11 月 7 日,由 TiDB 社区 X 经纬中国联合主办,初心资本、明势资本、纪源资本、JuiceFS 赞助的 Hacking Camp 2021 生态进行了答辩会,阐述了项目的阶段性成果和对未来工作的展望。这些项目在 Hacking Camp 中基本完成了既定目标,在 Hacking Camp 毕业之后将继续完善相关功能的改进,迭代新版本至更稳定,期间导师也将继续为项目提供指导意见,帮助项目打磨。
本次 Hacking Camp 参与答辩的项目有:
- 以 TiKV 作为元数据引擎的分布式 POSIX 文件系统 JuiceFS
- 基于 TiDB 实现提供 Serverlessdb 服务的 Serverlessdb for HTAP
- 优化 PG 在 TiDB 上的兼容性的 TiDB for PostgreSQL
- TiDB 在大数据领域中的一站式解决方案 TiBigData
- 将 TiKV 作为后端存储的 HugeGraph
- 将 TiDB 作为数据上游的 Doris Connector
评委从项目完成度、应用价值、对 TiDB 生态贡献和答辩完成度这几个方面进行评审,最终 ServerlessDB for HTAP 获得了评审团一致高分,夺得 「优秀毕业生」 和 「最佳应用」 两个奖项。
特别感谢以下几位评审:
明势资本执行经理徐之浩、Flomesh CTO & 联合创始人刘洋、TiDB Team Tech Leader 王聪、PingCAP 研发主管张建、TiKV Maintainer 李建俊
让我们一起来看看项目的毕业成果吧~
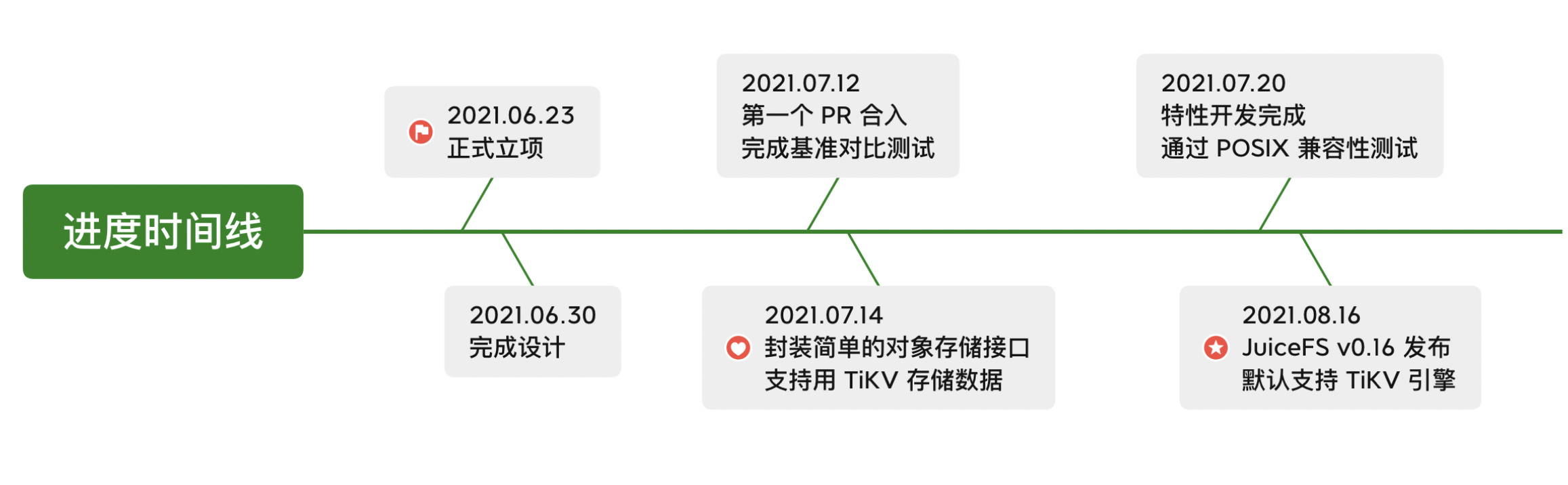
JuiceFS:
