为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:5.7.10-TiDB-v2.1.0-5-g4dad722
- 【问题描述】: 某个tikv的CPU异常。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
异常具体指的?
某个tikv的CPU异常,我现在初步判断不像是热点问题引起的。
一个月前我发帖说我们的某个tikv的CPU负载异常,当时给我的说法就是说有可能是热点问题引起的。
今天我再次来排查这个问题,发现很多指标都不符合热点问题引起的特征,所以我今天来发帖继续来问题这个问题。
现在就通过监控来发现其他的监控指标的各个节点都没什么异常,
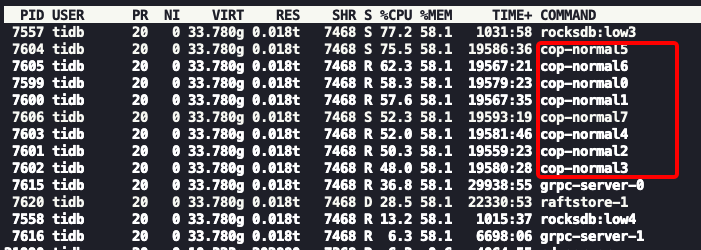
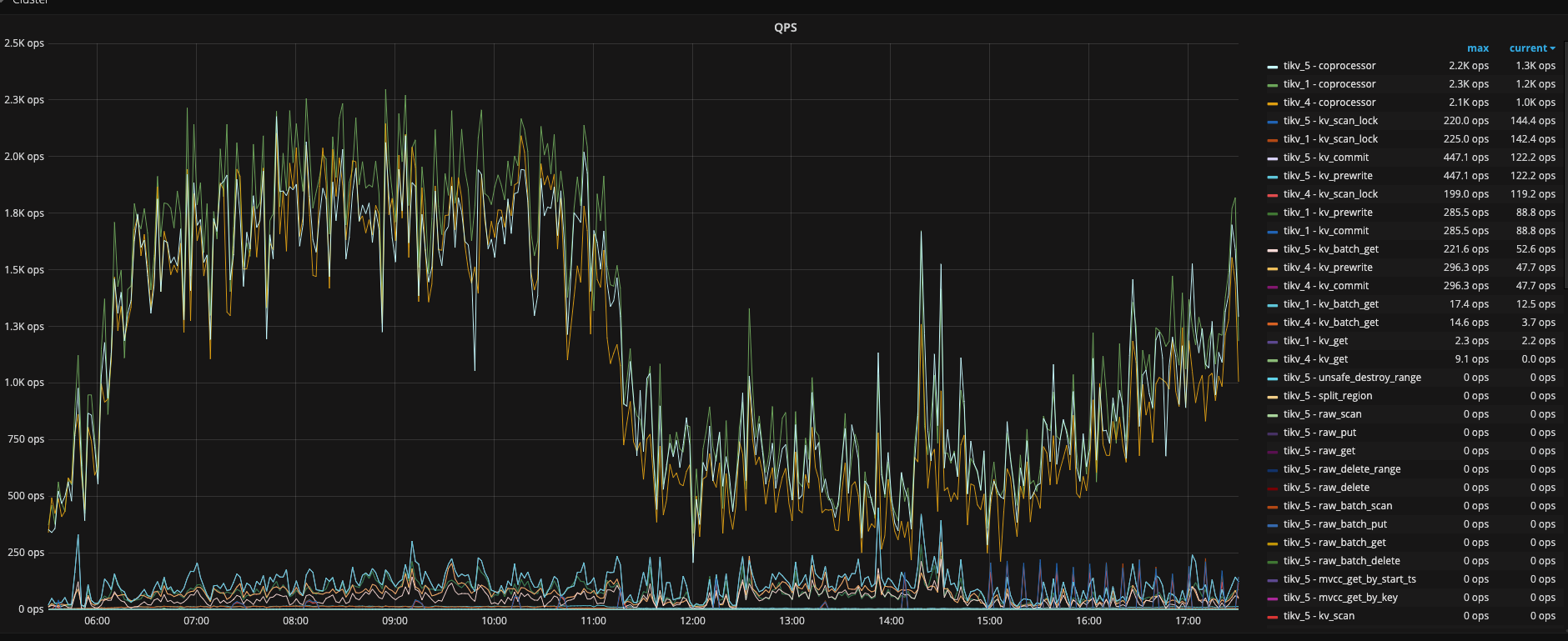
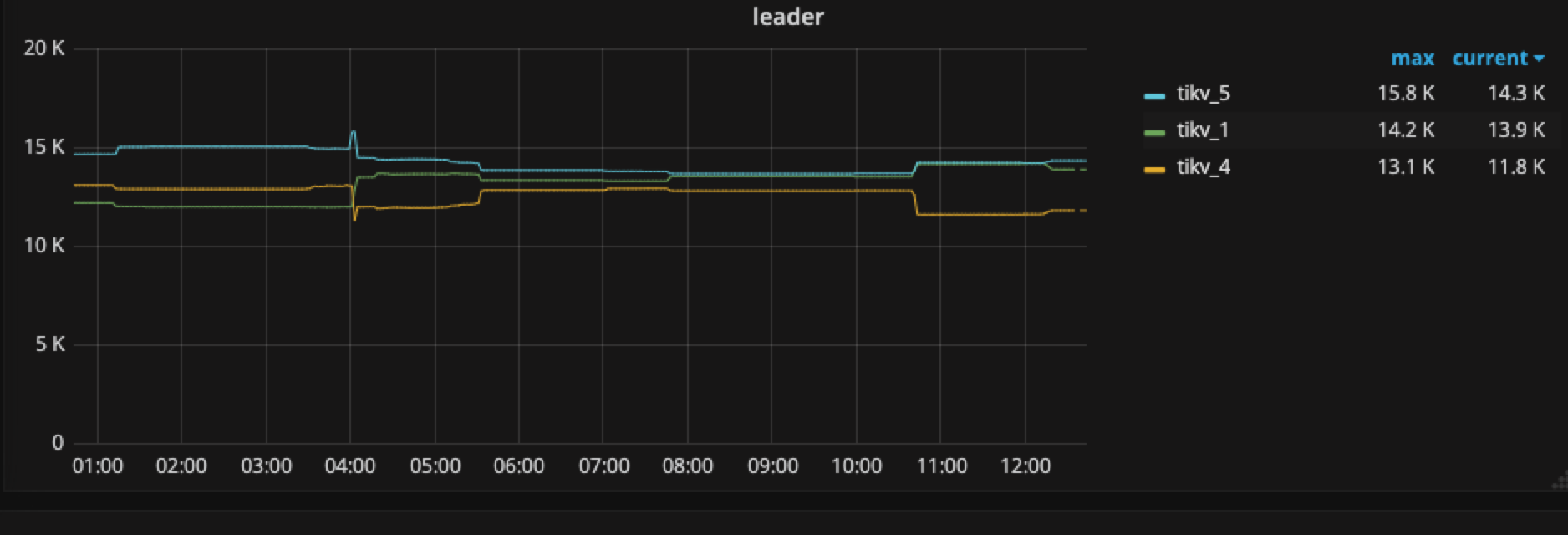
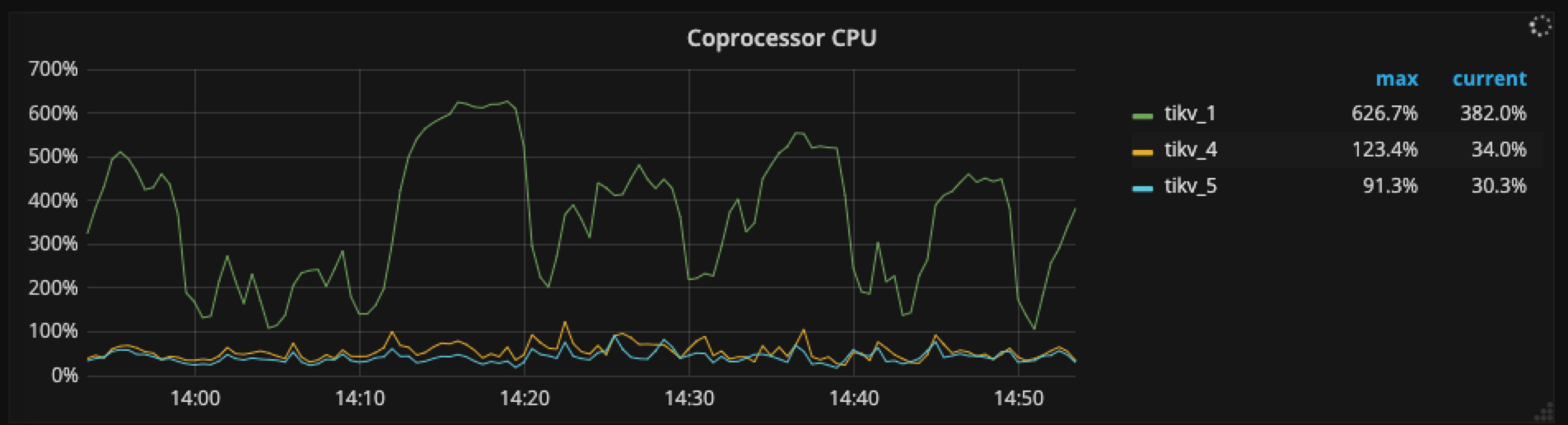
唯独Coprocessor CPU 在tikv1这个节点明显比tikv4,tikv5的CPU要高,而且在tikv的这个节点显示 cop-normalX这种线程占用CPU特高,所以想请问你们一下有可能是什么原因。
