count 语句
select
count(1)
from (
SELECT
/*+ read_from_storage(tiflash[hgl_je_line]),agg_to_cop() */
count(je_line_id)
FROM
hgl_je_line
WHERE
tenant_id = 0
AND ledger_code = ‘0L’
AND period_num <= right(‘2021-09’, 2)
AND period_num >= 0
AND period_year = left(‘2021-06’, 4)
AND posted_status = ‘P’
AND company_code >= ‘1000’
AND company_code <= ‘1000’
AND account >= ‘10010101’
AND account <= ‘99999995’
GROUP BY
ledger_code,
account,
company_code,
lc_currency_code,
segment21,
segment20,
segment19,
segment18,
segment17,
segment16,
segment12,
segment11,
segment15
) a
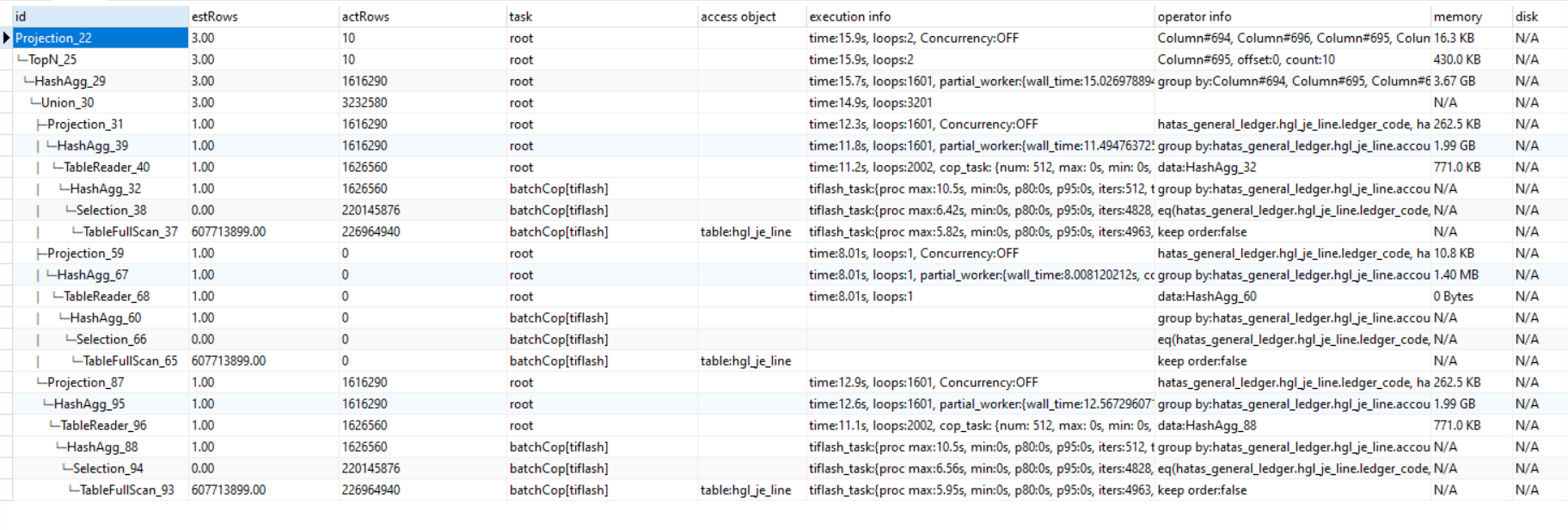
count 执行计划
查询数据
SELECT
ledger_code,
company_code,
account,
lc_currency_code,
sum(lc_accounted_dr_start) AS lc_accounted_dr_start,
sum(lc_accounted_cr_start) AS lc_accounted_cr_start,
sum(lc_accounted_dr_period) AS lc_accounted_dr_period,
sum(lc_accounted_cr_period) AS lc_accounted_cr_period,
sum(lc_accounted_dr_end) AS lc_accounted_dr_end,
sum(lc_accounted_cr_end) AS lc_accounted_cr_end,
segment21,
segment20,
segment19,
segment18,
segment17,
segment16,
segment12,
segment11,
segment15
FROM
(
SELECT
/*+ read_from_storage(tiflash[hgl_je_line]),agg_to_cop() /
ledger_code,
account,
company_code,
lc_currency_code,
0 AS lc_accounted_dr_start,
0 AS lc_accounted_cr_start,
sum(lc_accounted_dr) AS lc_accounted_dr_period,
sum(lc_accounted_cr) AS lc_accounted_cr_period,
0 AS lc_accounted_dr_end,
0 AS lc_accounted_cr_end,
segment21,
segment20,
segment19,
segment18,
segment17,
segment16,
segment12,
segment11,
segment15
FROM
hgl_je_line
WHERE
tenant_id = 0
AND ledger_code = ‘0L’
AND period_num >= 6
AND period_num <= 9
AND period_year = 2021
AND posted_status = ‘P’
AND company_code >= ‘1000’
AND company_code <= ‘1000’
AND account >= ‘10010101’
AND account <= ‘99999995’
GROUP BY
ledger_code,
account,
company_code,
lc_currency_code,
segment21,
segment20,
segment19,
segment18,
segment17,
segment16,
