Bug 反馈
清晰准确地描述您发现的问题,提供任何可能复现问题的步骤有助于研发同学及时处理问题
【 Bug 的影响】
ticdc 经常出现不能选 owner ,任何cdc操作比如 pause resume update等 都不能执行成功。
下游同步时间点 长期停滞 。
【可能的问题复现步骤】
一般是 下游同步异常报错的时候 容易出现 这种 不能选举owner的情况 。
可以drop 下游的某张表 ,引起ticdc报错 。
【看到的非预期行为】
监控图里 ownership history 里 current 为空
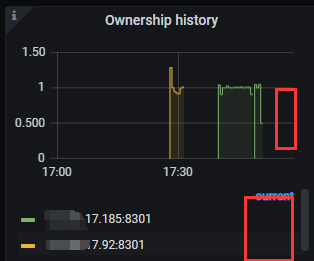
【期望看到的行为】
期望看到 owner 能稳定 ,即使出问题 也能快速重新选举 。
现在只能是 杀掉了或重启 之前的owner 才能重新选举 。
【相关组件及具体版本】
ticdc 5.1.2 tidb 5.1.2
【其他背景信息或者截图】
如集群拓扑,系统和内核版本,应用 app 信息等;如果问题跟 SQL 有关,请提供 SQL 语句和相关表的 Schema 信息;如果节点日志存在关键报错,请提供相关节点的日志内容或文件;如果一些业务敏感信息不便提供,请留下联系方式,我们与您私下沟通。
1 个赞
grafana界面没有显示owner,简单的cdc同步都无法进行下去,这种是bug的可能性很小,毕竟是一款已经GA的产品
可以去ticdc上确认下:
1)查看processor的状态
2)查看下 changefeed的状态
3)查询下cdc的日志
1 个赞
可以把你的changefeed配置发下和cdc相关的grafana指标发下。
1 个赞
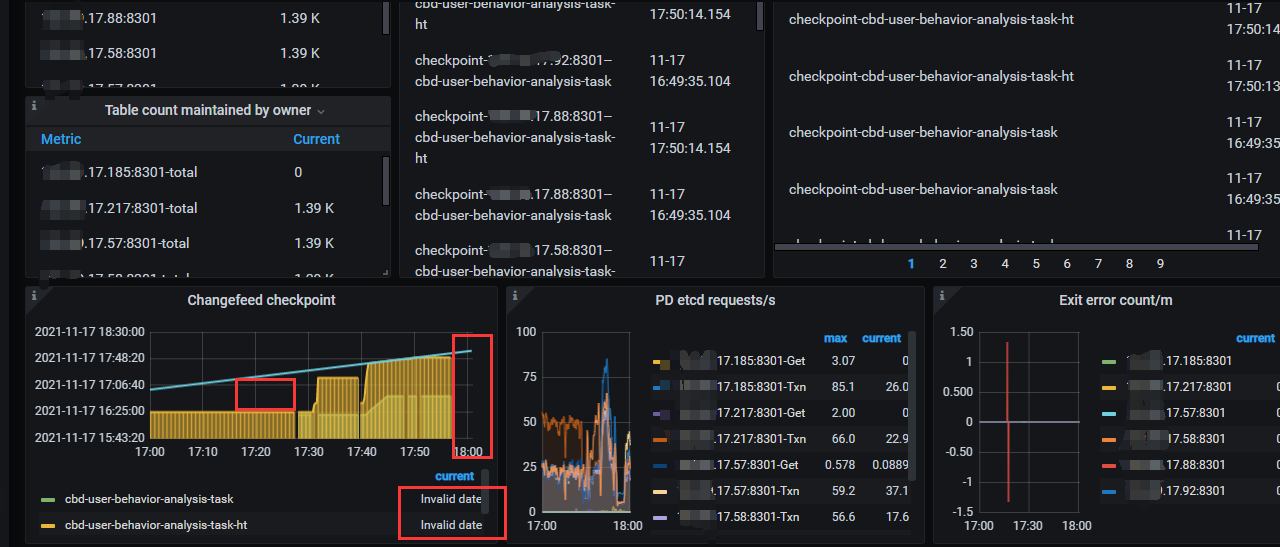
cbd_user_behavior_analysis.toml
# 指定配置文件中涉及的库名、表名是否为大小写敏感
# 该配置会同时影响 filter 和 sink 相关配置,默认为 true
case-sensitive = true
#force-replicate = true
[filter]
rules = ['cbd_user_behavior_analysis.*','!cbd_user_behavior_analysis.t_ssp_ad_log_error_202*','!cbd_user_behavior_analysis.tbl_user_cheat_appopen','!cbd_user_beha
vior_analysis.tbl_effect_click_20210*','!cbd_user_behavior_analysis.tbl_effect_click_202110*','!cbd_user_behavior_analysis.tbl_new_ssp_ad_log_20210*']
#ddl-allow-list = "create table"
#ddl-allow-list = ["create table","drop table","alter table"]
[mounter]
# mounter 线程数,用于解码 TiKV 输出的数据
worker-num = 16
[sink]
protocol = "default"
[cyclic-replication]
# 是否开启环形同步
enable = false
sync-ddl = true
----------ticdc日志 ---------------------------
17.185 曾经是 owner , 异常之后我 重启ticdc进程 ,显示进程重启成功了 ,但是日志 一直卡在这 17:56:59 ,显示 [INFO] [reactor_state.go:63] [“remote capture offline”] [capture-id=88fa5ae7-4c6b-496d-9b96-d34e33cf7ce9]
等一段时间 我只能再次重启 ,到18:04 之后好像 选取了新的owner 之后 才恢复 。( 17.92 也是类似 刚选举成为owner 一会就僵死 角色从owner变成 普通worker集群没有owner )

1 个赞
几个capture? capture主机配置如何? 负载如何?
