panbc
2020 年1 月 4 日 05:05
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
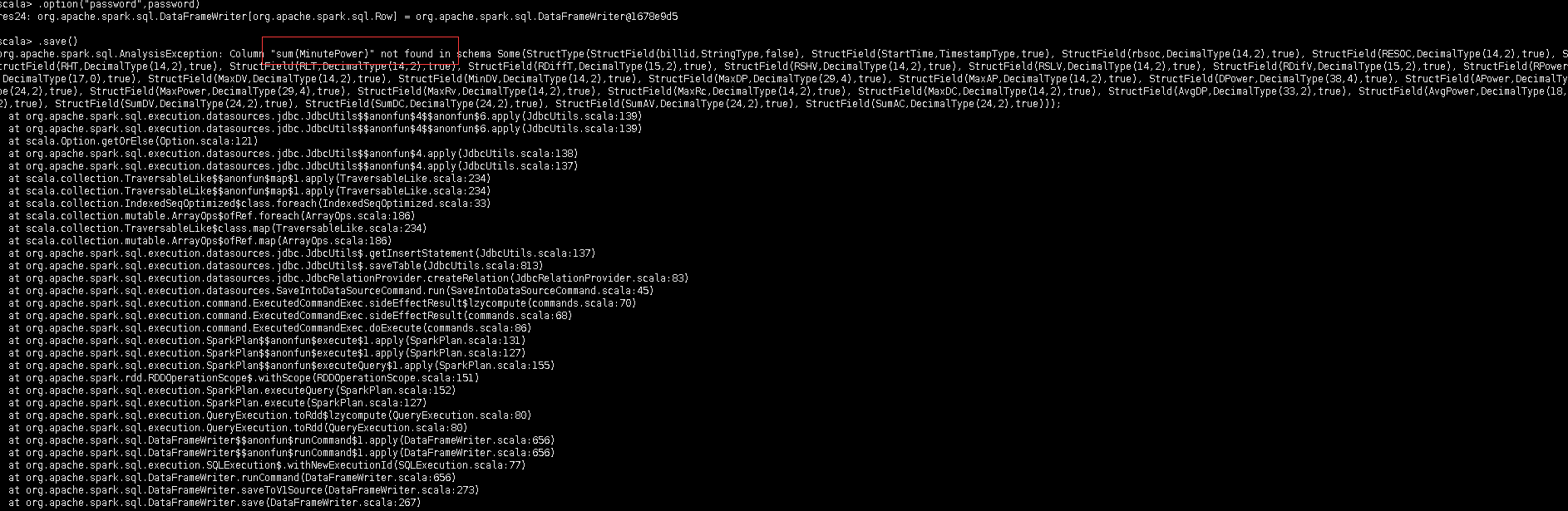
1.使用tispark进行sql执行时,提示列不存在,实际列是存在的,只不过是用的聚合函数
sql:
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出的打印结果,请务必全选 并复制粘贴上传。
1 个赞
panbc
2020 年1 月 4 日 05:35
2
看起来表的schema 找的不对,提示的schema不是这个表的
qizheng
2020 年1 月 4 日 06:55
3
麻烦发一下使用的 tispark 和 spark 的版本
panbc
2020 年1 月 4 日 08:19
4
tispark/spark-2.3.3-bin-hadoop2.7
panbc
2020 年1 月 4 日 08:20
5
比较着急,因为是线上的服务,有没有什么比较好的方式
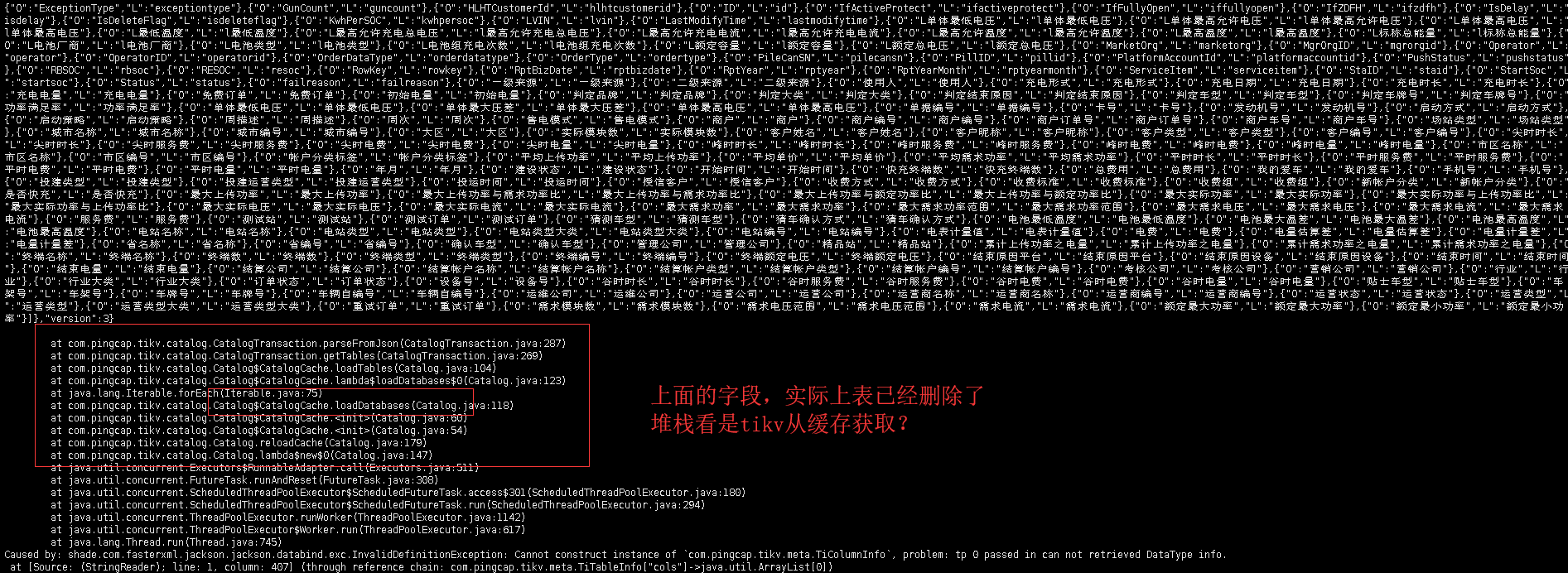
提示的表,实际上是已经删除的一个表。tispark已经重启了,是从tidb的缓存版本获取的
有没有清除缓存之类的临时办法
birdstorm
2020 年1 月 4 日 09:29
8
从报错信息看的确该表内没有 MinutePower 列,能否提供 ETL_SingleCharging 表的 schema 信息?
另外最好能给一下完整的堆栈信息我们好定位问题。
panbc
2020 年1 月 4 日 12:45
10
数据结构是有minutepower,但是提示的后面的数据结构是删除的表的列
qizheng
2020 年1 月 5 日 06:36
11
麻烦用 printSchema 或 desc 查下 ETL_SingleCharging 表的 schema,看看是否有类似的报错。