jkb136
(Jkb136)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.8
- 【问题描述】:使用 distinct 查询字段,查询时间过长,进行explain,发现是全表扫描,哪怕是对该字段单独加索引并强制指定索引都不行。
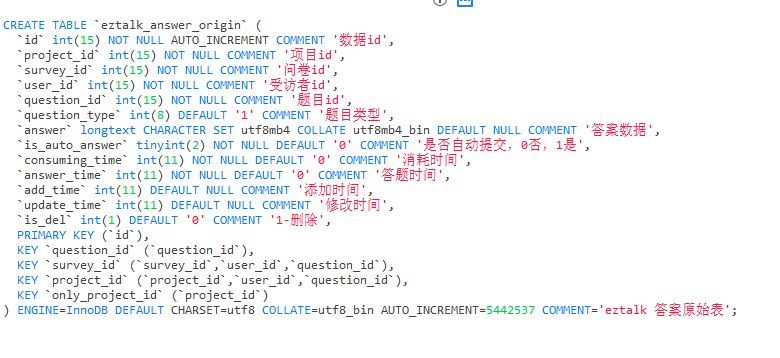
表结构:
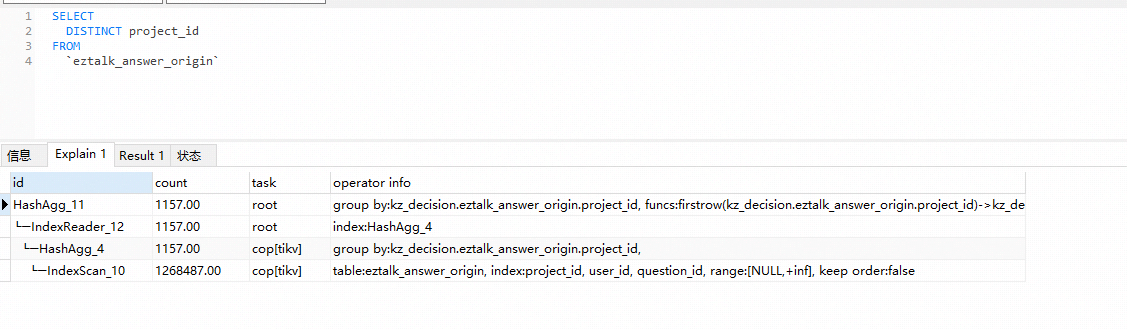
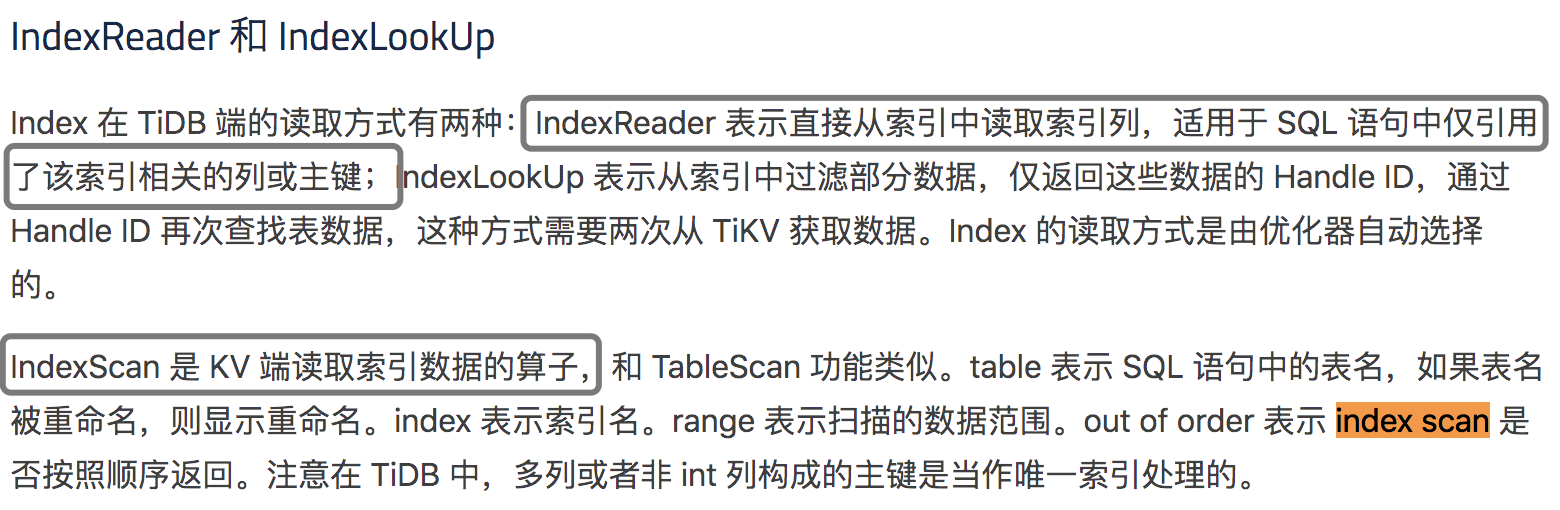
tidb中使用联合索引(project_id,user_id,question_id)查询信息:
可见扫描行数为 126w。
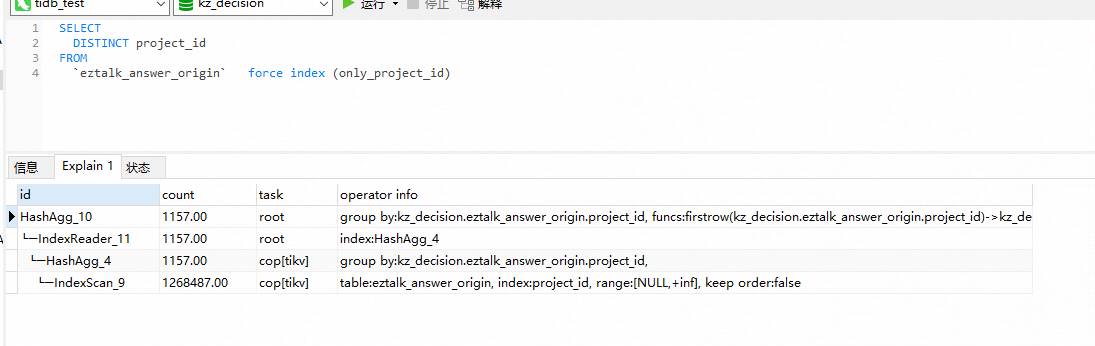
增加project_id的索引并使用查询:
还是扫描126w数据。
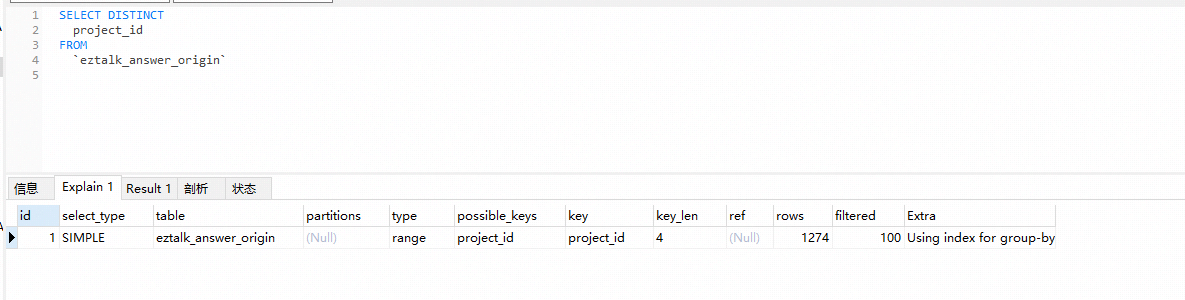
以下为mysql执行过程:
请问如何解决,并且是什么原因导致的呢?
lzb666
(Lzb666)
3
那如果这样说~~单纯是group by 形式也是走全表扫描?那么效率不会存在问题吗?如果是应该怎么避免或者解决?
是否走全表扫描,不是单纯的判断是不是 group by,这个帖子中的执行计划走的是 indexscan ,全表扫描执行计划中显示的应该是 tablescan。
如果是实际遇到的觉得 sql 执行效率不行或者觉得执行计划有误的例子,麻烦新开一个帖子,避免混淆
jkb136
(Jkb136)
5
查阅相关资料了解到,得益于B+树的存储结构,mysql对于某些索引的某些扫描可以使用松散扫描,不用全部扫描,因此能快很多。distinct正符合这种情况。
TIDB存储引擎使用 RocksDB,而RocksDB的索引模型为lsm,所以在对索引字段做distinct时还是需要 indexScan,并且rang为全部。
相关参考资料:https://www.cnblogs.com/pdev/p/11277784.html
https://blog.csdn.net/xtdhqdhq/article/details/18408905
麻烦看一下这样的解释是否是合理的。
lzb666
(Lzb666)
6
那如楼主提问的表结构和sql,如何避免全表扫描或者可以效率更高处理?
这个帖子中走的不是全表扫,是索引扫描,索引扫描会比全表扫快