本文档介绍 DM 增量同步中如何诊断性能问题及其处理方法,文档中的内容主要涉及 DM 内部组件,不涉及 TiDB 侧的性能诊断。
主要监控指标
| metrics | meaning |
|---|---|
| task state | 任务状态 |
| DML queue remain length | DM 中堆积的 binlog 数量,如果该项长时间超过几百,可认为是下游同步较慢导致 |
| binlog file gap between master and syncer | DM 当前同步的 binlog 文件和上游最新的 binlog 文件的差值 |
| binlog file gap between master and relay | DM relay 当前拉取的 binlog 文件和上游最新的 binlog 文件的差值 |
| finish sql job | DM 每秒同步的 row event 数量(所有队列总和) |
| binlog event qps | DM 拉取上游 binlog 的 QPS |
| transaction execution latency | DM 执行一个事务到 TiDB 的延迟 |
| statement execution latency | DM 执行一条 SQL 语句到 TiDB 的延迟 |
| ideal qps(v5.3.0+) | 在 DM 运行耗时为 0 时可以达到的最高 QPS,可与当前 QPS 进行对比,如果相差太大,说明 DM 内部可能有性能瓶颈 |
| replication transaction batch(v5.3.0+) | 执行到下游的事务里中 sql 行数 |
基本思路
-
先确认任务有没有暂停,报错导致的同步中断。
-
明确 DM 性能瓶颈。下游无瓶颈情况下,单个 DM worker 每秒同步 binlog event 的数量 18k+,具体大小依赖 CPU 单核性能。见文档下面的测试。
-
确认是吞吐不够还是延迟过大。
- 看 binlog file gap between master and syncer,如果该值不断增大就是吞吐不够,如果该值为 0 而下游数据插入缓慢则为延迟过大。
- 如果开 relay log,看 binlog file gap between master and relay,如果该值不断增大,建议查看 relay 是否暂停或其他网络原因,否则说明 DM 到达瓶颈了
-
吞吐不够
-
DML queue remain length 长时间为 0,说明下游无瓶颈,可通过调大 worker-count 和 batch,增大 DM 同步线程和事务的语句数量。若 binlog event qps 还是没有变化且 DML queue remain length 长时间为 0,可认为 DM 到达瓶颈了。
-
DML queue remain length 长时间不为 0,说明 DM 中堆积了一定量的 binlog,下游消费速度跟不上 DM 从上游拉取 binlog 的速度,瓶颈在下游。
-
查看 replication transaction batch 的值 (5.3.0+) ,对比该值与 DM task 配置中的 batch
- 如果该值远小于 batch,说明 DM 每个事务较小,尝试增加 worker-count,加大同步线程
- 如果该值基本等于 batch,说明 DM 攒满一整个事务,如果下游 transaction duration 不大,尝试调高 batch
-
如果调节 worker-count 和 batch 后 qps 没有上升,下游 transaction duration 等比例上升/下降,说明并发和 batch 影响不大,瓶颈大概率在下游。
-
经验值(玄学):
- worker-count:默认 16,下游压力不大情况下,可以调高(16 - 1024)
