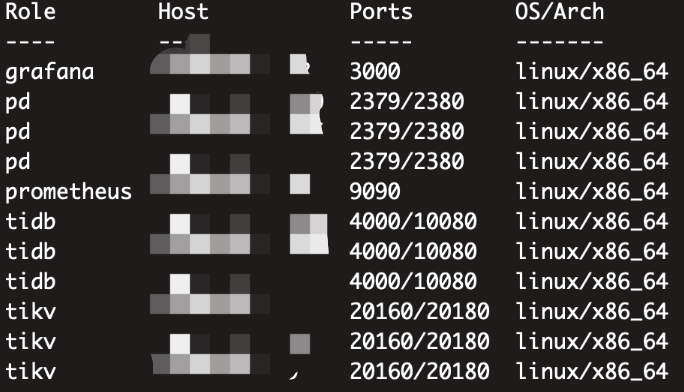
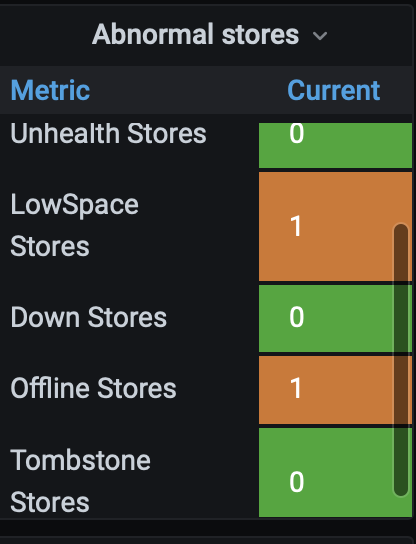
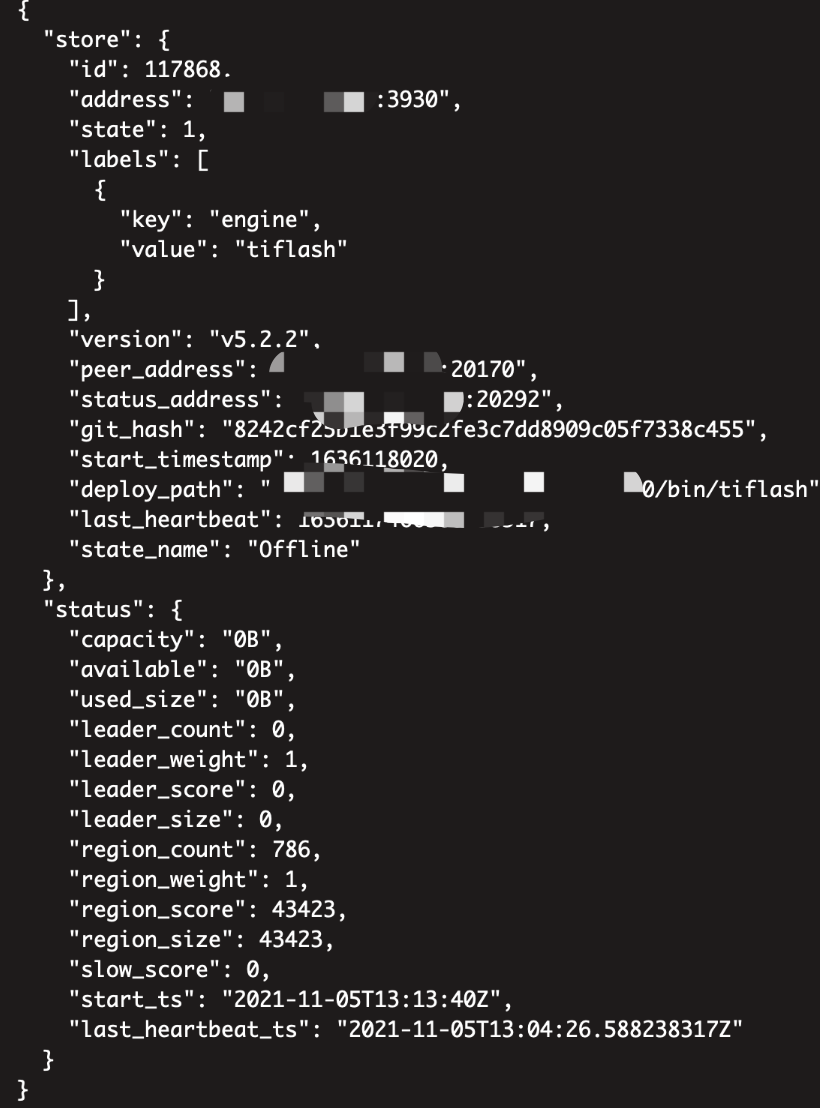
集群由4.0.13升级5.2.2,升级后tiflash无限oom起不来,将tiflash副本全部置为0后,对tiflash进行强制线下,scale-in --force,结果tiup查看拓扑图已经没有了,dashboard和grafana上还有残留:
由于5版本去掉了强制置为 tombstone,这个节点怎么也删不掉了,store remove也不行
反正就是我现在想把tiflash完全T掉,根本不可能了?参考别的文章说 加个节点让tiflash副本补充回来,这个节点就会变为tombstone了,我现在就不想要tiflash,也不让删,服了,这设计不是有问题吗?
birdstorm
2021 年11 月 5 日 16:13
3
您好,可以参考下这个文档中关于缩容 TiFlash 节点的部分。
https://docs.pingcap.com/zh/tidb/stable/scale-tidb-using-tiup#缩容-tiflash-节点
请确认一下在操作前是否所有的表已经通过 alter table 命令删除了 TiFlash 副本。
另外对于 TiFlash 升级后无限 OOM 的情况,能否帮忙提供一下 TiFlash 的日志信息我们可以分析一下?非常感谢!
