为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
版本:v5.1.1
集群:3PD(8vCore32G),3TIDB(16vcore64G),11TIKV(16vcore128G),8TIFLASH(16vcore128G)
【概述】
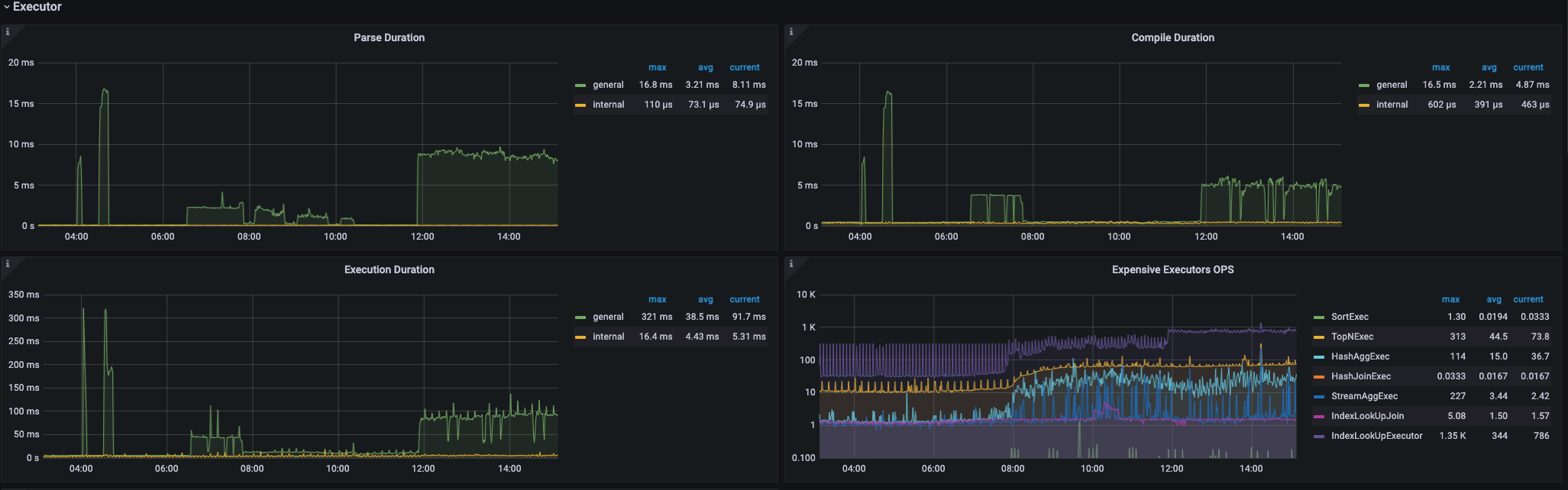
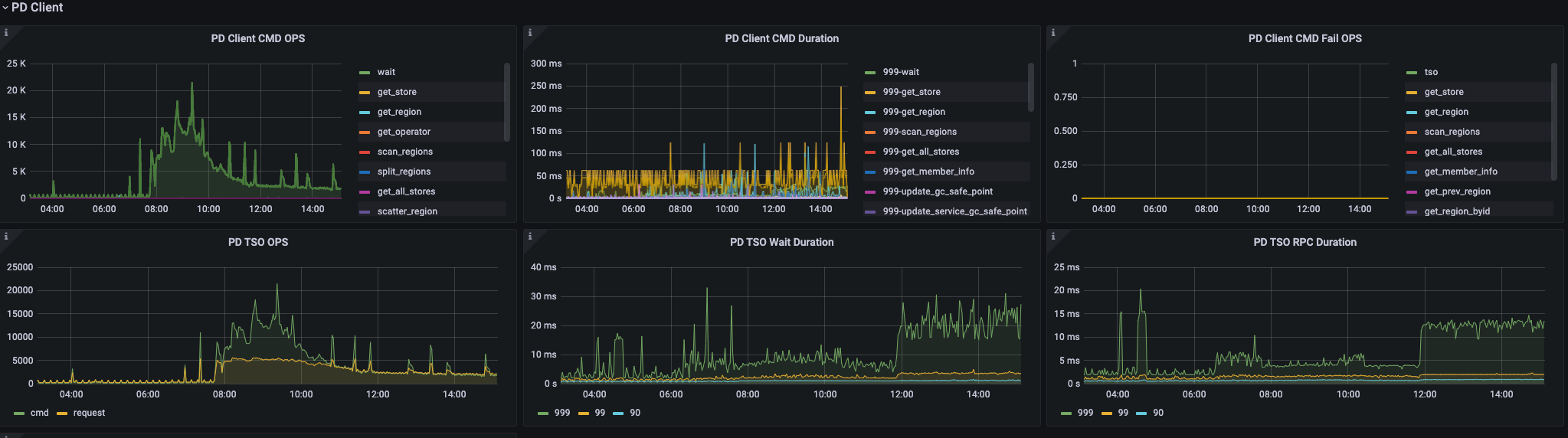
