清理,可以如何进行清理
目录为 /data/deploy/prometheus2.0.0.data.metrics
目前服务没啥问题,只是这个容量过于庞大,需要进行清理,可以如何进行清理
该目录为 Prometheus 存储监控数据,现在在 Prometheus 默认启动配置中,监控数据保存 30 天。数据量大可能是节点数较多监控数据较多导致的,可以调整 Prometheus 监控数据存储策略,根据实际情况减少保存天数。
cd ./scripts
vim run_prometheus.sh
# 将 30d 调整为 15d,注意仅调整 "30d" -> "15d",同时参数及单位的格式要谨慎检查。
--storage.tsdb.retention="15d"
# 重启 Prometheus 生效
./stop_prometheus.sh
./start_prometheus.sh
多谢老师,服务已经修改,重启观察服务也正常,只是硬盘的容量占用还是很大,是需要等待多长时间才会进行自动清除
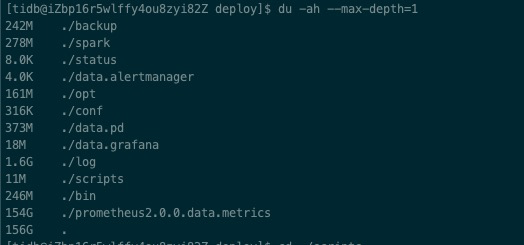
貌似又多了一个G
我先改成了5天,发现还是没有降低
需要再观察一下,监控数据本身数据量很大。另外通过 Pormetheus 日志验证一下调整的时间参数是否生效。
Promethues 关于参数的相关文档 https://prometheus.io/docs/prometheus/latest/storage/
不太建议限制监控数据的大小,会影响到数据分析。还是建议监控数据单独存储到独立文件系统,减少多服务共享磁盘,I/O util 相互影响。
好的,多谢老师
![]()
强烈赞同。
清理数据在后台日志看不到打印信息,只能从存储端查看吗?
![]()
![]()
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。