JuiceFS 是一个云原生的 POSIX 分布式文件系统,结合 TiKV 作为数据元引擎,JuiceFS 可以 提供百亿级文件规模和 EB 级的数据存储能力,在大规模下依然保持延时稳定 。在 元数据操作性能测试 中,TiKV 引擎的平均耗时约为 Redis 的 2~4 倍,略优于本地 MySQL。
目前主要功能都已开发完毕并于 V0.16 版本发布,且通过了 pjdfstest 测试。已有用户在测试以及生产环境中使用。JuiceFS 未来将把 TiKV 作为大规模生产环境的首推元数据引擎,在保证兼容的情况下,积极引进 TiKV 的新特性。
- ServerlessDB for HTAP:
项目最终目标是要把云数据库服务变成黑盒子,让应用开发者只需要专注于业务如何转化成 SQL,用户再也不用操心数据量、业务负载、SQL 类型是 AP 还是 TP 等这些和业务不相关的事情。
开发内容
-
业务负载模块:
-
业务负载模块评估当前提供服务的资源与当前业务负载是否匹配,建立业务负载模型,用于决策扩缩容。
-
Serverless 模块:
-
Serverless 模块会实时检查所有计算节点的 CPU 使用率,以及底层存储容量,触发计算/存储资源的扩缩容。
-
数据库中间件 :
-
中间件用于解耦用户连接和后台数据库服务节点,这样即使用户使用连接池,扩容后,中间件也能把流量均衡打到所有的新增节点中。
-
规则系统:
-
通过规则系统,可以固定特定时间范围内的资源分配。通过规则设置,流量增长前,把资源提前分配好
-
serverless 服务编排模块:
-
过服务编排模块,实现 TiDB 集群的创建、释放及动态调整 TiDB 组件的扩缩;实现 k8s 本地盘管理,解决私有化部署无法提供云盘的问题;