segment12,
segment11,
segment15
UNION ALL
SELECT
/+ read_from_storage(tiflash[hgl_je_line]),agg_to_cop() /
ledger_code,
account,
company_code,
lc_currency_code,
sum(lc_accounted_dr) AS lc_accounted_dr_start,
sum(lc_accounted_cr) AS lc_accounted_cr_start,
0 AS lc_accounted_dr_period,
0 AS lc_accounted_cr_period,
0 AS lc_accounted_dr_end,
0 AS lc_accounted_cr_end,
segment21,
segment20,
segment19,
segment18,
segment17,
segment16,
segment12,
segment11,
segment15
FROM
hgl_je_line
WHERE
tenant_id = 0
AND ledger_code = ‘0L’
AND period_num >= 0
AND period_num <= 5
AND period_year = 2021
AND posted_status = ‘P’
AND company_code >= ‘1000’
AND company_code <= ‘1000’
AND account >= ‘10010101’
AND account <= ‘99999995’
GROUP BY
ledger_code,
account,
company_code,
lc_currency_code,
segment21,
segment20,
segment19,
segment18,
segment17,
segment16,
segment12,
segment11,
segment15
UNION ALL
SELECT
/+ read_from_storage(tiflash[hgl_je_line]),agg_to_cop() */
ledger_code,
account,
company_code,
lc_currency_code,
0 AS lc_accounted_dr_start,
0 AS lc_accounted_cr_start,
0 AS lc_accounted_dr_period,
0 AS lc_accounted_cr_period,
sum(lc_accounted_dr) AS lc_accounted_dr_end,
sum(lc_accounted_cr) AS lc_accounted_cr_end,
segment21,
segment20,
segment19,
segment18,
segment17,
segment16,
segment12,
segment11,
segment15
FROM
hgl_je_line
WHERE
tenant_id = 0
AND ledger_code = ‘0L’
AND period_num >= 0
AND period_num <= 9
AND period_year = 2021
AND posted_status = ‘P’
AND company_code >= ‘1000’
AND company_code <= ‘1000’
AND account >= ‘10010101’
AND account <= ‘99999995’
GROUP BY
ledger_code,
account,
company_code,
lc_currency_code,
segment21,
segment20,
segment19,
segment18,
segment17,
segment16,
segment12,
segment11,
segment15
) a
GROUP BY
ledger_code,
account,
company_code,
lc_currency_code,
segment21,
segment20,
segment19,
segment18,
segment17,
segment16,
segment12,
segment11,
segment15
ORDER BY
account ASC
查询数据 执行计划