本文由携程技术团队撰写,介绍了携程自研的国际业务动态实时标签处理平台。其中标签持久化的场景需要解决业务标签的持久化存储、更新、查询服务,TiDB 通过对于不同场景查询特性的支持满足了不同业务场景访问业务特征数据的需要。
作者介绍
- Weiyi,携程资深数据开发,关注大数据相关技术,对大数据实时计算、流批一体等方面有浓厚兴趣;
- Hzhou,携程资深数据开发,关注大数据相关技术,对系统架构和实时处理等方面有浓厚兴趣;
- Rongjun,携程大数据架构开发,专注离线和实时大数据产品和技术。
背景
在国际业务上,因为面临的市场多,产品和业务复杂多样,投放渠道多,引流费用高,因此需要对业务和产品做更精细化的管理和优化,满足市场投放和运营的需要,降低成本,提升运营效率,提升转化率。为此我们提出研发携程国际业务动态实时标签处理平台(以下简称CDP),为 Trip 业务增长解决 “Grow Revenue” 和 “Reduce Costs” 的问题,具体如图 1-1。

图 1-1 CDP 所需要解决的业务问题
因为 Trip 数据来源比较广泛,既有自身数据也有外部数据;数据形式也非常多样化,既有结构化数据,也有半结构化和非结构化数据;数据加工形式既有离线数据处理,也有在线数据处理;如何通过系统加工这些数据形成业务系统、运营、市场需要并且可以理解的数据和标签,成为了 CDP 平台急需解决的业务和系统问题,简单总结下来系统主要需要解决以下四个方面的问题:
数据采集与管理
主要丰富不同的数据来源,包括三个部分。第一方数据,来自自己,UBT 日志,平台数据,客服处理数据,APP 安装数据。第二方数据,来自集团中的其他品牌的数据,如 SC、Travix 等。第三方数据,来自我们合作方的网站,比如 meta 投放平台等。
ID 匹配
不同的数据源有不同的 ID 标签,比如 APP 端来源的数据会有一个统一的 ClientID 的主键,与之相关联的会有一组标签。来自不同业务系统的数据都会有对应的 ID 以及标签与之对应。这些标签主体的 ID 分别来源于不同的系统和平台。平台之间的 ID 有的相互之间可能没有关联关系,有的有一定的关联关系,但不是一一对应的,但是业务系统使用时往往是需要相互组合使用。因此需要有一个 ID 从数据采集到业务标签创建,到最终使用都能串联的一个唯一 ID。这个是最大的难点。如果没有,那我们需要一个非常完整的 ID Mapping,在不同的 ID 之间可以做转换,这样用户可以串联不同实体之间的标签。
业务标签模型
一些有场景决策使用的标签,比如市场最受欢迎产品,最热门旅游目的地等等。很多公司早期在做标签时什么都想要,铺了上百个统计类标签,然而这些标签并不能直接使用。而且将上百个标签砸向产品或运营人员的时候,因为没有重点,会一下将业务人员“砸晕”。所以能提供真正有效的标签很重要。在这个过程中对业务的理解就变得尤为重要,系统需要根据业务场景建立对应的业务标签模型。