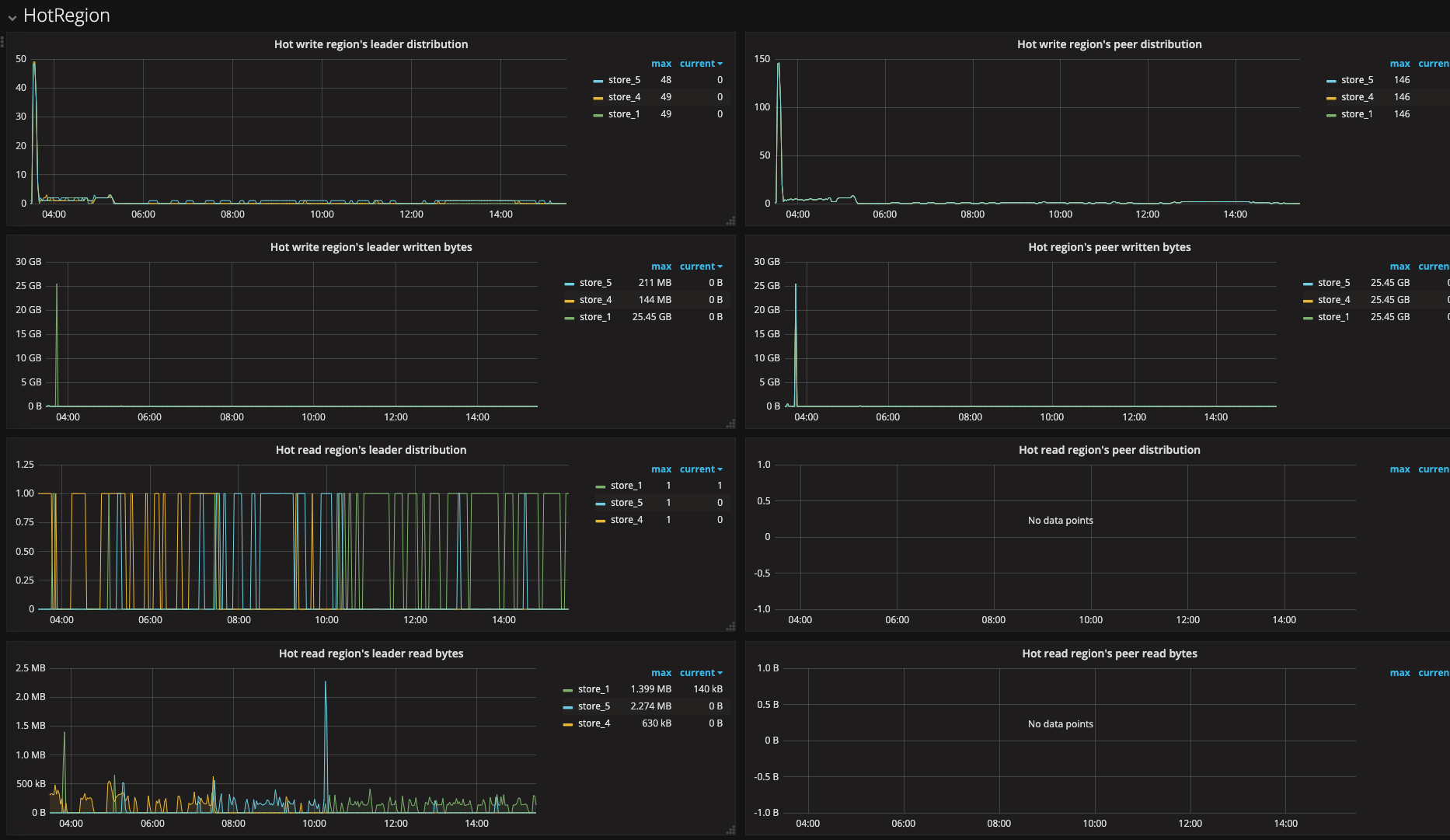
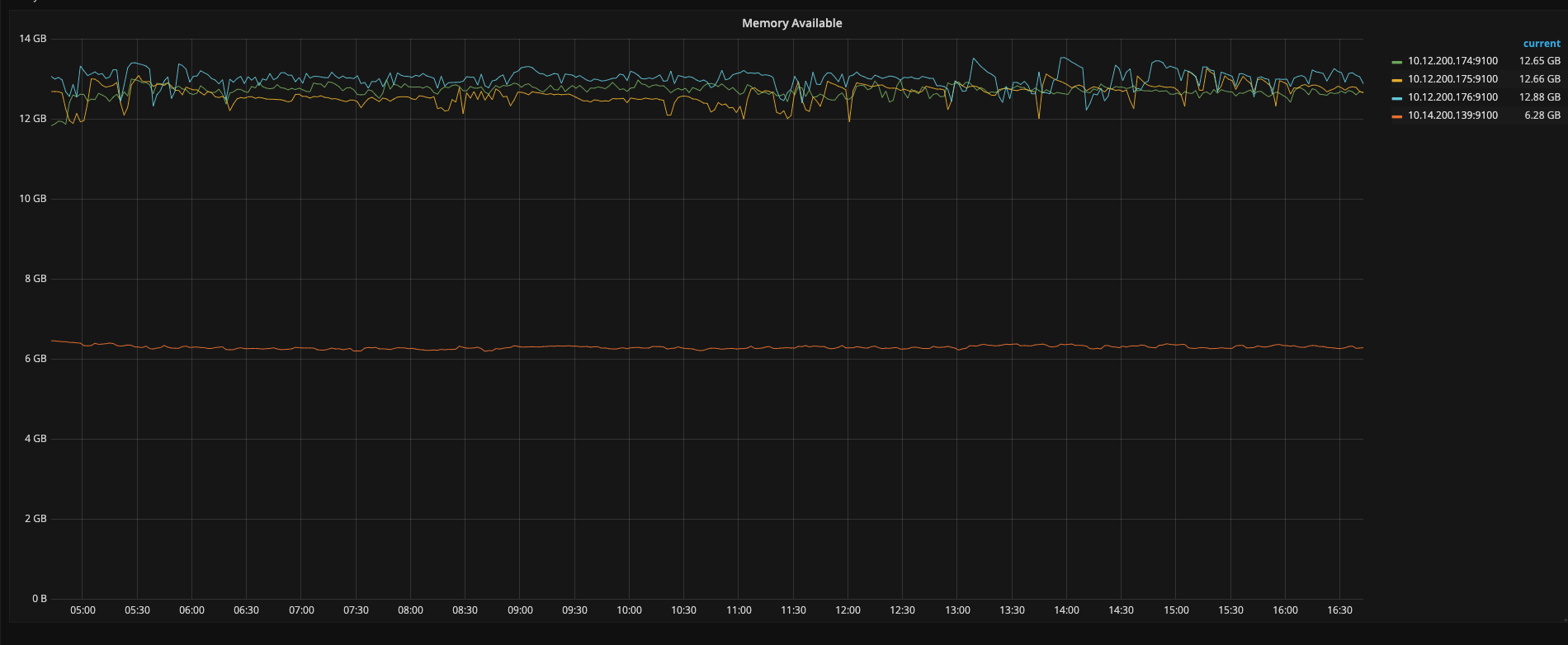
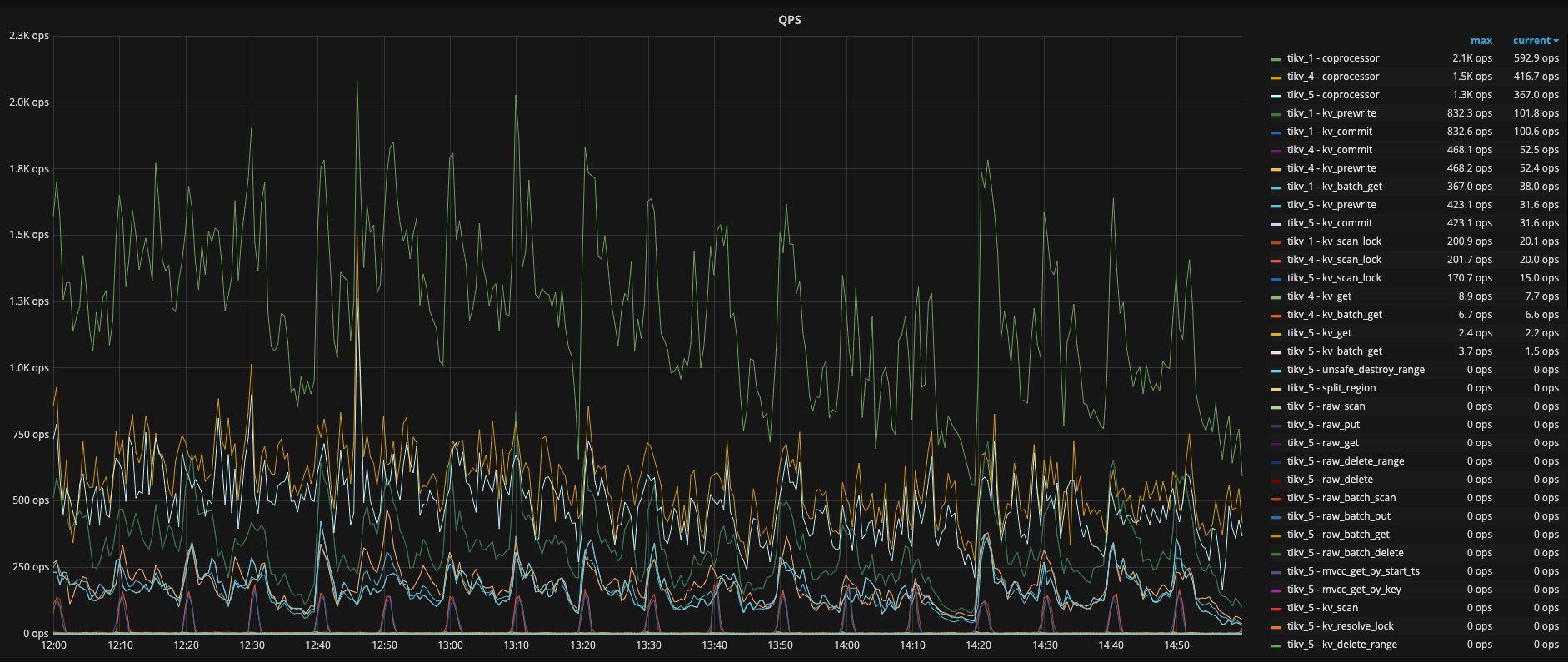
从这张图来年在凌晨3:00〜4:00 之间确实有较多的热点写入,而且 tikv1 