为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.8
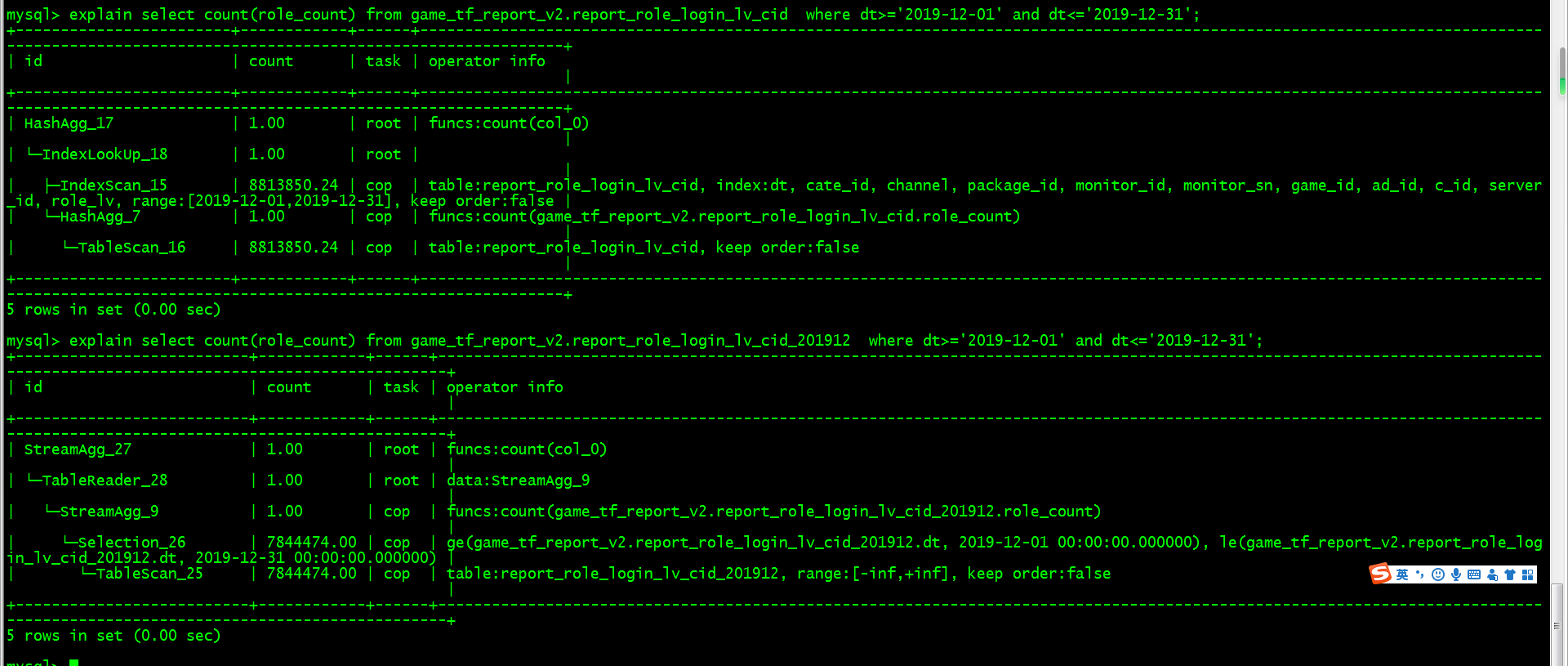
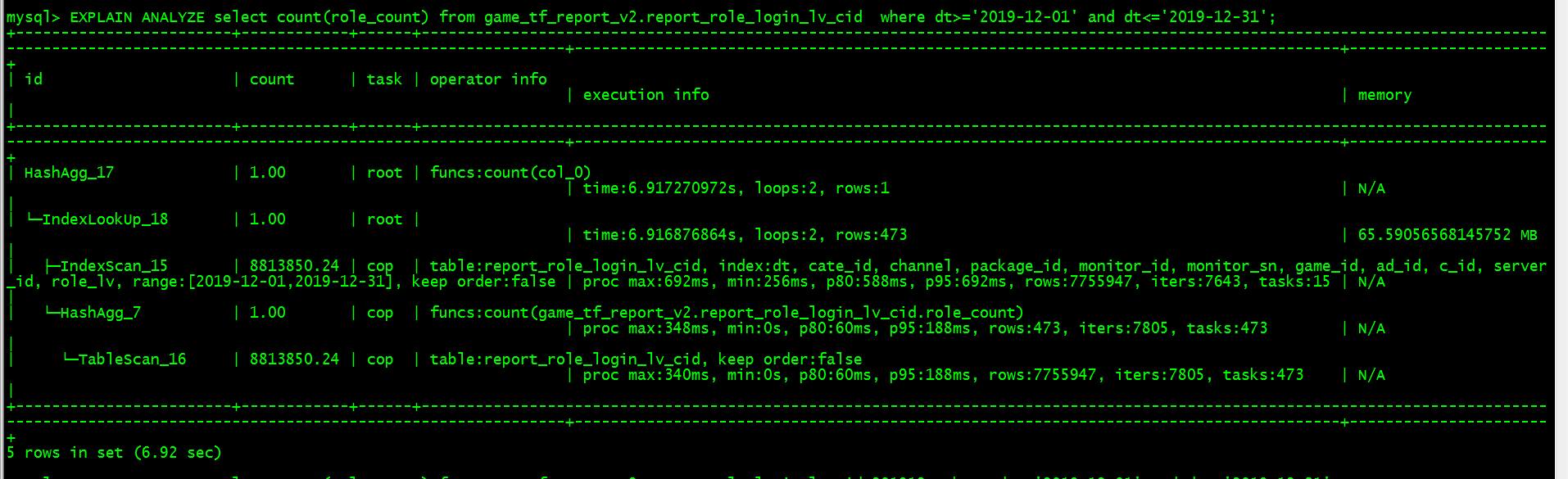
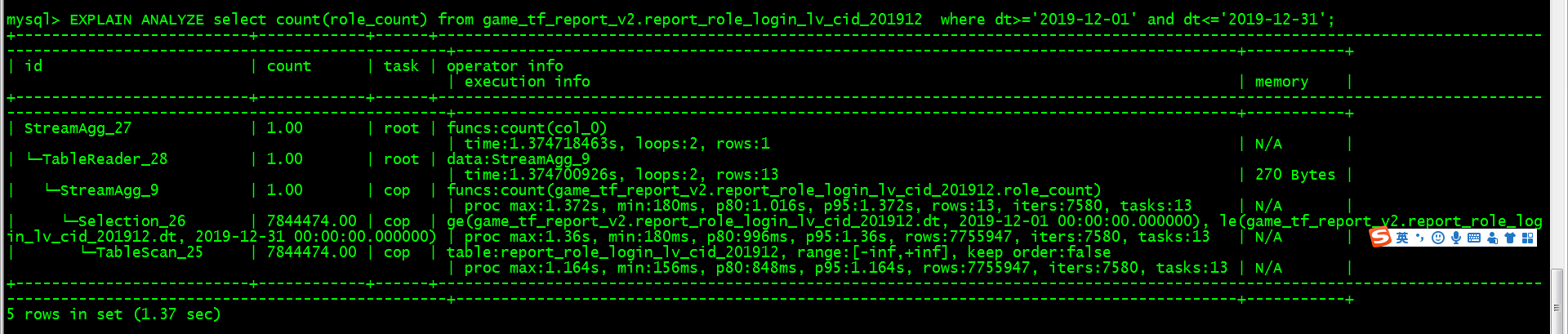
- 【问题描述】:以前mysql 数据量大了就采用按月分表,每月大概100W左右的数据,导入到tidb后,采用一张大表来存储,主键包含dt等多个字段,但在查询过程中,按dt过滤一个月的数据求count 非索引字段,大表耗时太长,在7秒左右,count 结果为 7755947,同样tidb查这个月的分表 也是count 非索引字段,耗时只需要1秒多一点。想知道该怎么优化tikv或tidb的配置,按理说大表的查询速度不应该这么慢才对呢?