标签的使用
和使用标签的系统做对接,比如消息系统,第三方平台,站内平台。让这些业务标签,最大化帮助业务产生业绩。其中的难点是,CDP 怎么和使用它的平台去做对接。
要解决以上问题,系统必须提升数据处理能力,因为处理好的数据是需要立马运用到业务系统、EMD、PUSH 等等使用场景中去, 对数据处理系统的时效性、准确性、稳定性以及灵活性等提出了更高的要求。
在过去我们现有 CRM 数据是通过数仓 T+1 计算,导入到 ES 集群存储,前端通过传入查询条件,组装 ES 查询条件查询符合条件的数据。目前已经上线的标签有上百个,有查询使用的超过 50%,能满足一部分对数据时效性要求不高的标签数据筛选场景的需要,比如市场活动目标用户的选择。因为是离线计算,所以数据时效性差,依赖底层离线平台的计算,依赖 ES 的索引,查询响应速度比较慢。
基于以上这些问题,新系统希望在数据处理过程中能提升数据处理的时效性同时满足业务灵活性的要求,对于数据处理逻辑,数据更新逻辑,可以通过系统动态配置规则的方式来消费消息数据(Kafka 或者 QMQ)动态更新标签,业务层只需要关心数据筛选的逻辑,以及条件查询。
二、系统设计
基于业务需要,我们将业务数据标签筛选的场景分为两大类:
实时触发场景
根据业务需要,配置动态规则,实时订阅业务系统的变更消息,筛选出满足动态规则条件的数据,通过消息的方式推送到下游业务方。
标签持久化场景
将业务系统的实时业务变更消息按照业务需要加工成业务相关的特征数据持久化存储到存储引擎,业务根据需要组装查询条件查询引擎数据,主要是 OLAP(分析类)和 OLTP(在线查询)两大类查询。
为了解决以上问题,我们设计开发了一套“实时动态标签处理系统”,业务方只需要按照基本算子规则配置提交任务,系统就会自动解释执行规则,按照配置要求执行数据处理操作,目前支持的基本算子有Stream(流式数据接入目前支持 QMQ 和 Kafka)、Priority(优先级判断)、Join、Filter(过滤)、Sink(数据输出,目前支持 TiDB、Redis、QMQ)等等,这些在整体设计里面会详细介绍,通过规则和动态计算的方式提升数据处理和开发效率,降低开发成本。
流式数据采用类 Kappa 架构,标签持久化采用类 Lambda 架构 ,系统架构如图 2-1。
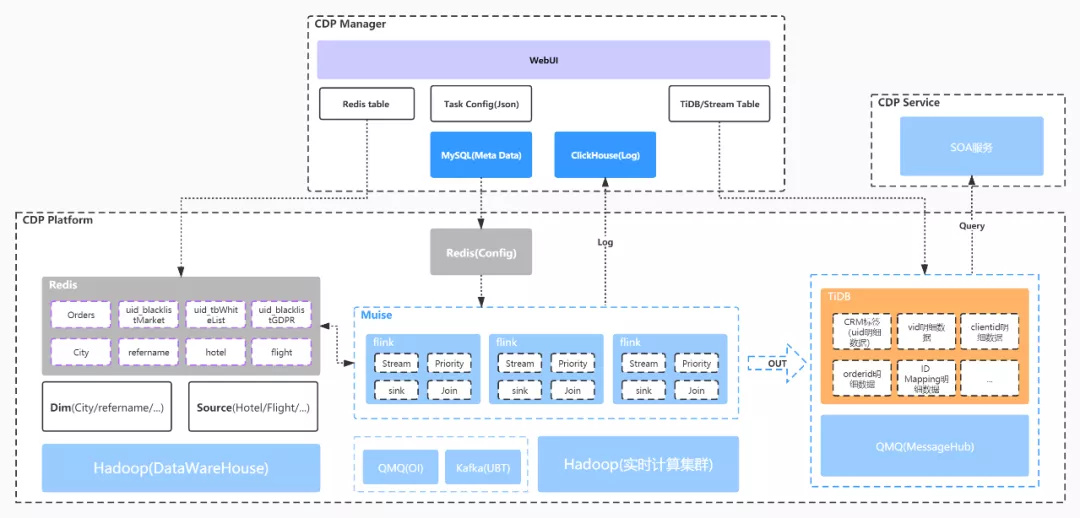
图 2-1 CDP 系统架构
系统对公司内输出主要是对接站内的自运营渠道,比如消息系统,发送短信,邮箱,广告。站内主流程根据 CDP 的特征组装前端业务流程。
三、实时触发
针对动态触发的场景需要解决动态规则配置,规则解析,规则内动态计算节点(算子,之后都简称为算子)的生成,算子的相互依赖关系(DAG),以及数据 join 的处理。
