- 系统版本 & kernel 版本: CentOS7.5
- TiDB 版本:v2.1.8
- 磁盘型号:ssd
- 集群节点分布:节点1:中控机、PD1 节点2:tikv1、PD2 节点3:tikv2、tidb1 节点4:tikv3、tidb2
- 数据量 & region 数量 & 副本数:数据量20G左右
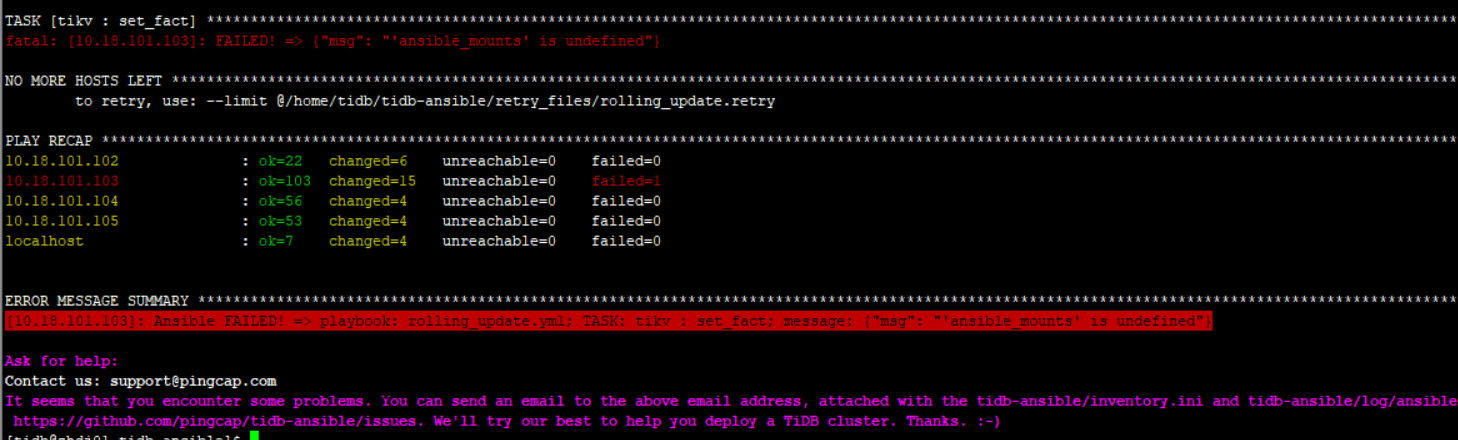
这个报错算是 ansible 的一个 bug ,这样 ansible-playbook rolling_update.yml -e “gather_timeout=30” 升级试下。
参考上面给出的步骤,加上 -e 参数升级试下。
稍等,问题再跟进。
尝试将 gather_timeout 调大到比如 120;如仍有报错,执行下面的命令查看输出结果是否正常
ansible 10.18.101.103 -m setup -a “gather_subset=‘hardware’ filter=‘ansible_mounts’”


