为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
Linux
【概述】场景+问题概述
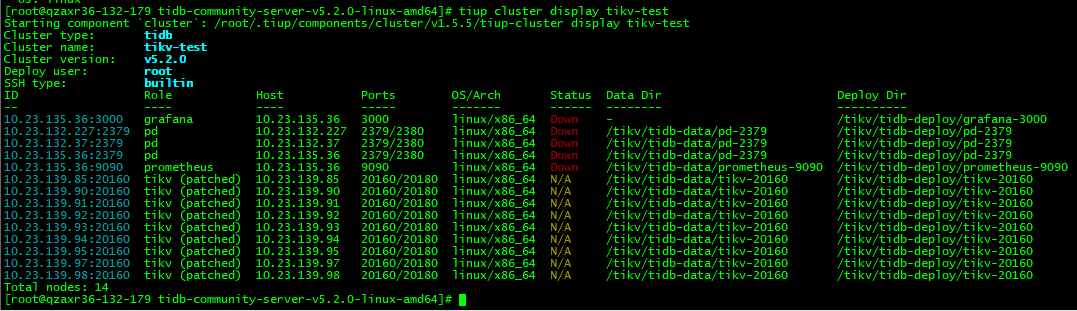
部署环境是3个pd-server,部署在3台机器上,有2台服务器下线了,被强制关机,tiup cluster display查看集群所有pd都处于down状态,现在想从仅存的一台pd-server(10.23.132.37:2379服务进程在但状态down,另外2个机器都下线了,没办法起来)上恢复3节点,该怎么操作?
【背景】做过哪些操作
1、尝试先扩容,再把下线的2个pd缩容,但是发现扩容的时候连接新机器失败,为啥会去Get “http://10.23.132.182:2379/pd/api/v1/config/replicate”,服务不还没部署起来嘛?这种情况该怎么操作?
能强制先踢出2个故障pd,集群以1个pd提供服务,再走扩容到别的服务器上?这样操作会不会也扩容不起来?
【TiDB 版本】
tikv 5.2.0
【附件】
-
TiUP Cluster Display 信息
-
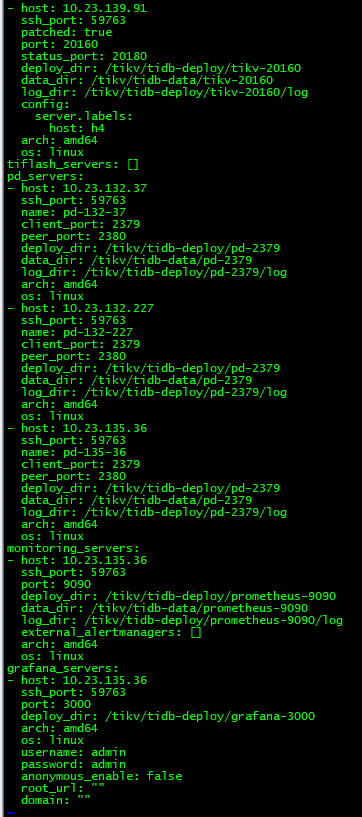
TiUP Cluster Edit Config 信息(部分)
-
TiDB- Overview 监控
2 个赞
Meditator
(Wendywong020)
2
1 个赞
这个案例我有点疑问:
1、恢复前是要把所有的pd数据目录都删除,重新恢复吗?
2、是只保留一个pd-server,故障的都scale-in出去?