为了解决实时流式数据处理,我们引入了类似于 Kappa 架构的数据处理方式,做了一些调整,采用主动 Push 方式,因为这个场景的数据主要是应用于 Push/EDM 等主动触达的场景,结果数据不需要落地,我们直接通过 QMQ 消息渠道推送到应用订阅的消息队列。
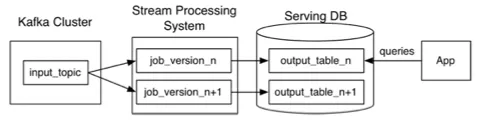
图 3-1 Kappa 数据处理架构
这样解决了消息时效性的问题,同时也解决了规则时效性的问题,修改规则不需要重启任务即可生效。计算结果采用主动推送的方式,省去了数据存储和查询的过程,提升了数据的时效性,节省了存储空间。
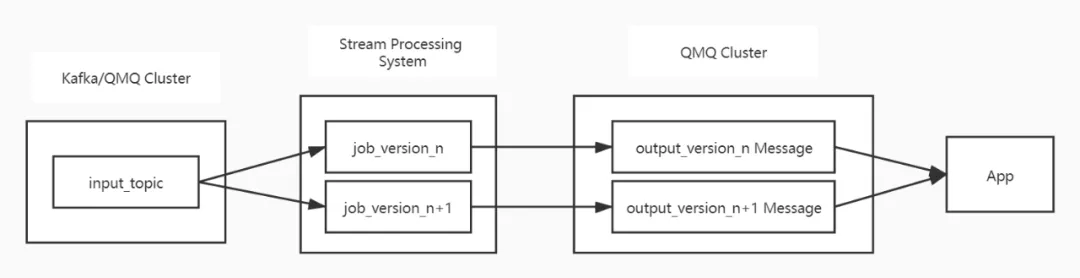
图 3-2 CDP 实时触发数据处理架构
规则引擎设计采用Json格式传参,算子设计为两层,上层为固定业务逻辑支持的动态业务算子,主要包含 Stream、Priority、Join、Filter、Sink,下层为固定业务算子使用的一些基础算子,可以自由组合,以满足消息实时处理业务逻辑处理的需要。
关于规则引擎所涉及的一些基本概念描述如下:
Stream
消息源接入,主要是 Kafka 和 QMQ,结构化 Json 数据,所有的接入消息源的数据结构、数据类型、来源都需要录入管理,借用公司的 Kafka 和 QMQ 消息注册管理机制,实现全流程打通。
Priority
优先级判断,比如主流程一般按照搜索页,列表页,填写页,支付页次序排列,因为流量是一层一层减少,所以越到后面流量越重要,在一些业务场景中需要根据这些流量的重要程度排序,优先级判断可以满足这些业务场景的需要。
Join
Join 算子,目前只支持使用 Redis 作为 Join 右表,如果 Join 条件不满足右表数据都为 NULL,默认输出左表数据,如果需要右表数据需要指定输出的字段。
Filter
过滤算子,可以直接过滤上游数据,也可以过滤上游数据与 Redis Join 后的数据。只有通过的数据才会流入后面算子,否则该条数据处理结束。
Sink
计算结果输出,支持配置化方式,目前支持消息队列模式(QMQ),数据库(TiDB、MySQL 等等)。
基础算子
基础的原子算子,不可再拆分,如 +、-、*、/、>、<、=、>=、<= 以及in,not in,like,rlike,IS_NULL,IS_NOT_NULL 等。
自定义函数
支持计算过程中使用自定义函数,用户可以自定义数据处理函数并注册到生产系统,目前支持的函数如下:
- 字符串函数:CONCAT、CONCAT_WS、HASH、IFNULL、IS_NOT_BLANK、IS_NOT_NULL、IS_NULL、LIKE、LOWER、UPPER、REGEXP、REPLACE、SUBSTR、UPPER、URL_EXTRACT_PARAMETER等
