为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:5.7.25-TiDB-v3.0.1
- 【问题描述】:
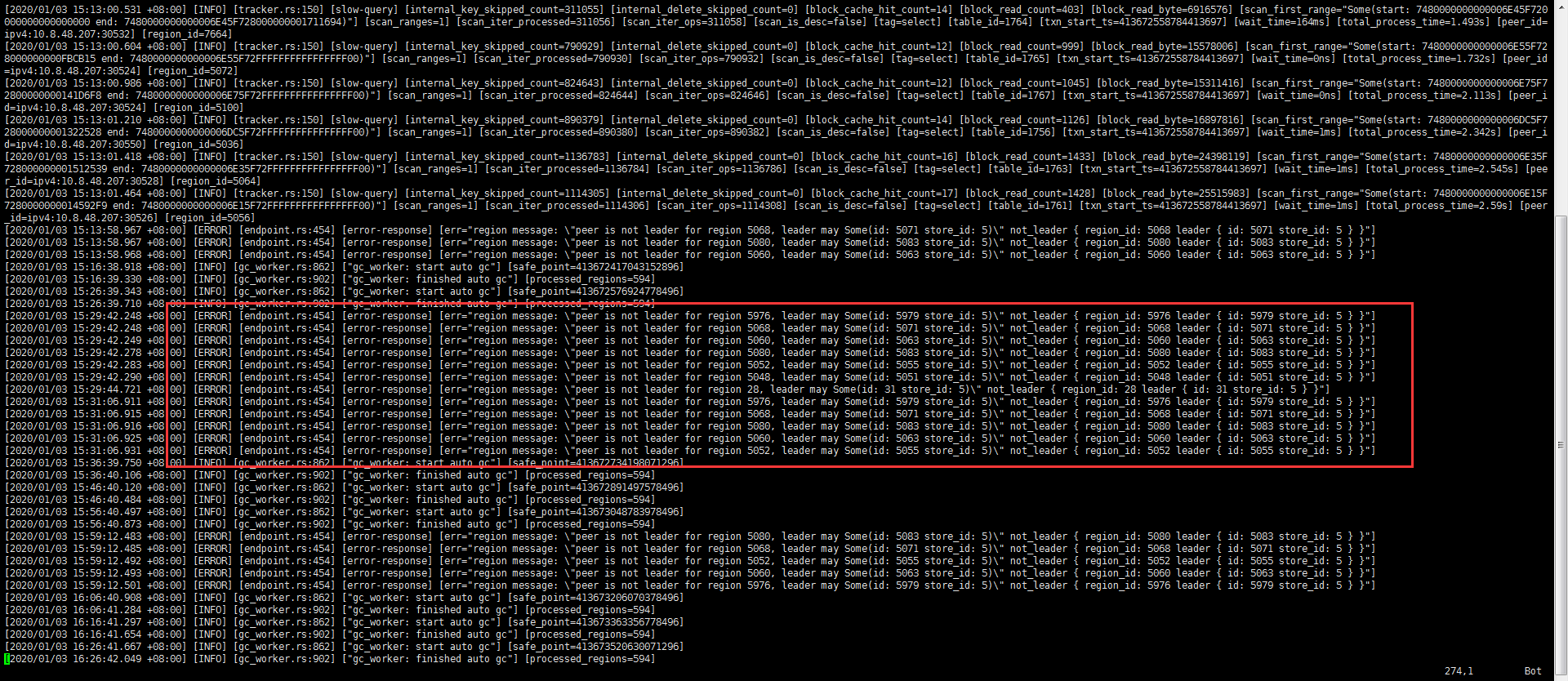
tidb日志文件中,有大量错误信息
[2020/01/03 15:31:06.920 +08:00] [INFO] [region_cache.go:516] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=5060] [currIdx=0] [leaderStoreID=5]
[2020/01/03 15:31:06.926 +08:00] [INFO] [region_cache.go:516] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=5052] [currIdx=0] [leaderStoreID=5]
[2020/01/03 15:31:08.996 +08:00] [INFO] [coprocessor.go:726] [“[TIME_COP_PROCESS] resp_time:2.659179826s txnStartTS:413672828543696898 region_id:28 store_addr:10.8.48.204:20160”]
[2020/01/03 15:31:09.134 +08:00] [WARN] [client.go:663] [“wait response is cancelled”] [to=10.8.48.204:20160] [cause=“context deadline exceeded”]
上下文日志
tidb_0103.log.tar.gz (31.0 KB)
目前系统中没有任何应用。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。