为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:
v3.0.8 - 【问题描述】:
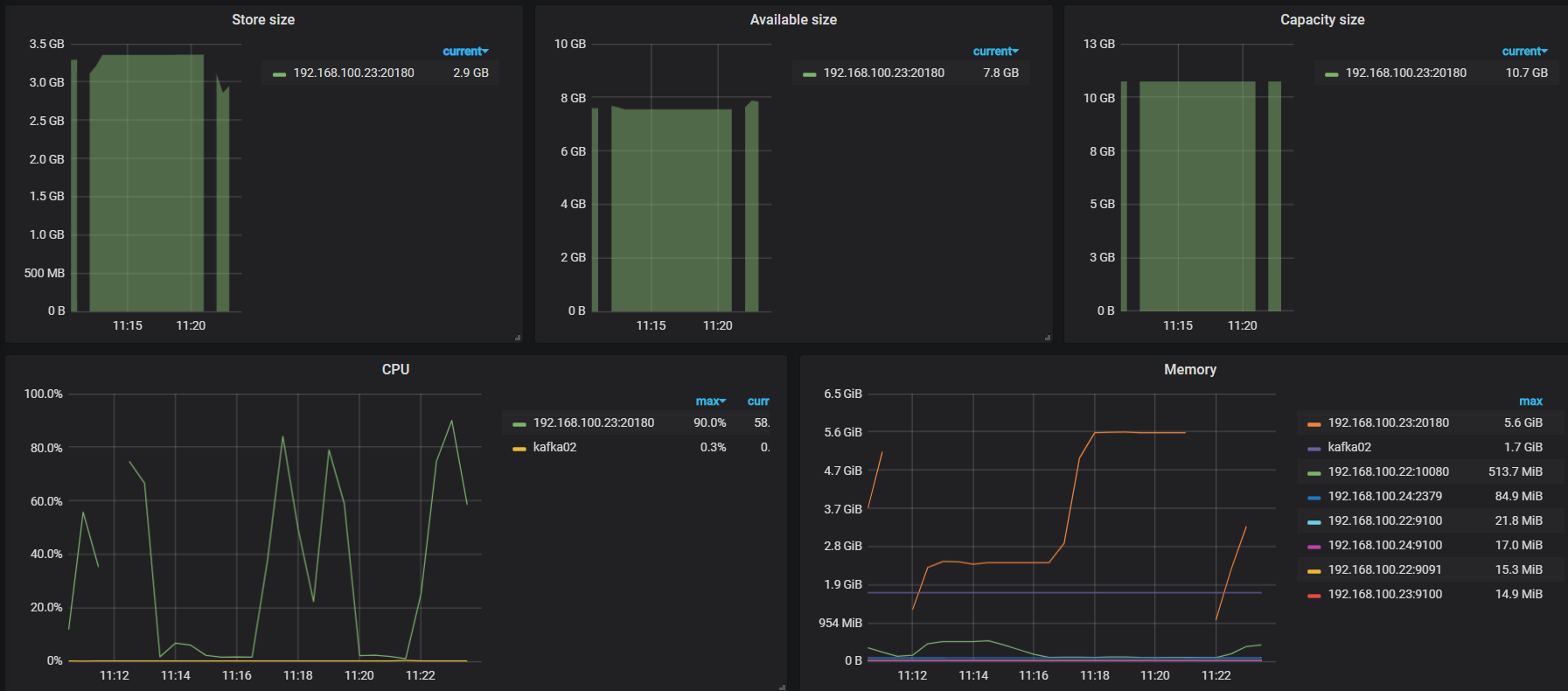
调用TiSpark进行任务时,出现故障TiKV Server timeout 警告 。 然后监控上看到 线条中断 这种 时硬件、 网络原因么 会导致计算数据丢失或者数据拉取不全么?
20/01/19 03:25:57 WARN TaskSetManager: Lost task 42.0 in stage 1.0 (TID 53, 192.168.100.23, executor 3): com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:163)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:140)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:89)
at org.apache.spark.sql.tispark.TiRDD$$anon$2.hasNext(TiRDD.scala:86)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.savePartition(JdbcUtils.scala:653)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:158)
… 25 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:201)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:67)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
… 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: retry is exhausted.
at com.pingcap.tikv.util.ConcreteBackOffer.doBackOff(ConcreteBackOffer.java:127)
at com.pingcap.tikv.operation.KVErrorHandler.handleRequestError(KVErrorHandler.java:247)
at com.pingcap.tikv.policy.RetryPolicy.callWithRetry(RetryPolicy.java:58)
at com.pingcap.tikv.AbstractGRPCClient.callWithRetry(AbstractGRPCClient.java:63)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:547)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:188)
… 7 more
Caused by: com.pingcap.tikv.exception.GrpcException: send tikv request error: UNAVAILABLE, try next peer later
at com.pingcap.tikv.operation.KVErrorHandler.handleRequestError(KVErrorHandler.java:250)
… 11 more
Caused by: shade.io.grpc.StatusRuntimeException: UNAVAILABLE
at shade.io.grpc.stub.ClientCalls.toStatusRuntimeException(ClientCalls.java:210)
at shade.io.grpc.stub.ClientCalls.getUnchecked(ClientCalls.java:191)
at shade.io.grpc.stub.ClientCalls.blockingUnaryCall(ClientCalls.java:124)
at com.pingcap.tikv.AbstractGRPCClient.lambda$callWithRetry$0(AbstractGRPCClient.java:66)
at com.pingcap.tikv.policy.RetryPolicy.callWithRetry(RetryPolicy.java:54)
… 10 more
Caused by: shade.io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: /192.168.100.23:20160
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at shade.io.netty.channel.socket.nio.NioSocketChannel.doFinishConnect(NioSocketChannel.java:323)
at shade.io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.finishConnect(AbstractNioChannel.java:340)
at shade.io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:633)
at shade.io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:580)
at shade.io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:497)
at shade.io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:459)
at shade.io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:858)
at shade.io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:138)
… 1 more
Caused by: java.net.ConnectException: Connection refused
… 11 more
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。