补充:大表总数据量103985543
集群配置: PD:3 tikv : 3*2
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
yilong
(yi888long)
2
请把具体的sql发出来,使用explain和EXPLAIN ANALYZE 反馈下这个sql的结果,多谢
yilong
(yi888long)
6
请帮忙查看以下统计信息. https://pingcap.com/docs-cn/stable/reference/performance/statistics/#查看-analyze-状态
(1)show stats_healthy where table_name=‘report_role_login_lv_cid’; (2) SHOW STATS_META where table_name=‘report_role_login_lv_cid’; (3)
yilong
(yi888long)
11
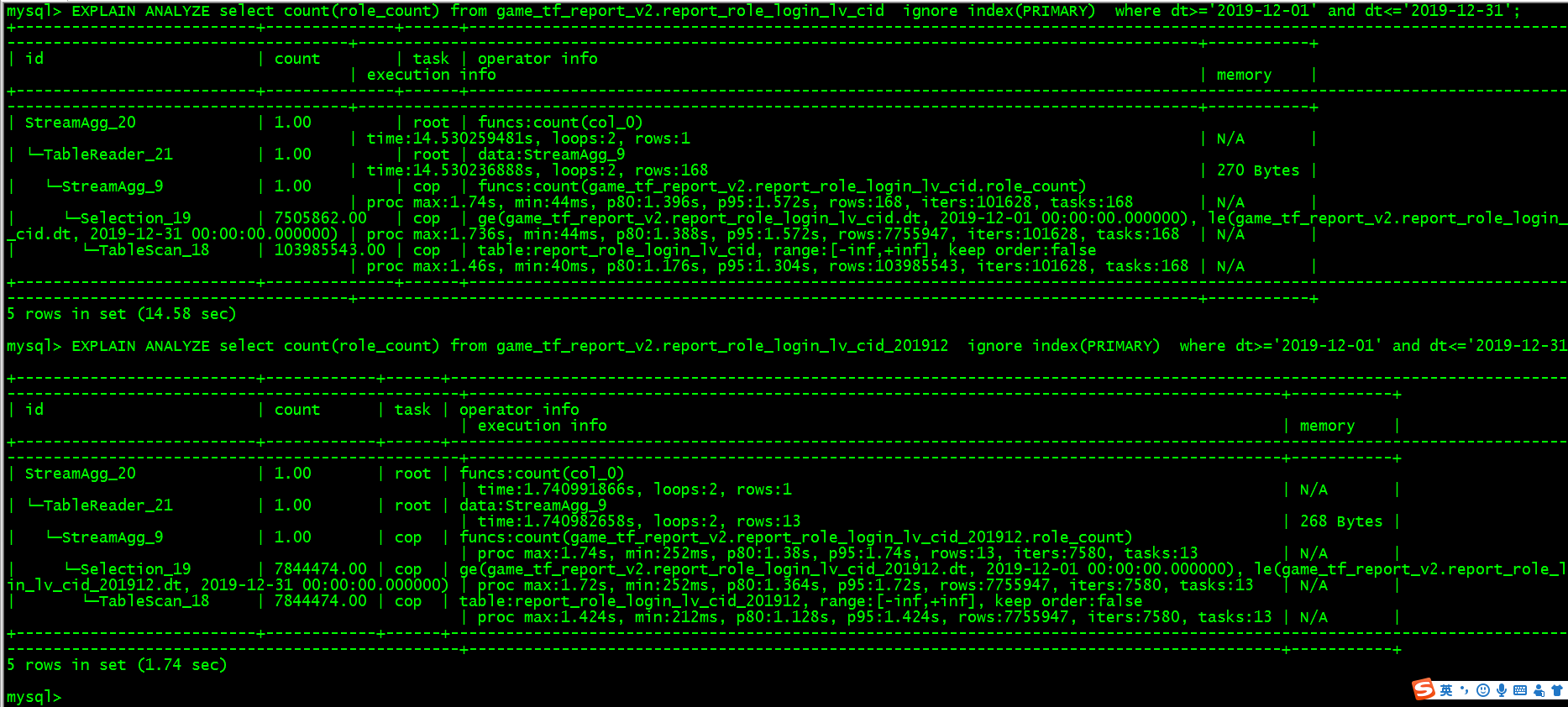
把这个索引名称改为你的索引名,请在业务低峰期尝试,多谢
explain analyze select … from tbl_name ignore index(primary);
你好,两张表都只有主键索引,忽略主键索引查询更慢,另外,role_count列没有null值
您好,请问,能不能加个qq 来帮我解决一下这个问题,帖子上的沟通效率太低了,这个问题比较急
请加 我qq:939712761
@XuHuaiyu-PingCAP @rongyilong-PingCAP @Bin-PingCAP
yilong
(yi888long)
19
您好:
请帮忙收集一下show table table_name regions 这个表的region信息,多谢