- batch:100,根据 transaction statement size 调节(20-1000)
-
常见写入 DM 慢原因:
- 下游是否存在 auto-increment 导致写冲突
- 下游是否频繁出现 safe try 和 region unavailable 之类的错误
- 任务是否频繁重启进入 safemode(replace 语句增加)
-
-
-
延迟过大
- 如果开启 relay log,会增加一次写磁盘和一次读磁盘操作,可尝试关闭 relay log
- 如果 transaction duration 过高,说明主要是 DM 写下游延迟高,可适当调小 batch
- 可以抓取 DM-worker profile,查看火焰图 curl http://host:port/debug/pprof/heap > heap.profile
DM 工作流程
DM 从上游拉取 binlog 同步到下游的流程如下
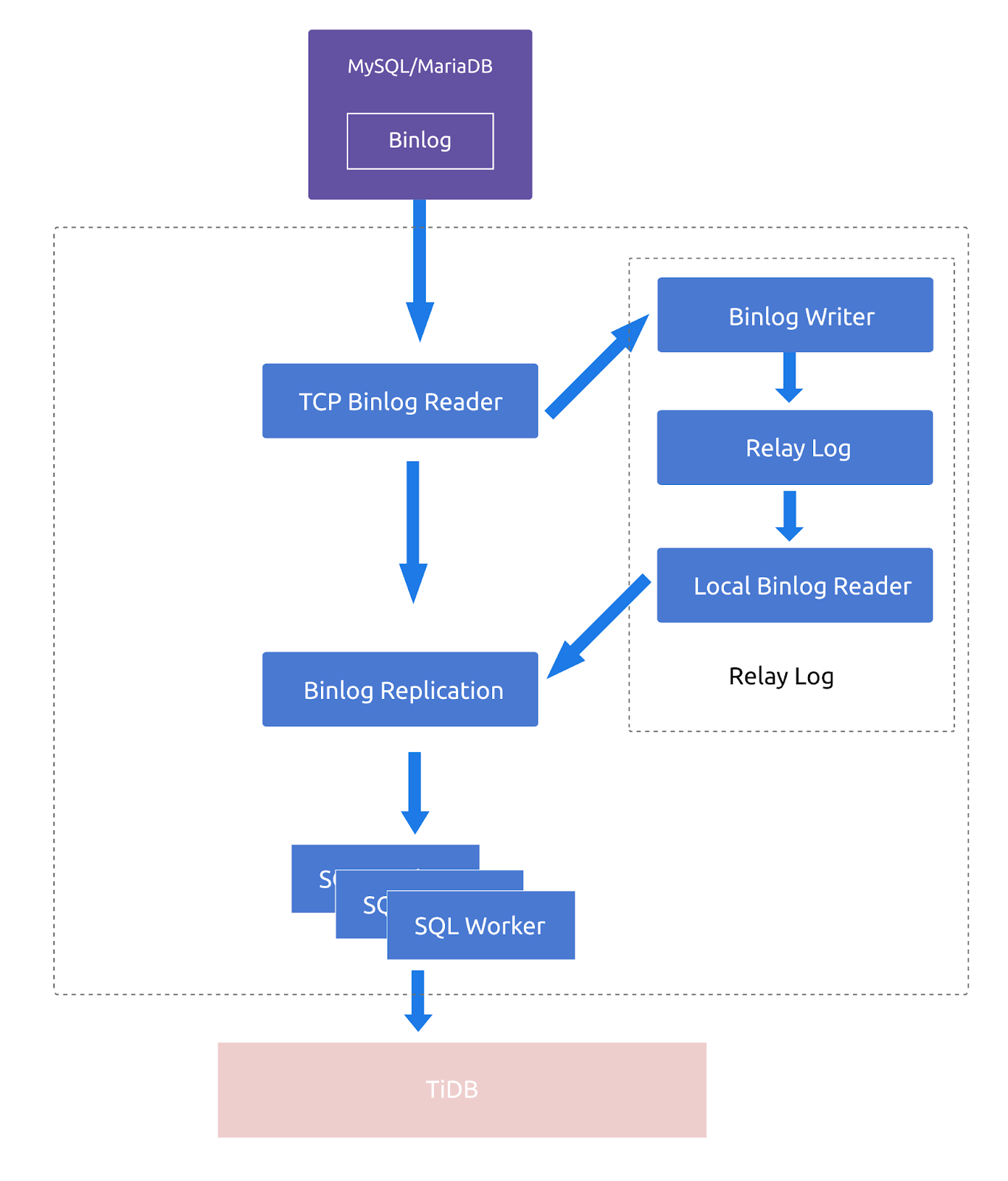
- DM-worker 把自己注册为上游 MySQL/MariaDB 的从库
- TCP Binlog Reader 从上游读取 binlog
- Binlog Writer 将 binlog 写入 relay log
- Local Binlog Reader 从 relay log 中读取 binlog
- Binlog Replication 拿到 binlog 并转换为 SQL
- SQL Worker 拿到 SQL 并执行到下游
下面我们根据这个流程,结合监控一起分析下性能问题
DM 性能诊断
DM-worker 把自己注册为上游 MySQL/MariaDB 的从库
这个阶段主要在任务开始时进行,上游 MySQL/MariaDB 负载无异常时,对性能影响较小
TCP Binlog Reader 从上游读取 binlog
这个阶段 DM 从上游拉取 binlog,拉取 binlog 的阻塞时间监控指标为 syncer 或 relay 监控中的 read binlog event duration 理想情况下应接近于 DM-worker 与 MySQL/MariaDB 实例间的网络延迟。当上游 MySQL/MariaDB 负载较低,一段时间内暂时没有需要发送给 DM 的 binlog event,TCP Binlog Reader 会处于等待状态,导致该值包含了额外的等待时间。从上游读取 binlog 数据这一流程细分后包括以下三个子流程:
- 上游 MySQL/MariaDB 从本地读取 binlog 数据并通过网络进行发送。上游 MySQL/MariaDB 负载无异常时,该子流程通常不会成为瓶颈。
- binlog 数据通过网络从 MySQL/MariaDB 所在机器传输到 DM-worker 所在机器。该子流程主要由 DM-worker 与上游 MySQL/MariaDB 的网络连通情况决定。
- DM-worker 从网络数据流中读取 binlog 数据,并构造成 binlog event。当 DM-worker 负载无异常时,该子流程通常不会成为瓶颈。
Relay Log
可以主要通过 binlog file gap between master and relay 监控项确认是否存在性能问题。如果该指标长时间大于 1,通常表明存在性能问题;如果该指标基本为 0,一般表明没有性能问题。
Relay Log 主要包含写和读两部分,这两部分是异步执行的。对于写 Relay Log,监控指标为 write relay log duration,对于读 Relay Log,监控指标是 syncer 监控中的 read binlog event duration。这两指标在 binlog event size 不是特别大时,值应在微秒级别。如果该值过大,需排查磁盘写入性能,如尽量优先为 DM-worker 使用本地 SSD 等。
Binlog Replication