-
开发 admission-webhook 实现 TiDB 组件缩容时,预先删除中间件注册表记录,实现用户无感知的缩容。
-
后续研发计划:
-
计划增加 Hint 以及规则模块,更精准的区分 TP/AP,评估能够降低一半以上中间件的CPU使用率
-
提供更丰富的负载均衡算法,如基于 SQL 运行时成本
-
中间件增加业务流量管控,如果业务负载增长太快点,超出 serverless 能够处理的增长速度, 会导致后台服务不稳定。通过流量管控,能够很好的处理业务流量暴涨。
本项目也获得了 Hacking Camp 优秀毕业生和最佳应用奖~看来评审都被项目的愿景和开发实力打动了,欢迎大家来围观试用~
项目地址 :https://github.com/tidb-incubator/Serverlessdb-for-HTAP
TiDB for PostgreSQL
项目由神州数码发起,旨在 提供 TiDB 对 PostgreSQL 的兼容性,同时保留了 TiDB 的高可用性、弹性和可扩展性 。允许用户将现有的 PostgreSQL 客户端连接到 TiDB,并使用 PostgreSQL 特有的语法。
目前完成开发:
- Delete 语法改造
- 添加特定 PgSQL 语法 Returning 关键字
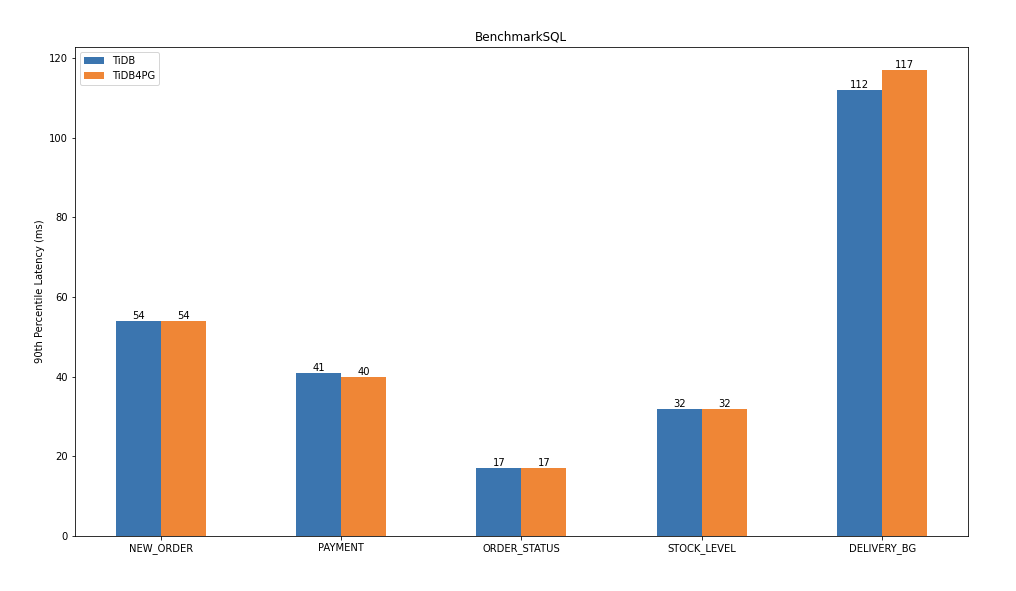
- 完成 Sysbench_tpcc PgSQL 协议下测试并与该版本下原生 TiDB 测试对比
- 完成 BenchMarkSQL PgSQ L协议下基准测试并与该版本下原生 TiDB 测试对比
Benchmark 测试结果对比:
