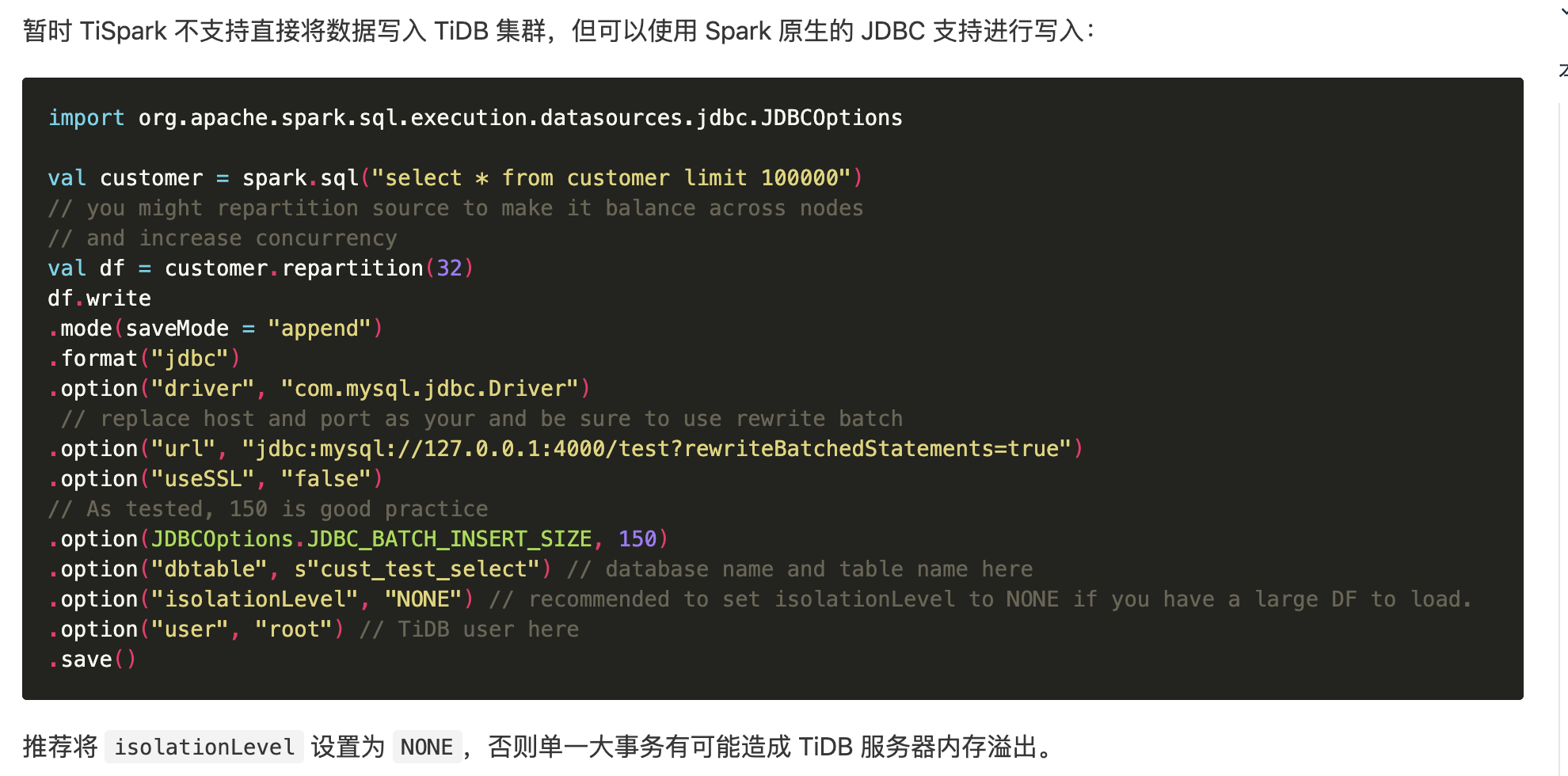
scala> spark.sql(“insert into table poit_dev.test2 select * from poit_dev.test”).show
org.apache.spark.sql.AnalysisException: TiDBRelation(com.pingcap.tikv.TiSession@3a182eaf,TiTableReference(poit_dev,test2,9223372036854775807),com.pingcap.tispark.MetaManager@4bc15d49,null) does not allow insertion.;;
'InsertIntoTable Relation[name#3,age#4L,sex#5] TiDBRelation(com.pingcap.tikv.TiSession@3a182eaf,TiTableReference(poit_dev,test2,9223372036854775807),com.pingcap.tispark.MetaManager@4bc15d49,null), false, false
± Project [name#0, age#1L, sex#2]
± SubqueryAlias test
± Relation[name#0,age#1L,sex#2] TiDBRelation(com.pingcap.tikv.TiSession@3a182eaf,TiTableReference(poit_dev,test,1276),com.pingcap.tispark.MetaManager@4bc15d49,null)
at org.apache.spark.sql.execution.datasources.PreWriteCheck$.failAnalysis(rules.scala:442)
at org.apache.spark.sql.execution.datasources.PreWriteCheck$$anonfun$apply$14.apply(rules.scala:465)
at org.apache.spark.sql.execution.datasources.PreWriteCheck$$anonfun$apply$14.apply(rules.scala:445)
at org.apache.spark.sql.catalyst.trees.TreeNode.foreach(TreeNode.scala:117)
at org.apache.spark.sql.execution.datasources.PreWriteCheck$.apply(rules.scala:445)
at org.apache.spark.sql.execution.datasources.PreWriteCheck$.apply(rules.scala:440)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$checkAnalysis$2.apply(CheckAnalysis.scala:386)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$checkAnalysis$2.apply(CheckAnalysis.scala:386)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$class.checkAnalysis(CheckAnalysis.scala:386)
at org.apache.spark.sql.catalyst.analysis.Analyzer.checkAnalysis(Analyzer.scala:95)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:108)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:105)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:105)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:78)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
… 49 elided