这次的报错和上面的报错已经不同,请查看下 101.103 这台服务器上的 pd 日志,是否有有效的信息~
日志里没有看到有效信息,发现PD的版本是高版本了

1、你那里升级的目标版本是 3.0.6 吗?
2、检查下其他节点是否已经升级到目标版本
目标版本是3.0.6 。其他节点PD都到3.0.6了,tikv,tidb还是老版本2.1.6
1、通过如下方式确认 pd 已经升级到新版本:
1)pd 的 日志,过滤 version 关键字
2)pd-server -V 查看
2、确认下 pd 节点状态是否健康:
./pd-ctl member -u http://ip:port
./pd-ctl health -u http://ip:port
3、如果 pd 节点都确认正常,可以指定 --tags=tikv\tidb 来分别依次升级 tikv ,tidb,建议先升级 tikv,然后是 tidb
[quote=“zhenjiaogao-PingCAP, post:13, topic:2337”] pd已经升到新版本,而且都健康。指定tikv升级报原来的错
v ,tidb,建议先升级 tikv,然后
[/quote]
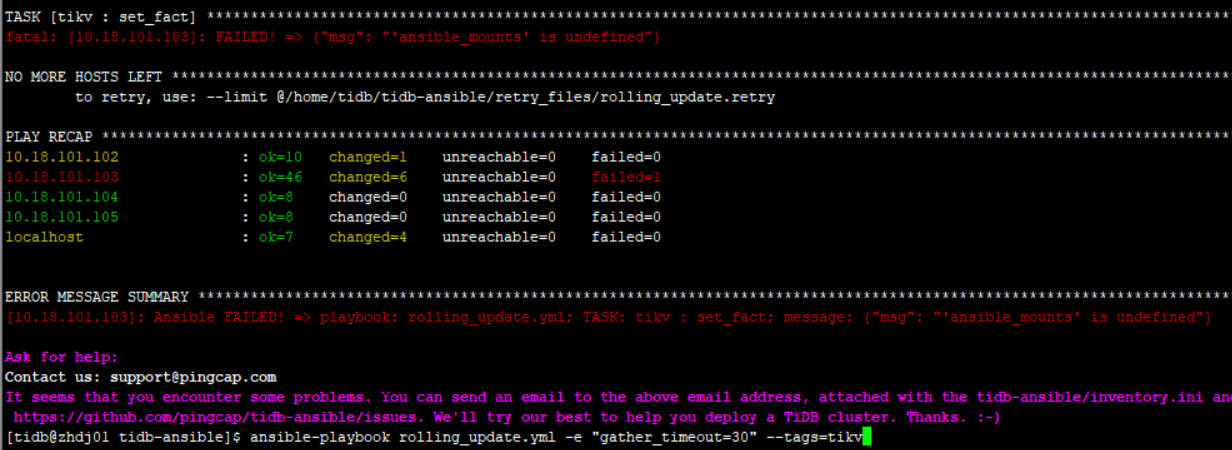
可以按照上面 pd 报错处理的相关流程看下~
按PD相关流程操作了一遍tikv升级,报错一样

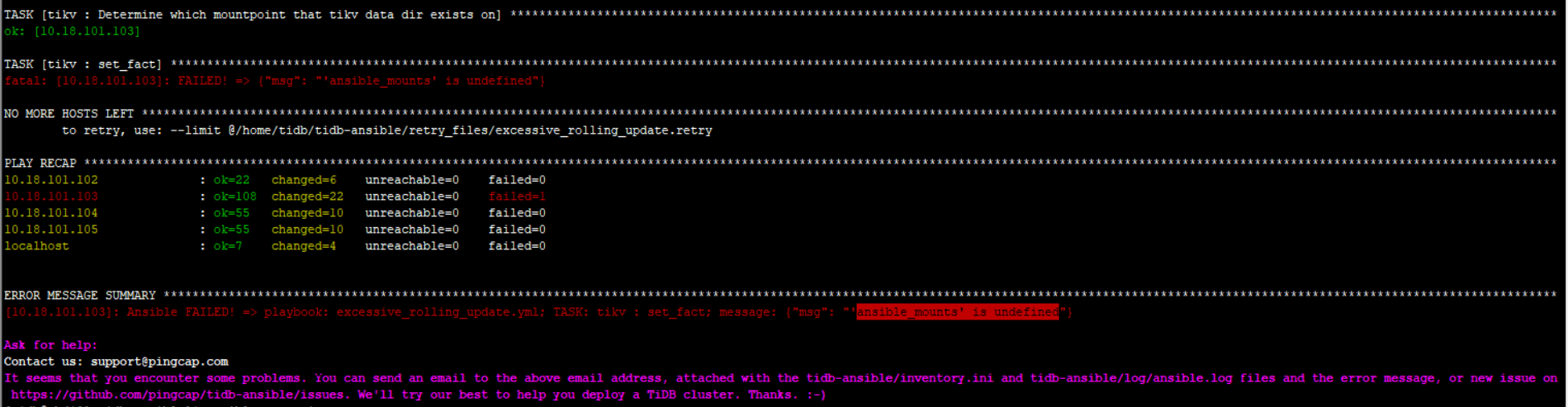
TiDB < 3.0 版本升级到 3.0 以上请运行 ansible-playbook excessive_rolling_update.yml 进行升级。
两种方法都试了,现在各种尝试PD的版本到了目标版本,3.0.6 。tidb有一个节点到了3.0.6。tikv的版本还都是旧版本。指定升tikv或tidb都报错 ansible_mounts is undefined 。不知道怎么解决了
可以尝试一下 ansible-playbook excessive_rolling_update.yml 不要加 -l 以及 --tags 进行限制。 另外看最近 TiDB 升级时候的报错。麻烦检查下 对应 TIDB 机器的错误日志。