未来计划支持系统库表结构,图形化客户端,以及抽象协议层,随时切换不同协议。欢迎大家一起来玩~
项目地址 :https://github.com/DigitalChinaOpenSource/TiDB-for-PostgreSQL
TiBigData
TiBigData 提供 TiDB 的各类 OLAP 计算引擎的 connector ,目前已经实现包括 Flink,Presto 以及 MapReduce。在 Hacking Camp 中主要工作在 Flink 相关功能开发。
-
我们在 Flink 实现了 Snapshot source 和 TiCDC streaming source,结合这两个 source,我们做到了 TiDB 的流批一体。
-
其次是数据互通,我们利用 TiKV 的跨数据中心部署以及 Flink connector 的 follower read 功能,实现了再离线数据真正互通。
-
最后是计算下推,我们在各类 connector 里都兼容了 TiKV 的下推算子,能够极大的提高数据扫描与计算效率。
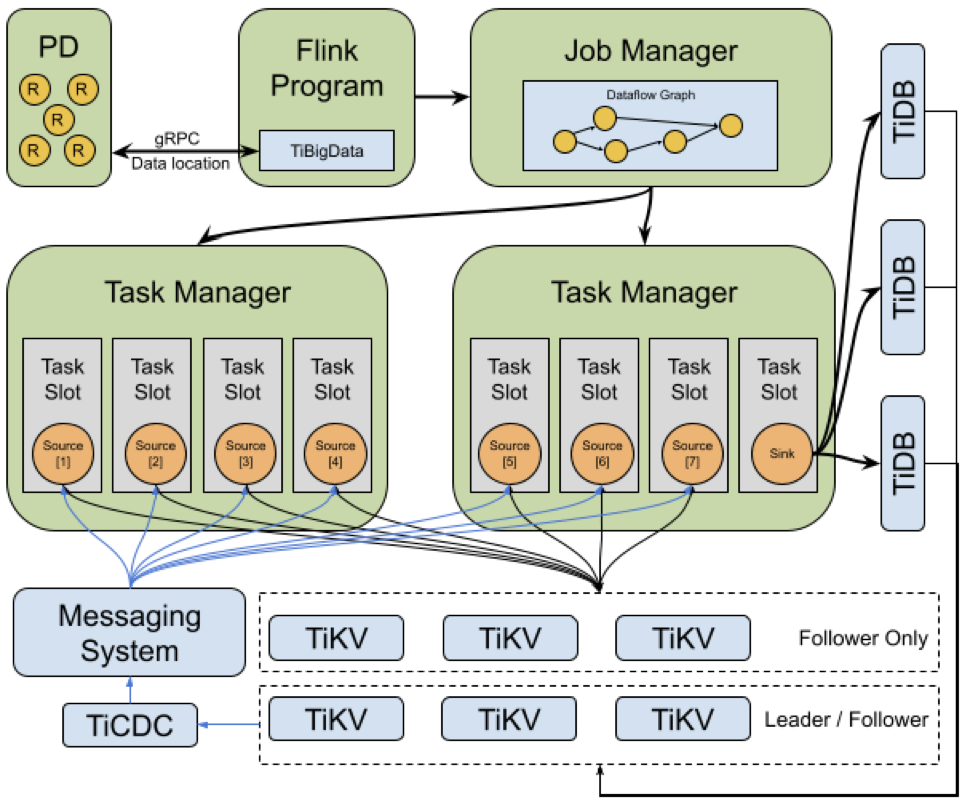
TiBigData 核心功能增强: -
TiDB java client 的通用能力增强,我们实现了 TiDB 的编码器,编码器的代码是从 TiSpark 内解耦出来的,能够适配其他的 OLAP 引擎,也能作为一个通用的工具,被其他有需要的社区伙伴引用。
-
实现了一些数据类型的转换工具,flink/presto 数据类型与 TiDB 的数据类型相互转换。
-
实现了 TiKV 的分布式客户端,从 API 的层面上更加适配分布式计算框架。
