为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.1
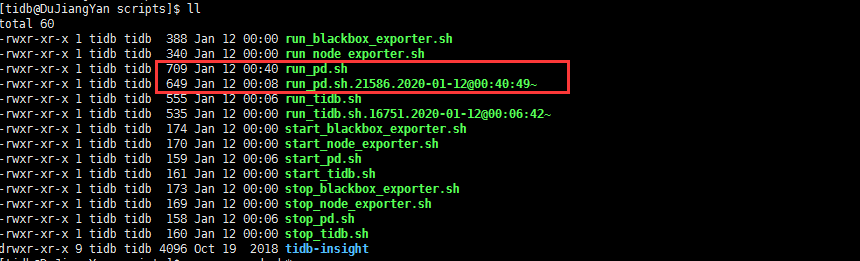
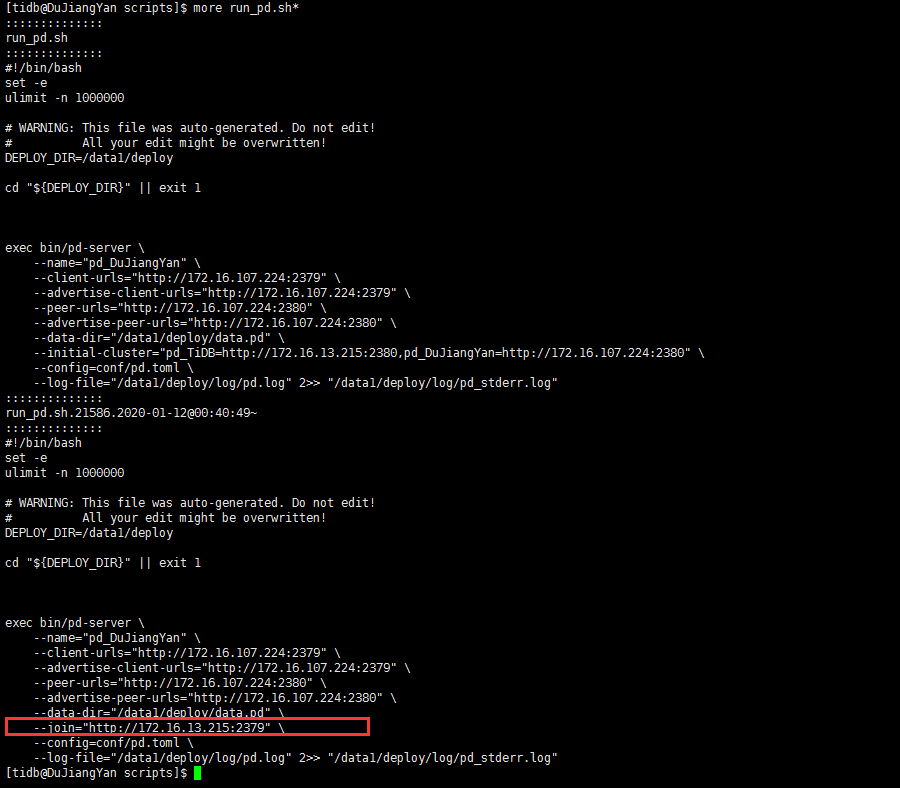
- 【问题描述】:系统原有一个tipd节点,现再扩容一个tipd节点,执行
ansible-playbook rolling_update.yml
报错,错误信息如下
TASK [get PD name] *************************************************************************************************************************************************************************************************************************
fatal: [172.16.107.224]: FAILED! => {“access_control_allow_headers”: “accept, content-type, authorization”, “access_control_allow_methods”: “POST, GET, OPTIONS, PUT, DELETE”, “access_control_allow_origin”: “*”, “changed”: false, “connec
tion”: “close”, “content”: "redirect to not leader
", “content_length”: “23”, “content_type”: “text/plain; charset=utf-8”, “date”: “Sat, 11 Jan 2020 16:14:24 GMT”, “msg”: “Status code was 500 and not [200]: HTTP Error 500: Internal Server Error”, “redirected”: false, “status”: 500, “url”: “http://172.16.107.224:2379/pd/api/v1/members”, “x_content_type_options”: “nosniff”}

这是当时新pd节点服务器的pd.logpd.log.tar.gz (103.5 KB)
请问,扩容报错是什么原因呢
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。