Mingdr
(会飞的猫)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:2.1.19,3.0.4,3.0.8我都测试过了,都是一样的。
- 【问题描述】:
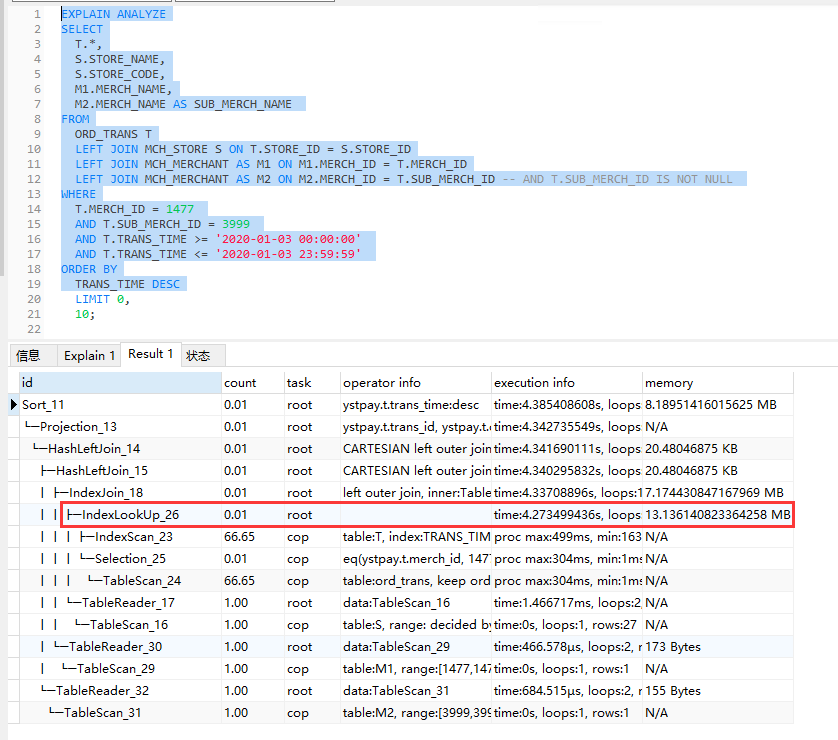
我在查询交易表(每天150w,日期有索引)一天某个商户或者满足某些条件的订单时,使用limit查询,但是无论是否有数据,查询都比较慢。同样的查询在mysql上面,如果满足条件的数据比较多,查询limit 100是很快的,但是在tidb里面,无论有没有数据,都比较慢,如果索引同为b+tree或者类似结构,不应该查询到前100条就结束扫描而不是扫描所有的数据吗
可以看到就算只取前10条都是很慢的,满足该条件的数据是很多的。
而且后台监控有一台kv的coprocesser CPU突然很高。
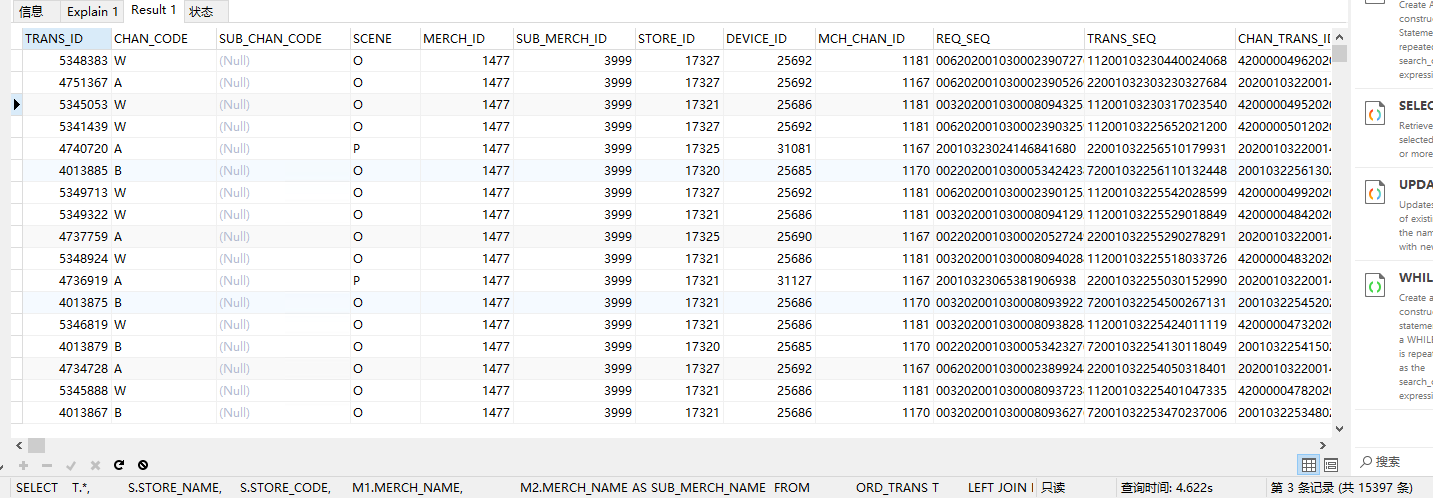
这是查询全部数据
一共1.5w 不分页 ,也才4秒多
看你查询中有 order by 操作,需要进行排序,对于 MySQL 而言底层是 B+ 树结构是有序的,所以扫描值需要按照顺序扫描就行