后续将继续开发 Change Log Write、TiDB x Preto/Trino、Flink State Backend in TiKV 等,感兴趣的同学可以加入社区一起玩~
项目地址 :https://github.com/tidb-incubator/TiBigData
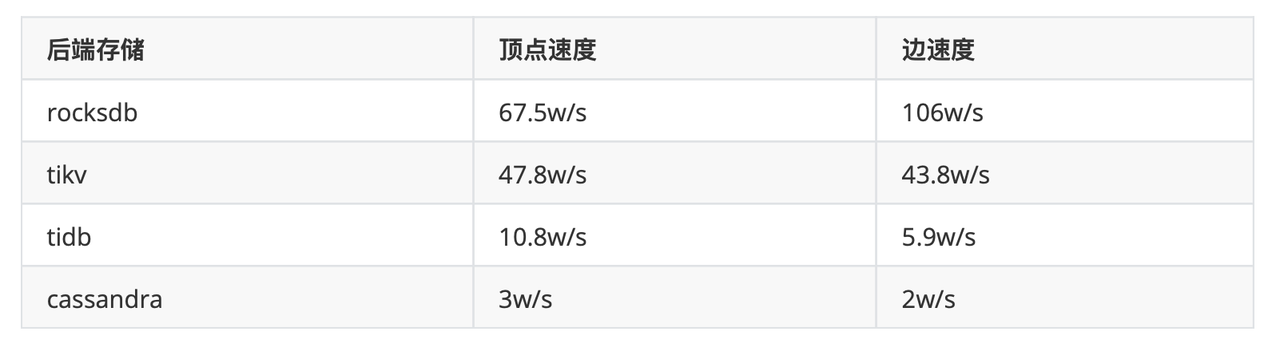
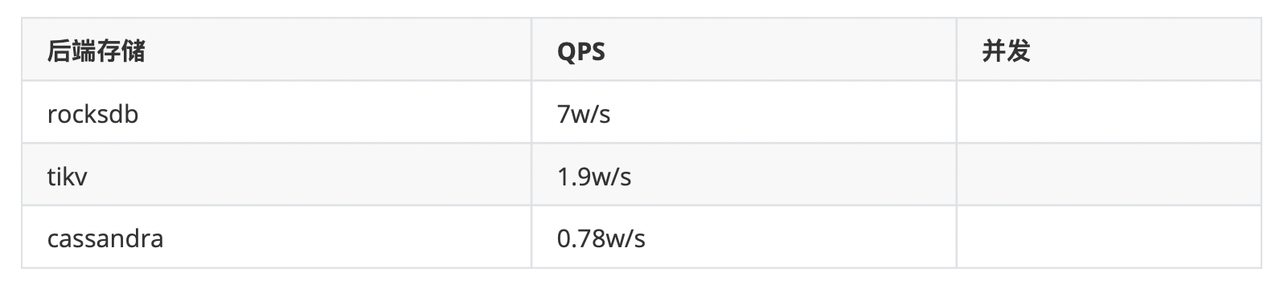
HugeGraph on TiKV
HugeGraph on TiKV 适用于需要大规模图数据库的场景,并且对读写性能要求较高、已具备 TiVK 存储运维团队的 需求场景尤为匹配 。
已实现功能:
- 支持单图实例
- 支持 Schema 的增删改查
- 支持 Loader 导入数据 支持顶点和边的增删改查
- 支持 kout、kneighbor 等 traversal 算法 支持 Gremlin 查询 支持索引查询(不完备)
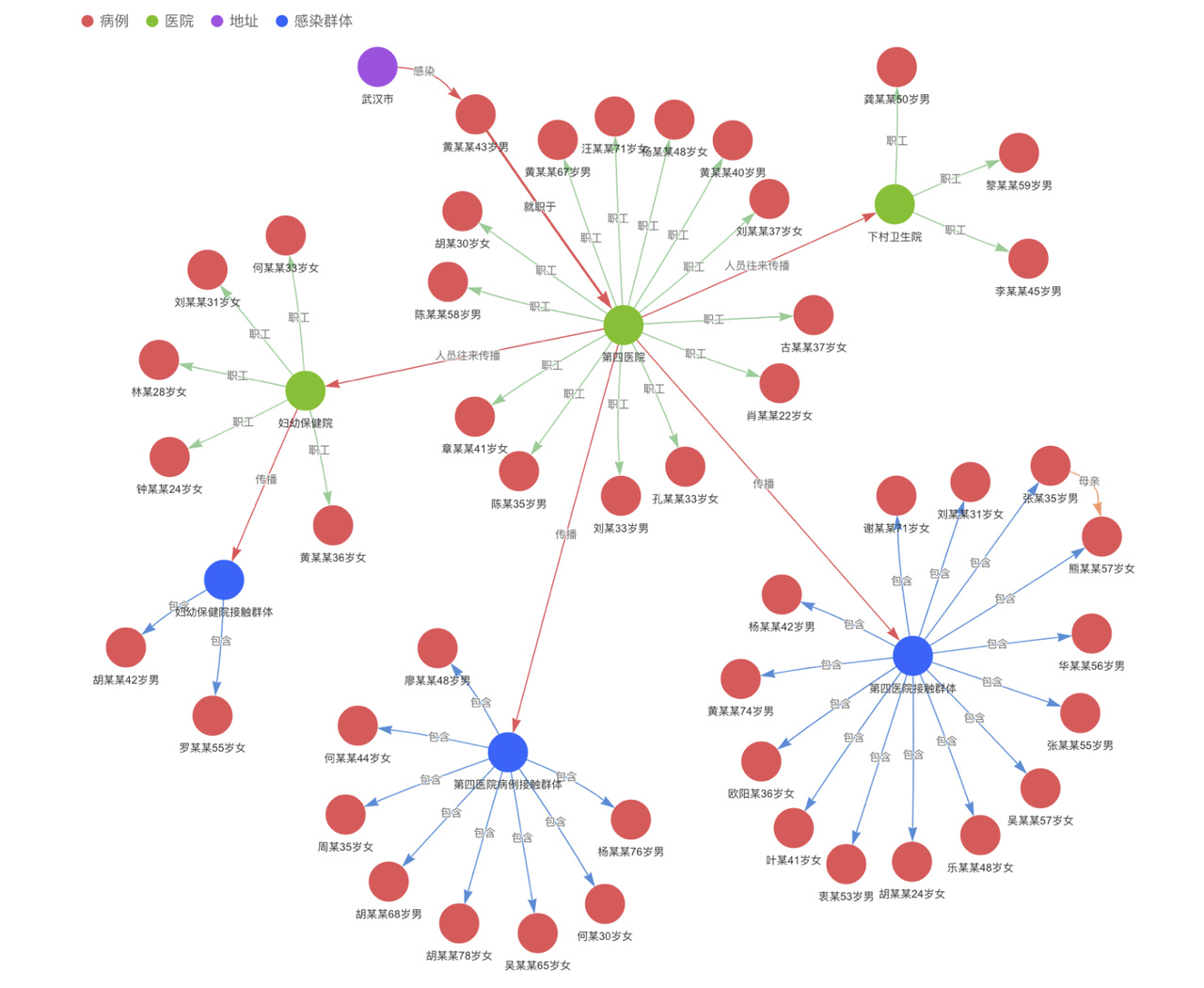
效果展示:
导入数据【新余市新冠肺炎数据集】,通过 HugeGraph-Hubble 界面查看图谱效果:
性能测试结果:
导入速度(写)
按 id 查询(随机读)
后续计划:
-
功能完善
-
支持多图实例、truncate/clear 图数据、监控接口 metrics、TTL 等高级功能
-
性能优化
-
写入性能优化:提交模式、批大小调整等
-
查询性能优化:数据编码优化、分⻚优化等
项目地址 :https://github.com/tidb-incubator/hugegraph-on-tikv
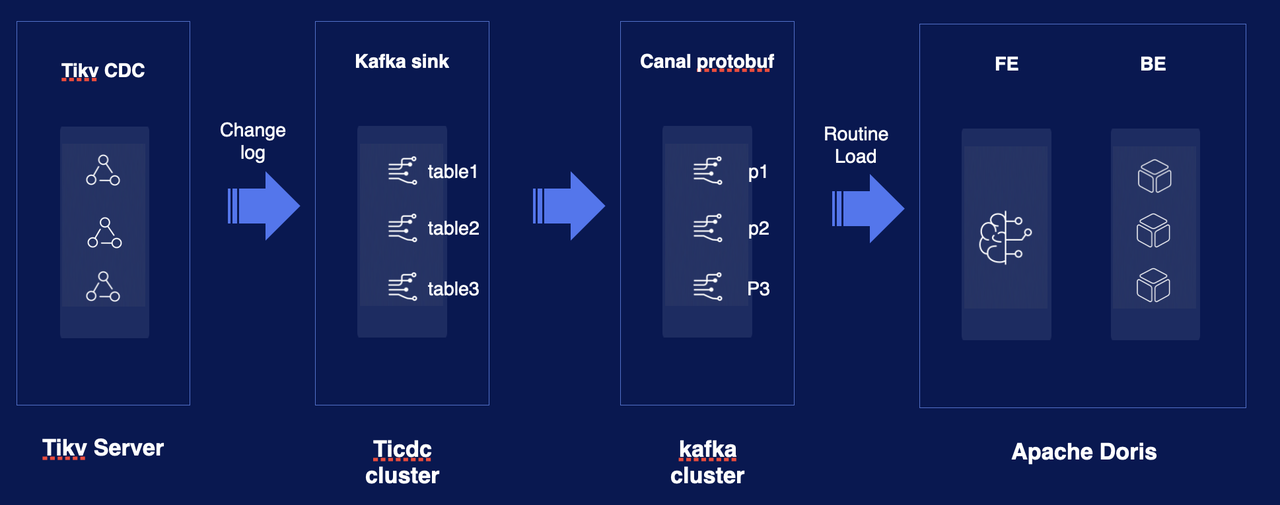