与 其他两个有 100 倍的差距,但其他时间段没有看到,也请提供一下 QPS ,CPU,Memory 相关信息,看看是否有访问量上不均衡
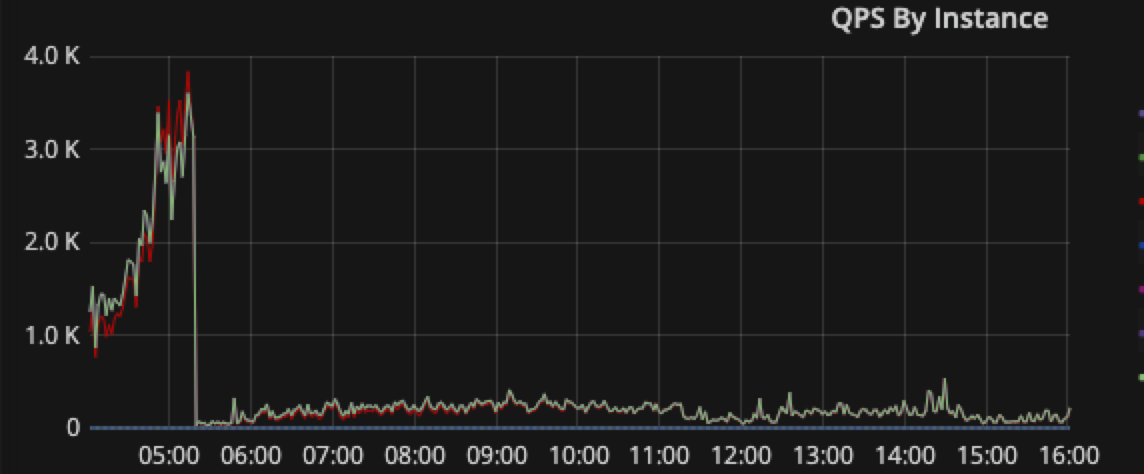
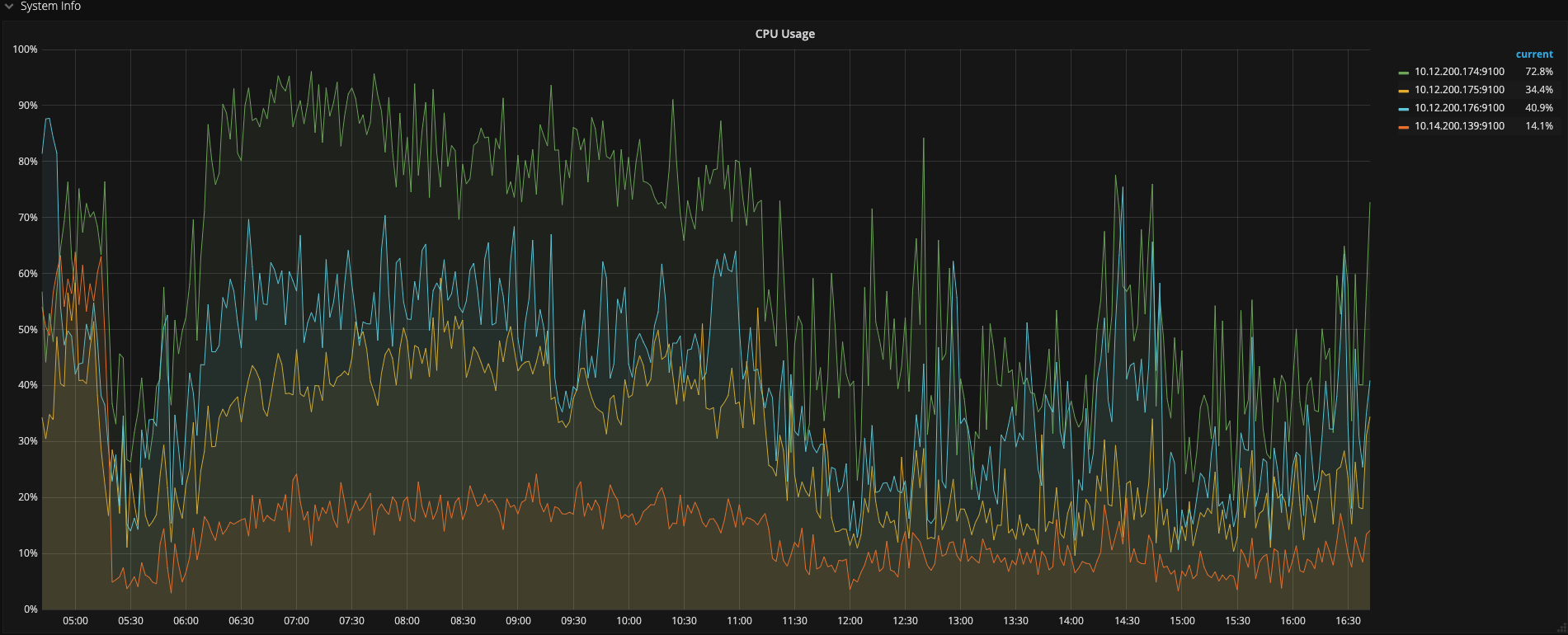
嗯,3〜 4 点能明显看到有写入写点,但之后其实没有看到明显的热点,所有需要从访问量上来看一下,需要提供一下 