tidb 中数据存储是无序的,进行 order by 操作的话需要将数据从 tikv 中加载到 tidb 层进行排序
Mingdr
(会飞的猫)
3
但是时间列是有索引的,按理说应该是有序的吧,按照时间列取前十,应该不用扫描所有的行数吧
索引在 tikv 中也是可以 key-value 方式存储的,并不是完全有序的,具体可以参考一下这篇文章
QBin
(Bin)
6
麻烦上传一下完整的 explain analyze 信息(截图里面有些字段信息不全),以及 提供一下相关表的表结构 ( show create table)。
这边看起来是走的索引有点问题,导致执行效率比较低
可以尝试 analyze table 重新收集一下统计信息,然后再测试看下
Mingdr
(会飞的猫)
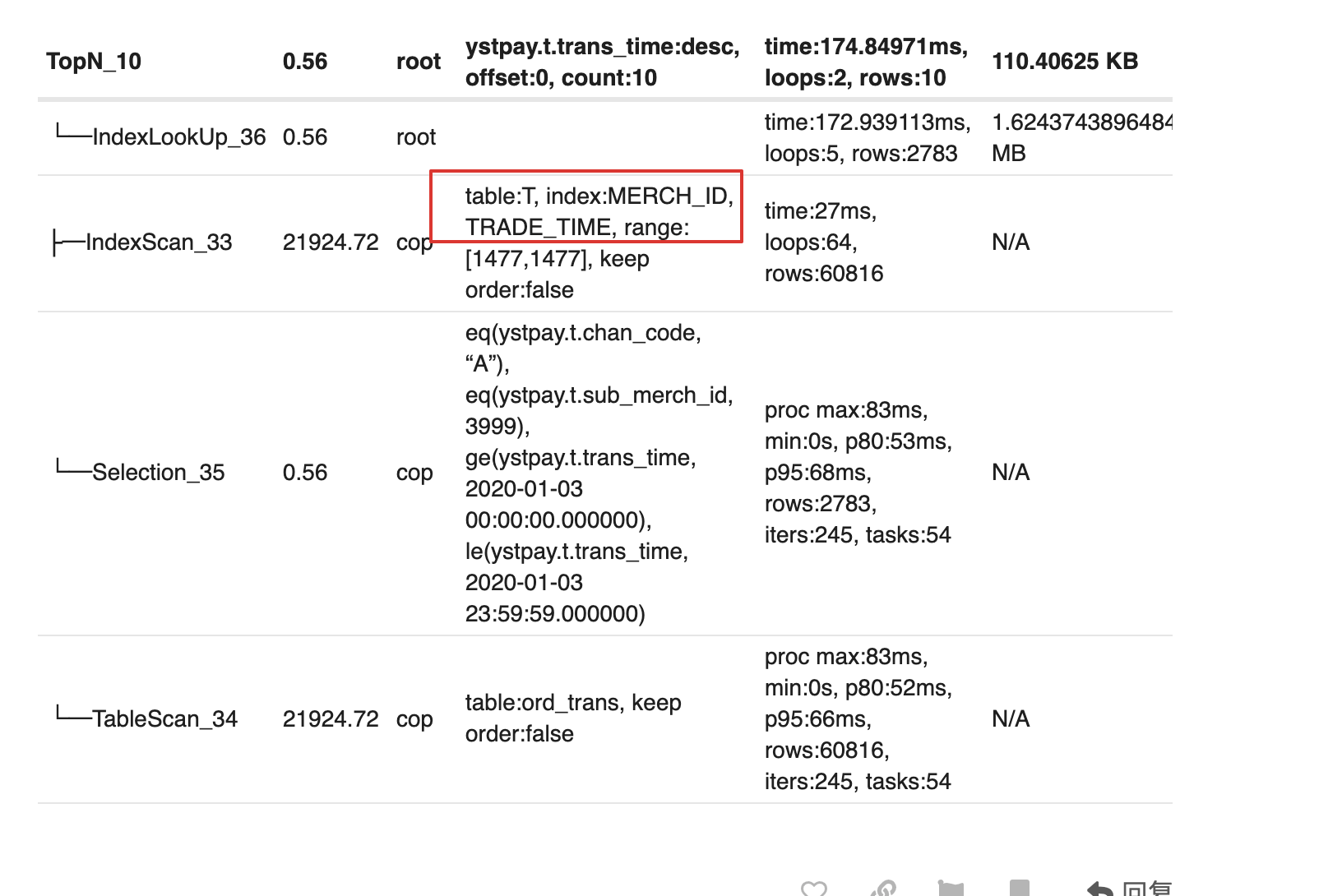
11
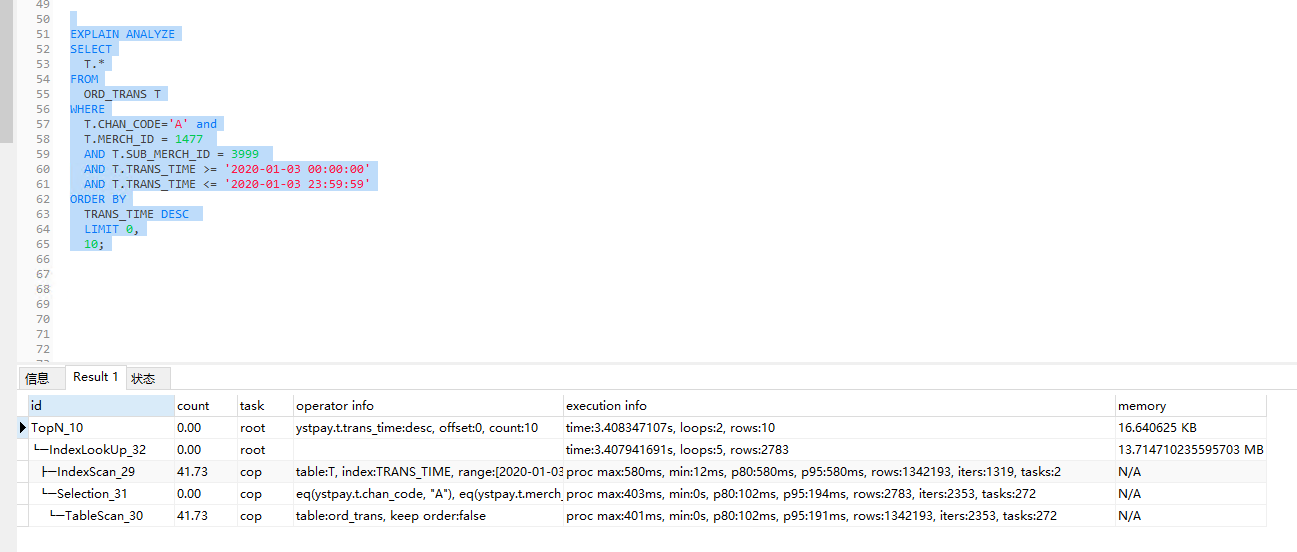
加了组合索引快了些了,但是对于分页查询有些时候还是会比较慢,另外有个问题,在本地执行SQL,显示执行为
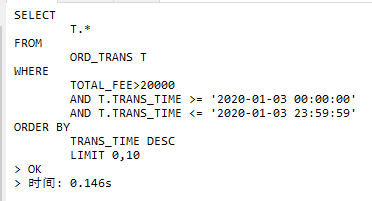
但是显示结果的时间为
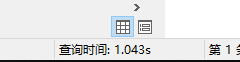
是navicat的原因还是什么呢
可以在命令行中执行 sql 看下时间,是在0.1秒左右还是1秒左右,如果是 0.1 秒左右,可能是 navicat 的问题
Mingdr
(会飞的猫)
13
试了下 ,还真是,谢谢~。
最后有个问题,我们现在读写比例在6:4的样子,怎么设置region的大小合适呢,日增800w左右的数据。
region 大小建议按照默认值即可,如果有遇到性能问题,可以在 TUG 上提帖我们帮助看下
Mingdr
(会飞的猫)
16
请问 raftstore.hibernate-regions ( 实验特性 ) 这个参数在哪儿配置呢,tikv.yml 里面并没有这个参数,版本3.0.8
QBin
(Bin)
17
由于是实验特性的关系,hibernate-regions 这个参数默认是没有暴露出来的。所以需要自己在 raftstore 下面添加
system
(system)
关闭
20
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。