为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:2.1.19
- 【问题描述】:在日常监控中,PD面板上两个监控指标数据不太正常,能否帮忙提供一下排查思路。
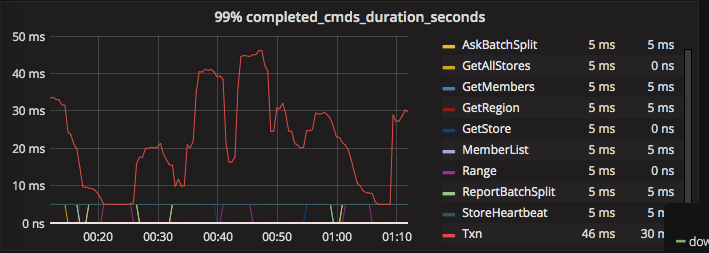

目前TiDB开启了region merge功能,正在进行merge。并且TIDB日志中存在get timestamp too slow现象。
多谢
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
目前TiDB开启了region merge功能,正在进行merge。并且TIDB日志中存在get timestamp too slow现象。
多谢
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
这个和开启 region merge 关系不大,见按照一下流程检查:
确认一下磁盘读写是否有延迟 ? 可以通过 disk-performance 的 dashboard 里面的,通过 disk latency 和 disk load 以及 I/O util 确认磁盘的读写延迟情况,从告警看是从 etcd 读取的信息超时了,这个超时有可能读性能有关系。可以将 PD transfer 到其他的 follower 验证一下,transfer 操作可以通过 pd-ctl 来完成。具体见官方文档。