TiDB 的 QPS、CPU,Memory、网络相关的信息
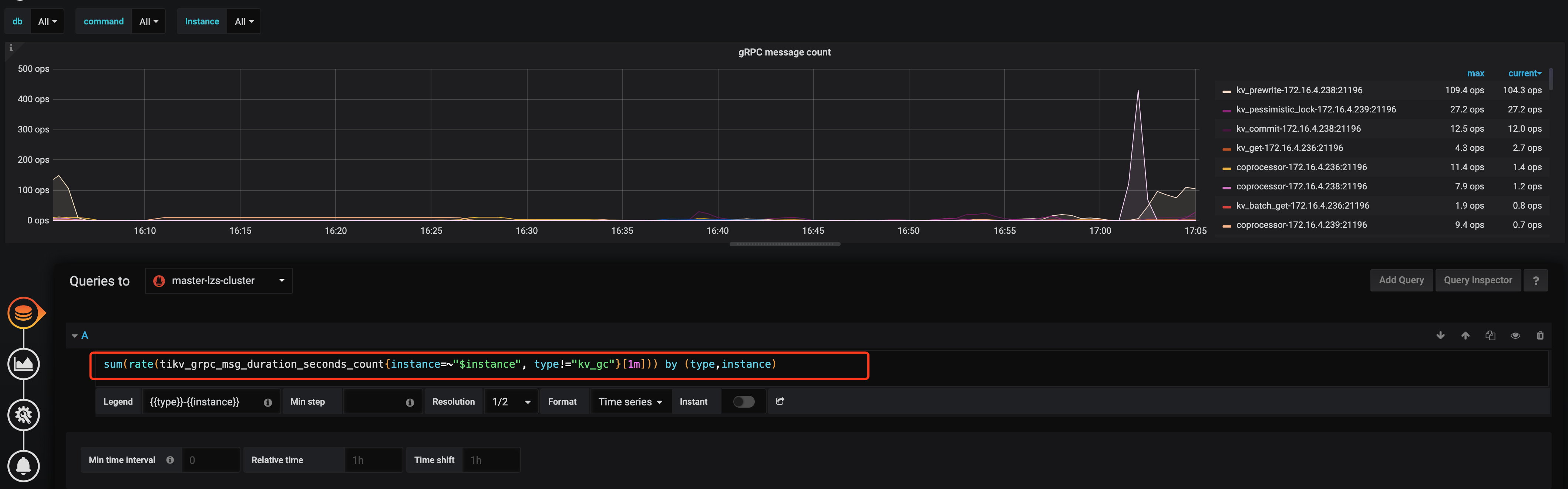
TiKV 监控里 gRPC message count 上的 coprocessor request 的请求分布是否和 CPU 使用的分布对得上,如果是的很可能是因为有读热点造成的编辑一下 grpc message count 的 query 语法
看一下具体是那个 tikv server 导致,然后查看一下 tikv log 里面有没有 slow query 或者 expensive log 的日志,里面会有对应的 table id
然后通过 tidb-ansible/scripts/table-regions.py 脚本查看一下 table region 分布,确认一下分布是否均衡。