Doris Connector:
以 TiDB 为数据源,为 Doris 提供原生的连接器,打通 TP-AP 场景的数据流。 适用于对 DML/DDL 的同步支持和过滤指定条件的数据。 目前项目进度 70%。
设计思路
-
Stream Load:TiDB 中设计独立服务,定时读取并解析 TiDB binlog 文件,并将数据行拼成 CSV 格式文件,通过 Stream Load 导入到 Doris 中。
-
Routine Load:借助 TiDB 的 Drainer 将 binlog 同步到 Kafka,Doris 中通过新增 TiDB Binlog数据格式来实现数据的同步
-
TiDB 原生协议同步:在 Doris 中实现 TiDB 副本同步协议,将 Doris 伪装成 TiDB 集群的一个节点。
后续规划:
项目将进行持续迭代,从用户真实场景出发,使数据处理链路更加无阻。项目后期会合并入 Doris 主干。
项目地址 :https://github.com/apache/incubator-doris
这一期 Hacking Camp 在六个精彩的项目答辩中落幕,但生态的维护是长期的,我们将持续为这些优秀的生态项目提供后续支持,保证项目持久的生命力。对项目感兴趣的同学也请关注后续推文,创始团队 将从应用层面解读项目对整个 TiDB 生态的价值 ,更有专题 Meetup 策划中,敬请期待!
从 Ti 星球到宇宙苍穹,我们用 Hacking 连接更广泛的生态。2021 TiDB Hackathon 也即将开启,快来和我们一起探索数据库技术的奥秘!
hacking camp 生态答辩 ppt.zip (7.3 MB)