1 个赞
6 个 capture , 24虚拟核 128G 内存 , ticdc CPU使用一般是2-400 负载不高 ,不是负载的问题。
有两个下游 task 对应两个机房下游 tidb集群
cbd_user_behavior_analysis
cbd_user_behavior_analysis_ht
1 个赞

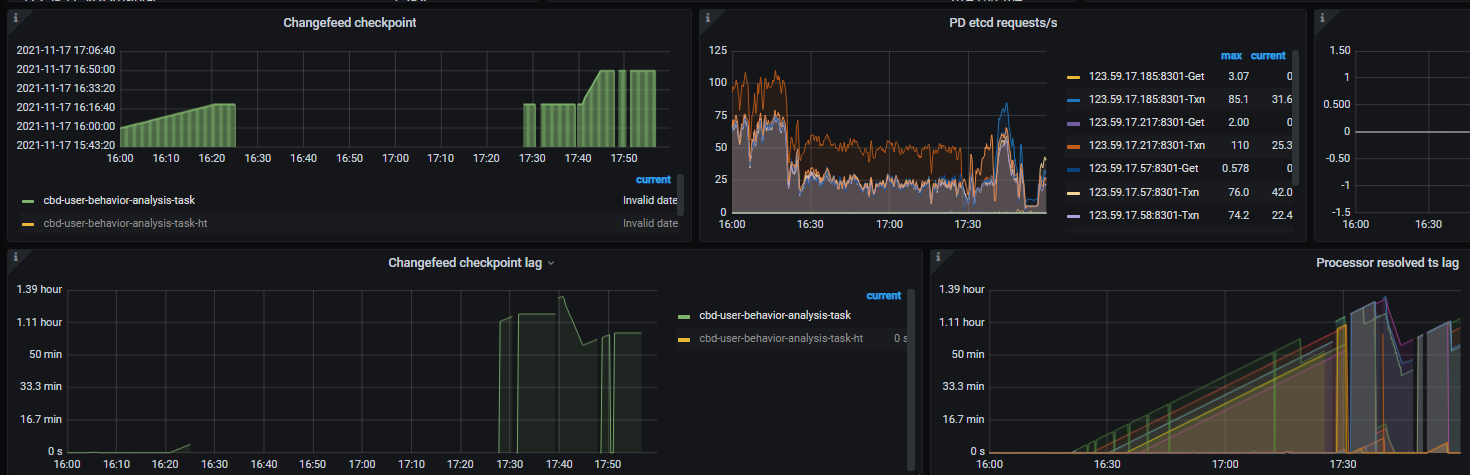
上次上游加索引 没加索引名称 导致下游同步异常报错时 也频繁出现 不能选owner的情况 。
1 个赞
好像有点印象,是tidb中添加索引的ddl没有指定索引的名字
然后下游加索引语句执行超时了,导致cdc向下游重复下发添加索引的DDL语句 和 cf的owner不停的切换
1 个赞
我的意思是 下游异常 的话 ,就会导致ticdc owner 变成 worker 不能有效选举 owner 。 两次情况类似 都是因为下游报错 。 具体报错原因各异 。
1 个赞
所以这个大概率也是场景和用法的问题,具体问题具体分析。
1 个赞
这次cdc向下游同步有没有超时或者其他的错误呢?