- 时间函数:CURRENT_TIMESTAMP、FROM_UNIXTIME
- JSON 函数:JSON_EXTRACT
DAG
DAG 是一种“图”,图计算模型的应用由来已久,早在上个世纪就被应用于数据库系统(Graph databases)的实现中。任何一个图都包含两种基本元素:节点(Vertex)和边(Edge),节点通常用于表示实体,而边则代表实体间的关系。
由于 DAG 计算是一套非常复杂的体系,我们主要借鉴了 Spark 的 DAG 计算思想,简化了 DAG 计算流程从而满足我们实时计算业务场景的需要, 在介绍 DAG 计算方式之前,先介绍一下 Spark 中 DAG 计算的基本思想和概念。
在 Spark 中 DAG 是分布式计算模型的抽象,专业术语称之为 Lineage —— 血统,RDD 通过 dependencies 和 compute 属性构成首尾相连的计算路径。
Dependencies 分为两大类,Narrow Dependencies 和 Wide Dependencies(如图 3-3)。
Narrow Dependencies 是指父 RDD 的每一个分区最多被一个子 RDD 的分区所用,表现为一个父 RDD 的分区对应于一个子 RDD 的分区或多个父 RDD 的分区对应于一个子 RDD 的分区,也就是说一个父 RDD 的一个分区不可能对应一个子 RDD 的多个分区。
Wide Dependencies 是指子 RDD 的分区依赖于父 RDD 的多个分区或所有分区,也就是说存在一个父 RDD 的一个分区对应一个子 RDD 的多个分区。在 Spark里面需要shuffle,Spark称之为Shuffle Dependency,做为划分 stage 依据。
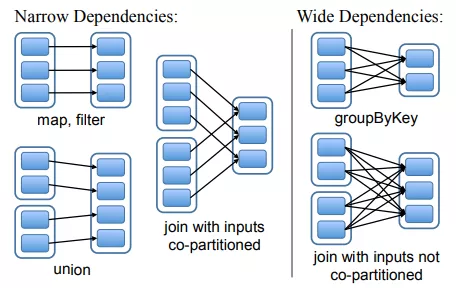
图 3-3 Narrow Dependencies 与 Wide Dependencies
在 Spark 中 Stage 划分方式是从后往前推算,遇到 ShuffleDependency 就断开,遇到 NarrowDependency 就将其加入该 stage。每个 stage 里面 task 的数目由该 stage 最后一个 RDD 中的 partition 个数决定。如图 3-4。

图 3-4 Spark Stage 划分方式
在 Spark 中 RDD 的算子分为两大类:
Transformations:数据转换,如map、filter、flatMap、join、groupByKey、reduceByKey、sortByKey、repartition等等,该类型算子采用 lazy evaluation(惰性求值),即 Transformation 操作不会开始就真正的计算,只有在执行 Action 操作的时候 Spark 才会真正开始计算。转化操作不会立刻执行,而是在内部记录下所要执行的操作的相关信息,必要时再执行。
