官方文档中对几个统计信息描述如下


1、 buckets的默认值数量是多少? 2. samples的采样数目单位什么? 默认值是多少? 和fast analyze之间是否有影响?
谢谢!
前两个看的源码:
1、256,最大上限1024
2、sample,有两个默认值:
tidb_analyze_version=1时,10000;
tidb_analyze_version=2时,0 (实验特性启用)
最大上限为500000,整型
谢谢,sample的值代表啥意义呢
1、sample貌似和 Count-Min Sketch 有关(如果按Oracle的理解就应该是百分比,不过不知道为何这里是500000的上限)
2、fast analyze看了下,貌似只支持tidb_analyze_version=1
看10000的最小值跟fast analyze使用的一样,但实际测试也没有因为数值指定小就变快
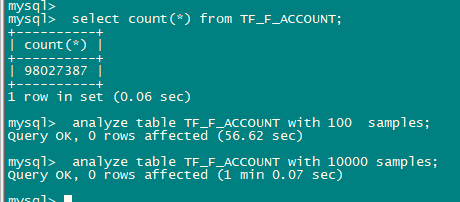
测试了下,不知道采样如何实现的,100条和10000条的时间差异不大。
Analyze 和统计信息相关在最近几个版本分阶段都有一些优化。
5.3 上对采样方法有一些优化,通过使用 sample by rate 或者不指定可以用到新的采样方法,指定 sample number 的话还是旧的采样方法。
https://docs.pingcap.com/zh/tidb/dev/statistics#全量收集
新采样方法在 analyze version 2 才可以使用。
Analyze version 2 禁用了 statistics feedback 和 fast analyze 这两个早期引入但是没有达到 GA 的功能。现在一般也不太建议使用这两个功能。
目前的采样算法为了保证随机性,还无法避免一次 full table scan。
最近几次主要是对分布式采样并计算统计信息时的 CPU 和内存消耗的优化。
随机选择是以行为单位吗
从 analyze version 2 开始是的。
好的 感谢
@h5n1啊,我在上面的基础上再补充一下,针对
测试了下,不知道采样如何实现的,100条和10000条的时间差异不大。
目前的统计信息 大致上维护了如下的信息
这里 NULL count/数据分布 是可以用采样的数据来计算的
但是每一行的有多少个不同的值这项在内部的测试中,如果数据倾斜比较严重的话,通过采样数据来计算这个值会带来比较大的误差。因此这一项在目前最新的 TiDB 实现中,仍然是扫描所有的行来计算一个比较精确的数据。
因此指定很小的 samples 也会发现执行时间并没有太大的变化,因为这个时候主要的开销在计算这个 每行不同的值的个数。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。