1 个赞
有错误呀 ,下游空间紧张 我删了很多表 ,上游某几张历史表 有零星一两条记录操作,导致下游报表不存在。
1 个赞
报错capture 的日志 循环刷这个
[2021/11/17 16:20:32.261 +08:00] [ERROR] [pipeline.go:100] ["found error when running the node"] [name=sink] [error="context canceled"] [errorVerbose="context canceled\
github.com/pingcap/errors.AddStack\
\t
github.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/errors.go:174\
github.com/pingcap/errors.Trace\
\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/juju_adaptor.go:15\
github.co
m/pingcap/ticdc/cdc/sink.(*Manager).flushBackendSink\
\tgithub.com/pingcap/ticdc/cdc/sink/manager.go:114\
github.com/pingcap/ticdc/cdc/sink.(*tableSink).FlushRowChangedEvents\
\tgithub.com/pingcap/ticdc/cdc/
sink/manager.go:172\
github.com/pingcap/ticdc/cdc/processor/pipeline.(*sinkNode).flushSink\
\tgithub.com/pingcap/ticdc/cdc/processor/pipeline/sink.go:139\
github.com/pingcap/ticdc/cdc/processor/pipeline.(*si
nkNode).Receive\
\tgithub.com/pingcap/ticdc/cdc/processor/pipeline/sink.go:320\
github.com/pingcap/ticdc/pkg/pipeline.(*nodeRunner).run\
\tgithub.com/pingcap/ticdc/pkg/pipeline/runner.go:63\
github.com/pingc
ap/ticdc/pkg/pipeline.(*Pipeline).driveRunner\
\tgithub.com/pingcap/ticdc/pkg/pipeline/pipeline.go:96\
runtime.goexit\
\truntime/asm_amd64.s:1371"]
[2021/11/17 16:20:32.261 +08:00] [ERROR] [pipeline.go:100] ["found error when running the node"] [name=sink] [error="context canceled"] [errorVerbose="context canceled\
github.com/pingcap/errors.AddStack\
\t
github.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/errors.go:174\
github.com/pingcap/errors.Trace\
\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/juju_adaptor.go:15\
github.co
m/pingcap/ticdc/cdc/sink.(*Manager).flushBackendSink\
\tgithub.com/pingcap/ticdc/cdc/sink/manager.go:114\
github.com/pingcap/ticdc/cdc/sink.(*tableSink).FlushRowChangedEvents\
\tgithub.com/pingcap/ticdc/cdc/
sink/manager.go:172\
github.com/pingcap/ticdc/cdc/processor/pipeline.(*sinkNode).flushSink\
\tgithub.com/pingcap/ticdc/cdc/processor/pipeline/sink.go:139\
github.com/pingcap/ticdc/cdc/processor/pipeline.(*si
nkNode).Receive\
\tgithub.com/pingcap/ticdc/cdc/processor/pipeline/sink.go:320\
github.com/pingcap/ticdc/pkg/pipeline.(*nodeRunner).run\
\tgithub.com/pingcap/ticdc/pkg/pipeline/runner.go:63\
github.com/pingc
ap/ticdc/pkg/pipeline.(*Pipeline).driveRunner\
\tgithub.com/pingcap/ticdc/pkg/pipeline/pipeline.go:96\
runtime.goexit\
\truntime/asm_amd64.s:1371"]
你们 owner 变成 worker 有什么日志吗? 我们看看 能不能抓到相关的异常日志 。
那把下游缺失的表 重建下 ,看看如何?
用create table if not exists 语句
我们也是根据报错信息 建下游的表 ,让他能恢复 ,但是 就是恢复过程中 频繁出现 不能确保 集群稳定有且仅有一个owner 的状态 ,导致 cdc集群 无脑 就不干活 。
是不是存在一个可能,重建下游表表后,恢复的一瞬间 可能有负载的问题导致的?
建议一次性把下游所有缺失的表都创建了
现在问题不是 下游怎么恢复的问题 , 问题 是 cdc 为什么不能保障有且仅有一个owner 。你们看看这块选主的逻辑是不是有什么异常吧 。
如果下游有新的应用问题 ,cdc把异常报出来就行了 。 没有owner 集群无脑 ,我想pause 修改配置忽略一批表都修改不了 。
无论 zookeeper , etcd 都能确保 有且仅有一个leader 。 咱们cdc 这块怎么就不能保障呢?