Actions:数据物化操作,计算触发,如collect、count、foreach、first、saveAsHadoopFile 等等。
每个 Stage 内包含一组 TaskSet,Task 之间传递数据是 Pipeline 的方式。
根据业务标签数据处理需要,借鉴 Spark 的思想,CDP 对 DAG 计算做了一些简化 ,具体如下:
在 CDP 的 DAG 中,DAG 的拆分是直接从前往后推算,不需要拆分 Stage,所有的 DAG Task 都在同一个 stage 中(All in one Stage)如图 3-5,并且是并发可扩展,不需要 DAGScheduler。
在 CDP 中算子分为两大类:
Operator:数据处理操作算子,如 Stream、Priority、Join、Filter、Sink,是由基础的原子算子配置而来,该类型算子采用 eagerevaluation(及早求值),即 Operator 在数据一旦进入就会触发数据处理操作,这样不需要缓存状态数据,能有效提升数据处理效率。
Edge:描述 Operator 之间的关系,即拓扑关系。
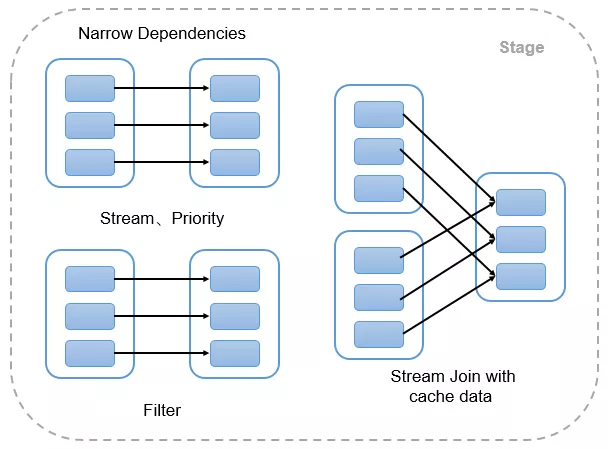
图 3-5 CDP All in one Stage
四、标签持久化
标签持久化的场景需要解决业务标签的持久化存储、更新、查询服务,采用分布式高可用关系型数据库(TiDB)存储业务持久化的标签,采用实时触发场景中的动态规则配置的方式消费业务系统数据变更消息,使用本文第三节中提到的实时触发的方式处理后更新持久化标签存储数据,保证业务持久化标签的时效性, 通过 TiDB 对于不同场景查询特性(主要是 OLAP 和 OLTP)的支持来满足不同业务场景访问业务特征数据的需要 。
为了解决标签持久化场景的需求,借鉴 Lambda 数据处理架构的思想,新增数据根据来源不同分别发送到不同的通道中去,历史全量数据通过数据批处理引擎(如 Spark)转换完成以后批量写入到数据持久化存储引擎(TiDB)。增量数据业务应用以消息的形式发送到 Kafka 或者 QMQ 消息队列,通过本文第三节实时触发场景中提到的实时数据处理方法,将数据按照标签持久化的逻辑规则处理完成之后增量写入到持久化存储引擎(TiDB),这样解决数据的时效性问题。
TiDB 有两大持久化存储方式,一种是 Row 模式的 TiKV,对于实时在线查询场景(OLTP)支持的比较好,一种 Column 模式的 TiFlash,对于分析类查询场景(OLAP)支持的比较好,TiDB 数据存储内部自动解决这两个引擎的数据同步问题,客户端查询根据自身需要选择查询方式。
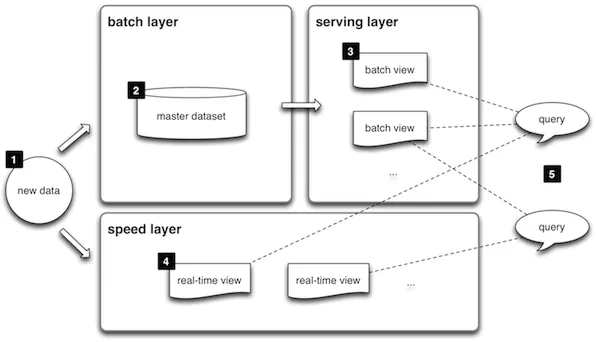
图 4-1 Lambda 架构