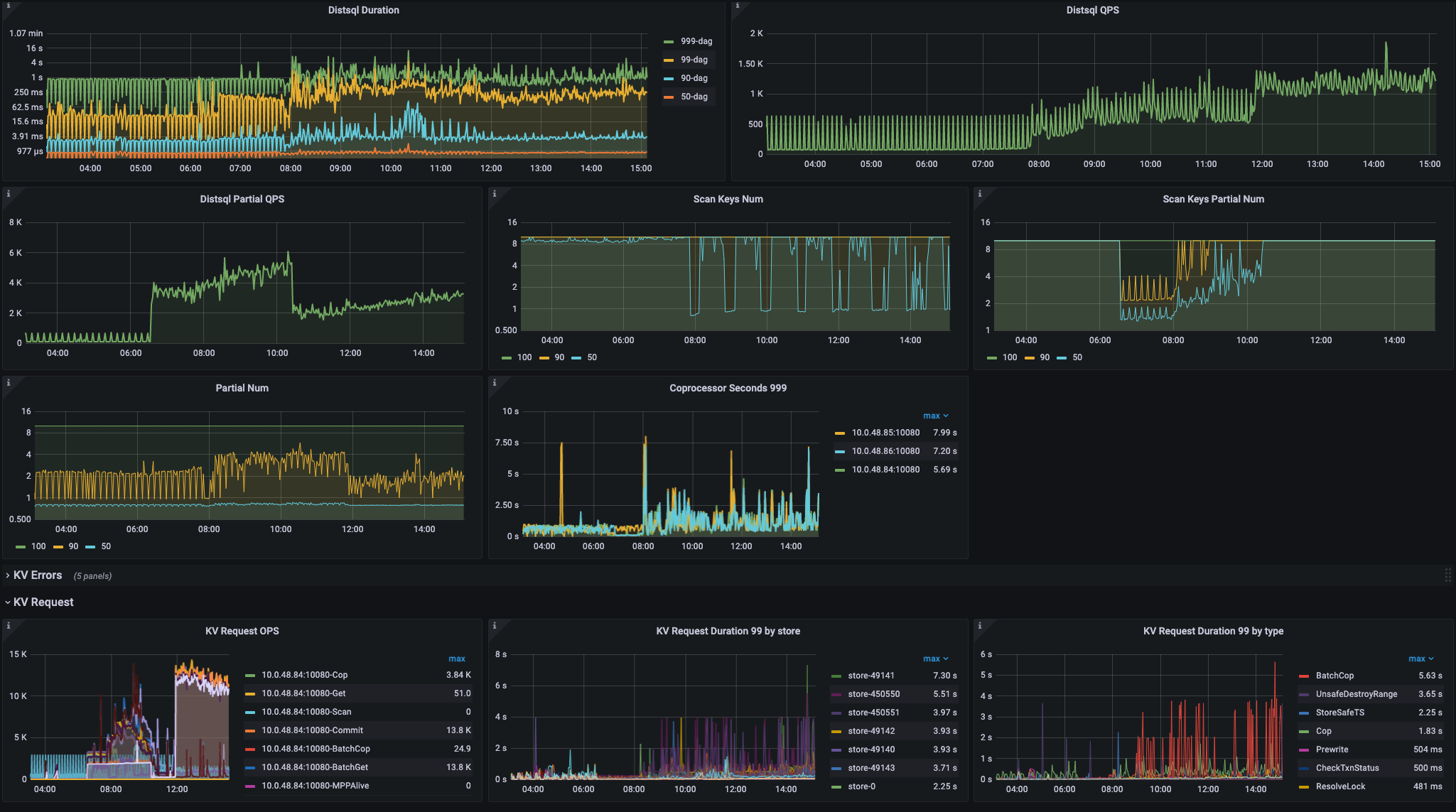
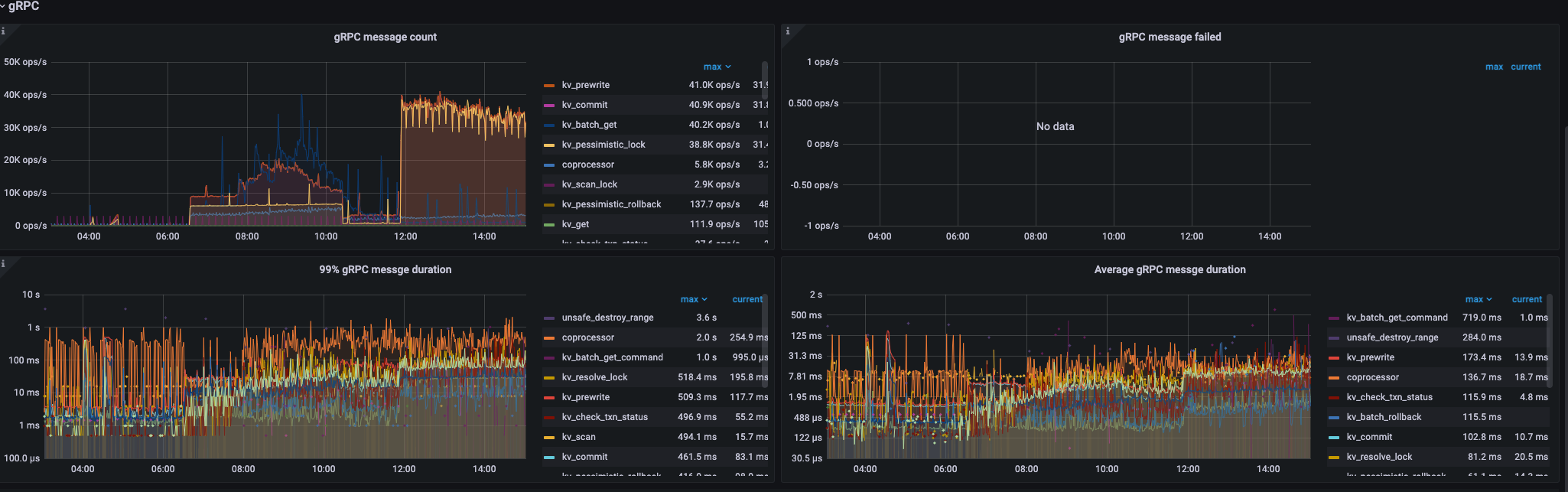
您好,我们有一张30亿数据带update_timestamp索引和一个tiflash副本的表需要每天upsert写入1亿数据,同时根据update_timestamp读取更新记录,目前的做法是基于spark+jdbc写数据到集群。主要的问题点在于 我们只想更新非空字段到DB中(INSERT INTO table (columns) values (columnValues) ON DUPLICATE KEY UPDATE column = IFNULL(values(column),column),… ),这样写入性能远远达不到要求(30core,1亿数据,BatchSize为200,20个字段,需要5h写完,且集群的CPU、IO都没有达到高峰)。想要问一下在 保留非空字段不更新 的条件下是否有优化手段?