Binlog Replication 模块从 binlog event 数据中尝试构造 DML、解析 DDL 以及进行 table router 转换, dml filter 过滤等,主要的性能指标有 transform binlog event duration,binlog event qps。这部分的耗时受上游写入的业务特点影响较大,如对于 INSERT INTO 语句,转换单个 VALUES 的时间和转换大量 VALUES 的时间差距很多,其波动范围可能从几十微秒至上百微秒,但一般不会成为系统的瓶颈。
由于这部分程序是单线程执行,受 cpu 性能影响较大,在下游无瓶颈的情况下,实测 binlog event qps 在每条 binlog 只有一行 value 时,可达到 20k 以上
| cpu | binlog event qps |
|---|---|
| Intel Xeon E5-2630 v4 @ 2.20 GHz | 21k |
| I7 7700 @ 3.60 GHZ | 30k |
| I7 10710U @ 1.10 ~ 4.70 GHz | 39k |
SQL Worker
SQL Worker 将拿到的 SQL 同步到下游,可通过 task 配置文件中的 worker-count 和 batch 分别配置 SQL Worker 的并发数和 SQL 的批量执行数。此过程涉及到的性能指标主要包括 DML queue remain length 与 transaction execution latency。
DM 在从 binlog event 构造出 SQL 后,会使用 worker-count 个队列尝试并发写入到下游。但为了避免监控条目过多,会将并发队列编号按 8 取模,即所有并发队列在监控上会对应到 q_0 到 q_7 的某一项,然后累加进去。可从 total sql job 监控项中查看每条队列处理的 job 数目,监控中 8 条队列总和即为 DM 每秒处理数据的行数。从上表中可得出结论,单个 worker 每秒处理数据的行数在 20k 以上。
DML queue remain length 用于表示并发处理队列中尚未取出并开始向下游写入的 DML 语句数。当整个数据迁移链路 SQL worker 以前的阶段比 SQL worker 以后的阶段慢时,DML queue remain length 对应曲线应基本为 0,且最大通常应不超过任务配置文件中的 batch 值。
如果 DML queue remain length 对应曲线不为 0(最大不超过 1024),则通常表明向下游写入 SQL 时存在瓶颈,可通过 transaction execution latency 查看向下游执行单个事务的耗时情况。此时可基本判断性能问题出现在下游 TiDB 上。
默认 batch 下 transaction execution latency 一般应在几十毫秒。如果该值过高,则通常需要根据下游数据库的监控对下游性能进行排查,另外也可以关注是否 DM 到下游数据库间的网络存在较大的延迟。
理想情况下,DML queue remain length 各 q_* 对应的曲线应该基本一致,如果极不一致则表明并发的负载极不均衡。如果负载不均衡,请确认需要迁移的所有表结构中都有主键或唯一键或者某行出现频繁更新,如没有主键或唯一键则请尝试为其添加主键或唯一键。
如果确认数据迁移链路存在明显延迟,且 DML queue remain length 中各 q_* 对应的曲线基本一致且基本为 0,则表明 DM 未能及时地从上游读取数据、进行转换或进行并行分发(如瓶颈存在于 relay log 模块等),请参考本文档前述各节进行排查。
此外,也可通过 statement execution latency 查看向下游写入 BEGIN、INSERT、UPDATE、DELETE、COMMIT 等单条语句的耗时情况。