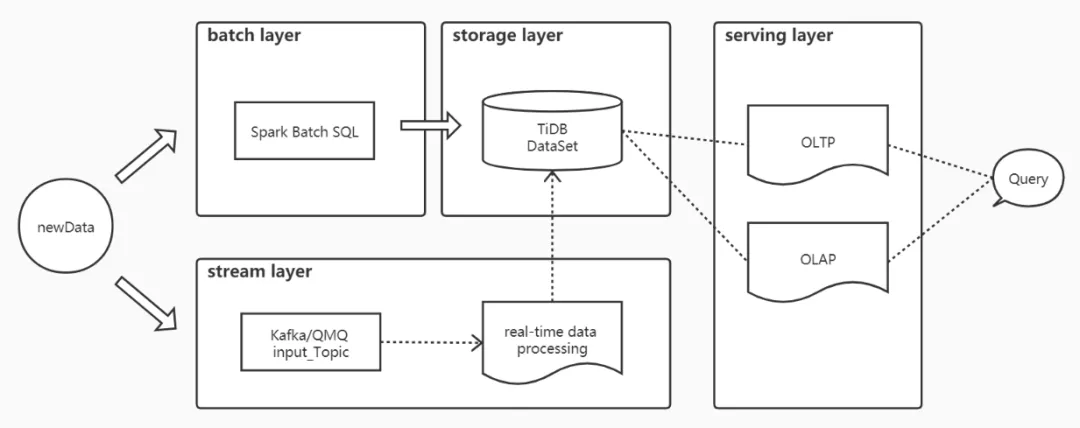
图 4-2 CDP 持久化流程
持久标签的访问主要场景有两个,一种是跟现有 CRM 系统对接,在线根据业务的特征圈选符合条件的业务数据,这种场景的查询条件不固定,返回结果集因筛选条件而定,对于数据存储引擎的数据计算和处理能力要求比较高,即我们在数据处理领域经常提到的 OLAP 的场景。另一种场景是线上业务根据前端传入的业务标签相关的唯一标识来查询是否满足特定业务要求,或者返回指定特征值,满足业务处理的需要,需要 ms 级响应,对应的是 OLTP 场景。
五、业务应用
5.1 实时触发场景应用
在 Trip 的很多业务场景中,需要对多条业务输入数据做清洗、整合、计算加工处理之后再反馈应用到业务场景中去,促进业务增长。比如 Trip 一些产品线的促回访、促首单、促复购、优惠券过期、APP 新用户触达等 App Push 和 Email 邮件营销和消息等场景,提升 Trip 产品曝光和转化效率。
以 Trip 某产品促回访 APP Push 推送消息为例,从页面的浏览行为到触发发送的流程可以分为几个部分:
1)发生浏览行为;
2)CDP 实时获取和处理目标行为日志数据,发送给发送通道;
3)发送通道完成消息发送前处理;
4)根据针对该产品的不同浏览行为发送不同内容的消息。
根据该产品实时促回访场景业务需要,以及 CDP 实时触发场景支持的算子,配置过滤任务从而动态过滤出该产品促回访场景需要的数据,根据不同的浏览深度打上不同的标签,推送通道根据深度标签给不同的客户端推送不同的内容,具体的 CDP 配置算子业务逻辑如图 5-1。
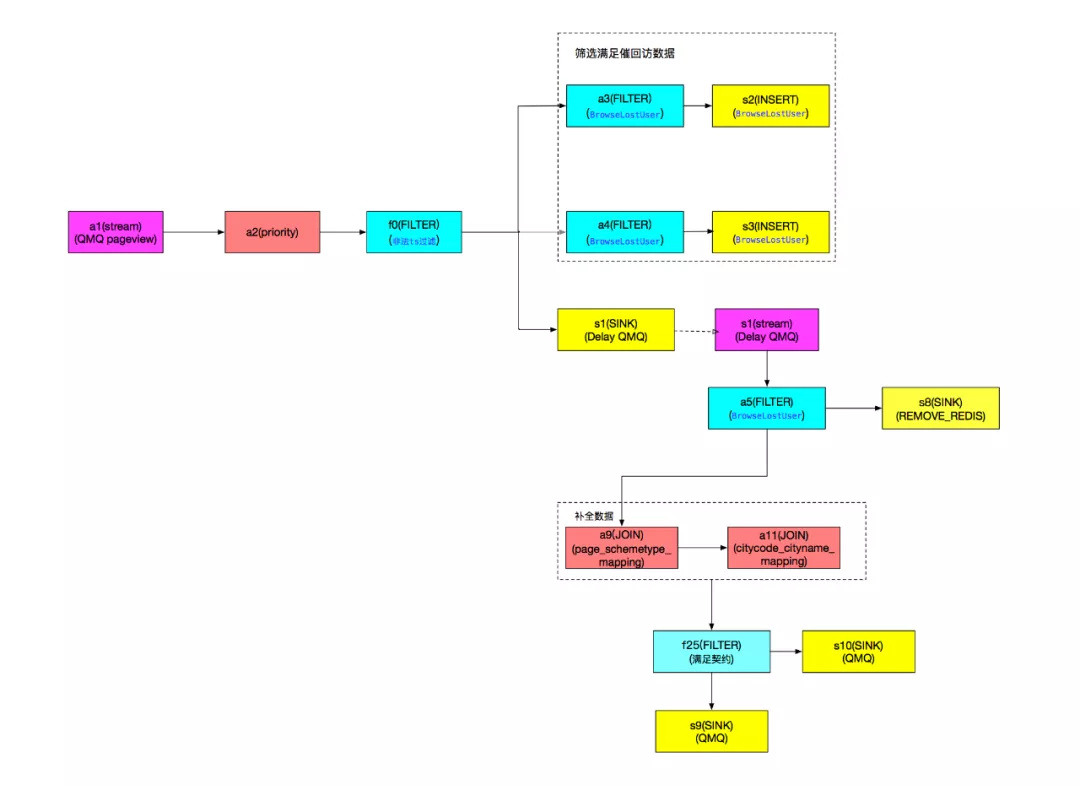
图 5-1 CDP 某 Trip 产品促回访触发逻辑示意图
通过 CDP 实时触发场景配置,系统可以根据配置动态生成任务,不需要额外的代码开发,并且配置可以动态修改,动态生效,不需要编译、重启任务。目前这种方式从运行效果来看时效性更高,更灵活,更稳定,开发测试成本更低,不需要走代码开发、编译、测试、发布的流程。
5.2 标签持久化
在第一节中我们提到来自不同业务系统的数据都会有对应的 ID 及标签与之对应,我们在持久化这些标签的同时根据业务需要建立这些 ID 之间的 Mapping 关系,如果是一一映射我们会直接存储 Mapping 关系,如果是多对多的关系我们会根据业务需要,按照首次、最近、全部映射关系等等方式落地 ID Mapping 关系,方便用户筛选时串联不同 ID 的特征。
目前 CDP 已经上线跟携程国际业务相关的业务系统经过实时清洗、转换和整合处理后落地的业务特征标签库,系统通过 API 的方式对外提供相关数据查询和计算服务。目前 CDP 在跟 Trip 各个业务系统深度整合打通,为国际业务增长提供业务特征标签库的数据和服务支持。