1 个赞
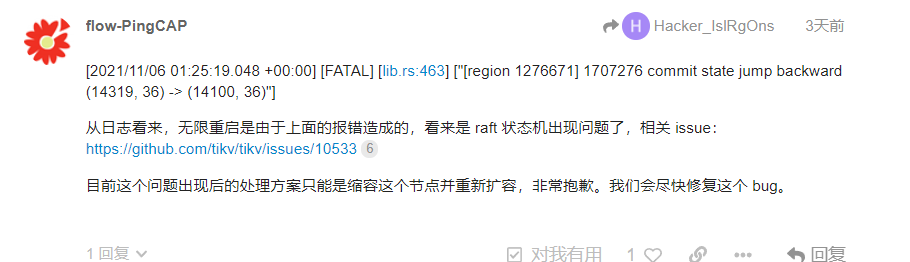
看了下不是无限OOM,是内存达到10%就重启,日志见此贴:tiflash第七次起不来,4.0.13升级5.2.2后,tiflash起不来,内存到10%就自动挂了无限重启
强烈建议 可以设置tombstone状态,之前4.0下线特别顺畅,自己可以控制tombstone,5.0只能等调度补充完,我们集群region 几十万个,宕机一个节点就 region is unavaliable了,等这个全调度完,业务线早崩了,我看其他帖子 因为无法设置tombstone的也好几个了,都被整个下线整疯了,强烈建议改回来
无限重启的问题我在帖子里回复了,是已知的 bug。
缩容的问题,我的同事在帖子中回复了这个文档(https://docs.pingcap.com/zh/tidb/stable/scale-tidb-using-tiup#方案二手动缩容-tiflash-节点 ),看看是否可以解决您目前问题。无法强制设置 Tombstone 的问题,我们会继续跟进,非常抱歉。
我们测试环境升级遇到这个问题,是用的方式二,store delete根本没用,副本也不会被调度,还好learner比较少,手动删pd规则没花多少时间,但是生产 learner 十几万,用这个一个一个删就呵呵了,我们之前可以吧tiflash replica 设置为0,再scale-in --force,再吧tiflash置为 tombstone,再remove掉就清理干净了,重新扩容tiflash就可以了,这个很快几分钟十几分钟就搞定了,现在由于不能设置tombstone,就不能scale-in --force,否则会有脏数据,我们之前已经踩过这个坑了,就只能把调度频率调高,加快调度补充副本,这期间的几个小时整个集群不可用
spc_monkey
2021 年11 月 9 日 03:17
9
去掉这个命令的原因是:这个命令在有些情况下,可能会引起更严重的问题,担心很多不了解命令后面逻辑的情况下使用。后面其实有针对下线或异常节点处理的逻辑有优化,应该快发布了
2 个赞
spc_monkey
2021 年11 月 9 日 03:35
11
不过建议你们是否可以多搭建一个 tiflash,replica 设置为2,能提高你们的 业务可用性(而且v5 的MPP 你一个节点也用不了啊,性能和 MPP 其实差距很大的),另外,tiflash 本身对资源的利用率和消耗,记得也在开发计划中了,但 GA 时间还不确定
1 个赞
测试环境的一个tiflash,生产环境是3个tiflash,每台36c 72G的两副本,现在就是因为tiflash的bug导致起不来,只能等30分钟,变为down,然后再等pd调度补充副本,在等待变为down和 调度补副本这段时间,大概两小时,业务都是没法用的,这点特别伤
1 个赞
spc_monkey
2021 年11 月 9 日 03:53
13
”现在就是因为tiflash的bug导致起不来,只能等30分钟,变为down,然后再等pd调度补充副本,在等待变为down和 调度补副本这段时间,大概两小时,业务都是没法用的,这点特别伤“,确认一下,你这个是说的生产环境遇到的问题吗?(生产环境是3个tiflash,每台36c 72G的两副本)
1 个赞
生产和测试都遇到这个问题了,该帖子已经回复说是bug了
之前集群都是正常状态,还在提供服务,进行了不停机升级,其他节点都起来了,就这个tiflash起不来,这是升级自己启动的,和停机时机有关?其他两个并没有出现这个问题
单节点tiflash 数据量100G,region 4500个左右
[image]
1 个赞
spc_monkey
2021 年11 月 9 日 04:27
15
OK,1、30分钟的哪个参数,pd-ctl可以动态修改的(比如改成5分钟)2、调度的话,需要pd-ctl limit 和 store limit 2个一起配合(为了使降低对业务的影响,只针对制定 store 提高限制)
1 个赞
是的,我就是这么处理的,我是把limit的相关参数调的特别高了,几千,也需要一个多小时的
1 个赞
system
2022 年10 月 31 日 19:08
18
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。