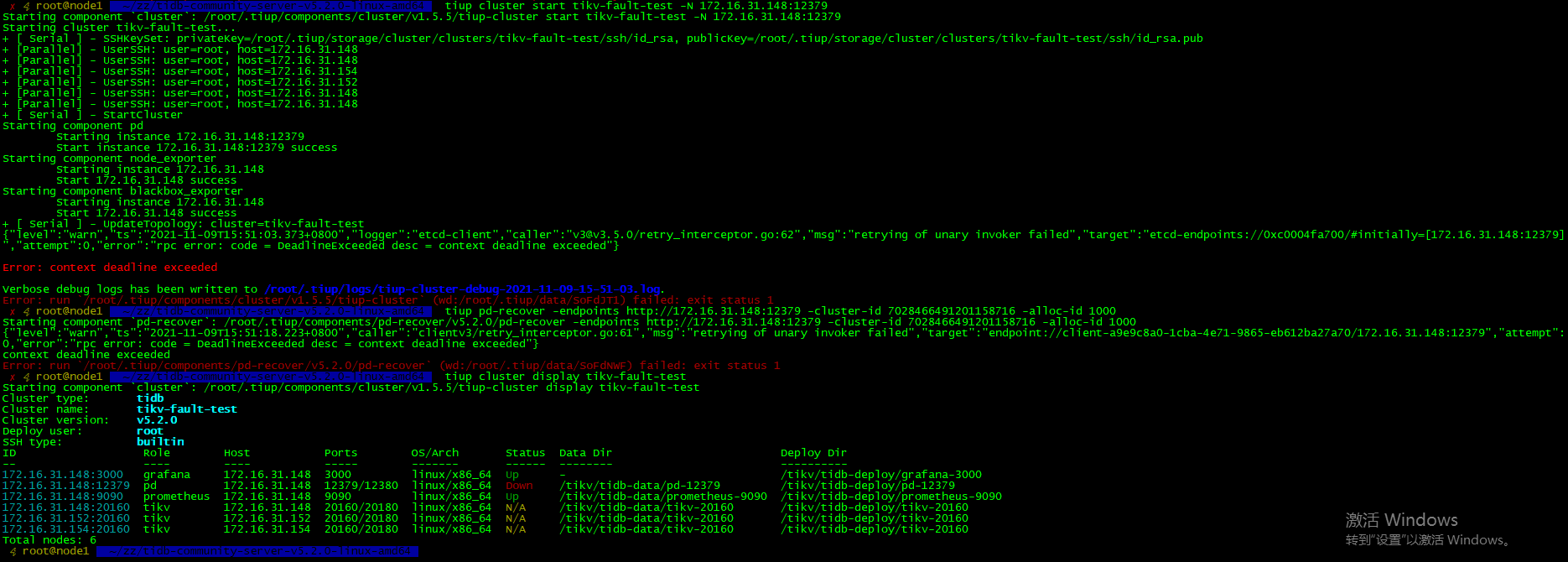
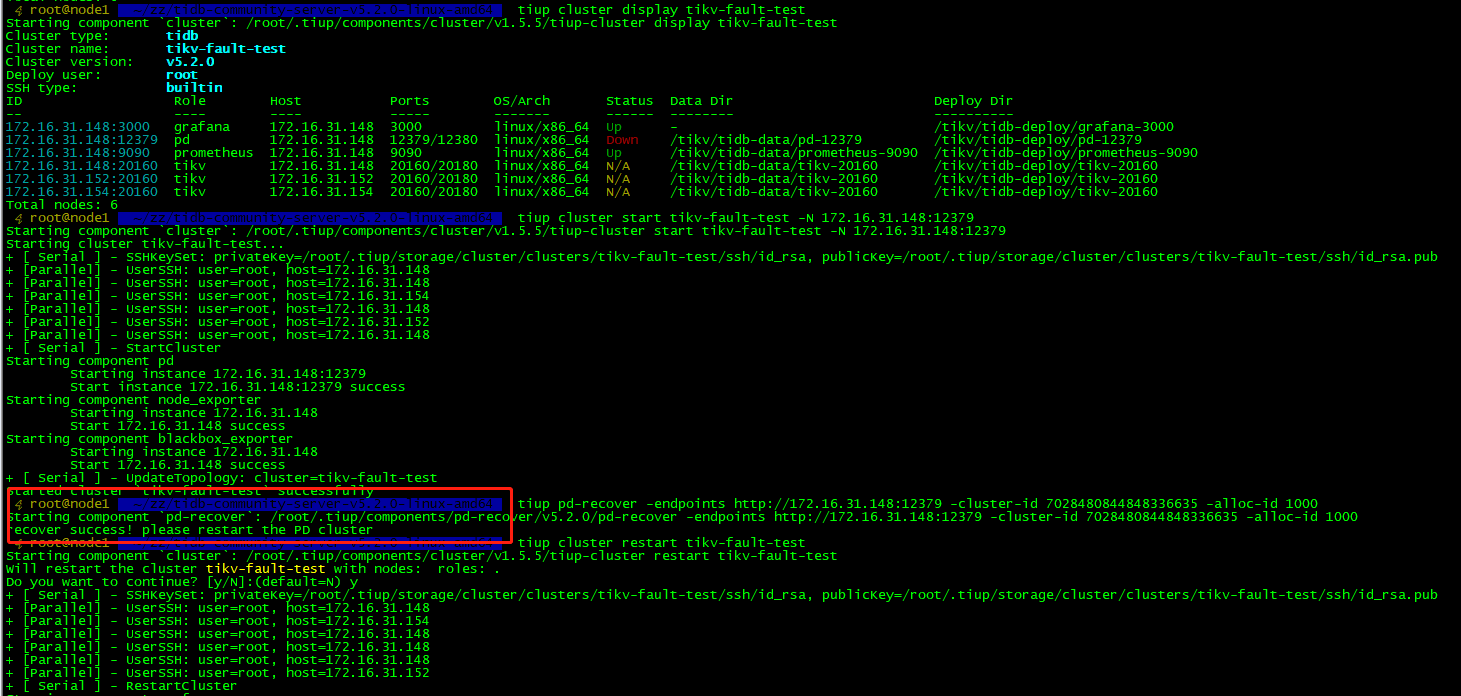
我按上面的方法,最终tiup pd-recover操作时还是失败:
Meditator
(Wendywong020)
4
这个是模拟 所有pd节点所有数据目录都被误删除后恢复的
嗯,我尝试了3个节点的pd恢复,数据目录也都删除了,pd-recovery都是失败,改成1个pd的集群,pd-recovery能成功,但tikv-server启动不正常
实在是不明白哪里操作不对。
Meditator
(Wendywong020)
6
需要主要的两个地方
1)这种恢复,理论上新建集群(因为pd不存储tikv元数据,ticdc的changefeed除外),但是新集群的cluster-id和alloc-id要和原来的保持一致,否则tikv无法识别
2)pd集群缩成一个的时候,启动的时候 注意配置文件,因为pd-server的配置中init-cluster是配置了三个节点的
嗯嗯,启动脚本里面还有initial-cluster配置要改掉,忽略了这点,pd-recovery才一直失败,还有就是cluster id找错了,我只找了pd的日志,tikv日志没查,用了错误的cluster id,大概明白意思了,谢谢
奇怪为什么pd日志里面只搜索到一个cluster id,为什么会和tikv-server的不一样,哪里能得到准确的cluster id?
Meditator
(Wendywong020)
9
找第一次出现的,只要是空的(数据目录为空)pd-server启动一次,就会生成一个不同的cluster-id
想在请教下,如果集群中3个pd都挂了,deploy目录和data目录都不见了,这种情况怎么恢复,前面的至少还有个服务能启动,有其他帖子说先搭建个空白pd集群,不懂通过什么步骤搭建空白pd集群。
Meditator
(Wendywong020)
14
看看上面的链接,内容就讲了 pd全挂的情况 如何恢复pd集群。
好像不太一样,上面的只是数据目录丢了,我意思是连deploy/pd-2379目录也不在了,服务启动不了,是不是可以找个地方复制一份deploy的目录过来,根据实际情况修改下,让pd服务能启动,后续就走pd-recover的流程
system
(system)
关闭
17
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。