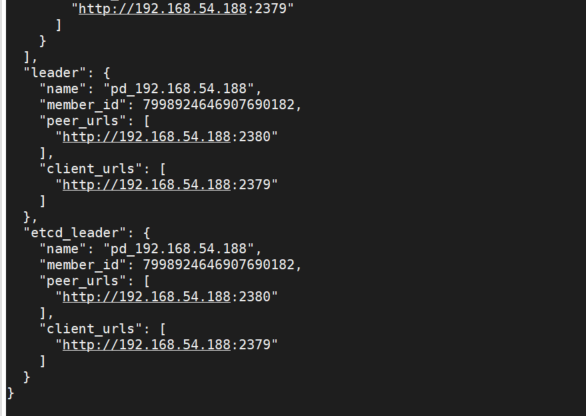
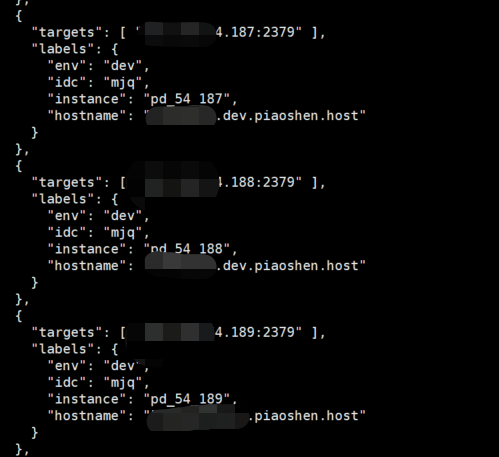
Prometheus配置文件和granfana图形,三个pd集群,总共9台服务器,但是instance只显示了6台,从granfana上看,能收到比如54.188的数据
确定两个问题:监控不展示的信息在通过 Prometheus 拿 metric 的时候有吗?如果有,pd-ctl ->member 找下 pd 的 leader 节点,在监控部分选 leader 的 IP 看下展示的信息。Prometheus 没有的话在没有监控的信息的机器上看下 node_exporter 是否在运行,异常的时候根据 log 信息排查下。
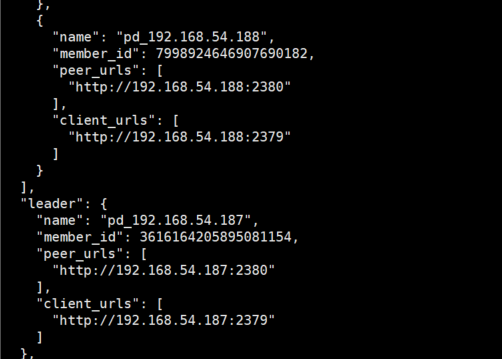
pd-ctl -u “http://192.168.54.188:2379” -d member 能看到leader是187
188 所有的指标都没有还是缺少部分的?如果是都没有看下机器上 node_export 是否正常,可以看下对应日志。
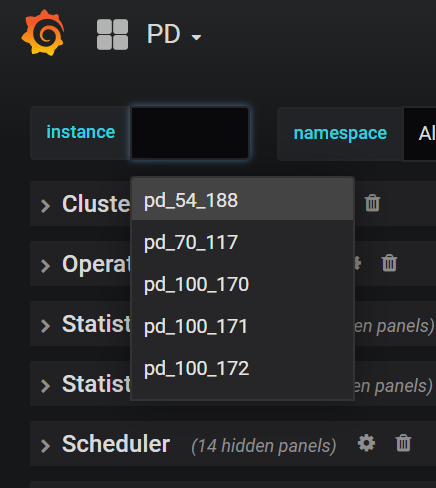
默认情况下 pd 的 instance 只会显示 leader 所在的节点;
如果 pd leader 发生切换,切换到新节点,才会显示该节点对应的 instance;
从监控看,三个集群的 pd 都有了,其他网段显示不全可能是 pd leader 没有发生过切换或只切换了一次。
你看我Prometheus收集的数据记录,70.117是leader 怎么也没有?
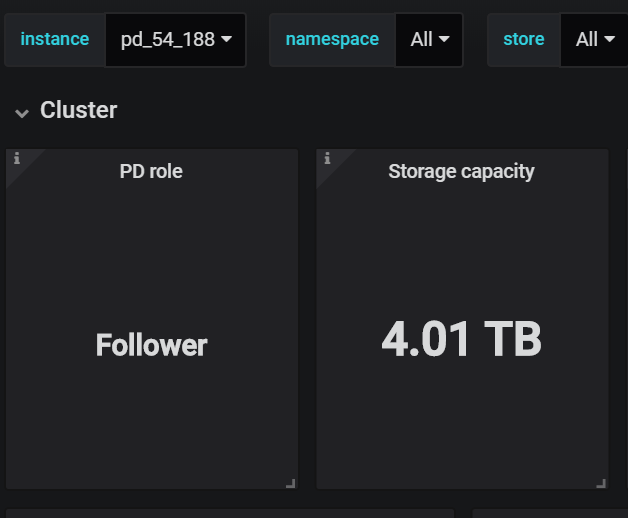
截图显示的是 etcd leader,可能和 pd leader 不是同一个 instance,以 pd-ctl > member 看到的 leader 为准,或者通过 pd 监控 PD Role 面板下的 metric 确认
count(delta(pd_server_tso{type=“save”,instance=“$instance”}[1m]))
是同一个instance,job=tidb 这个是标记的job name 别的job name不会到这里
而且 pd-ctl > member 看到的 leader也是跟监控一样 le
尝试使用 pd-ctl ->member leader transfer pd3 切换 pd 的 leader 到 188 上面看下监控信息是否能展示。
难道只显示leader的??follow节点不显示??
只参考 pd leader 的监控信息就可以,切完之后 188 显示的监控信息完整吗?
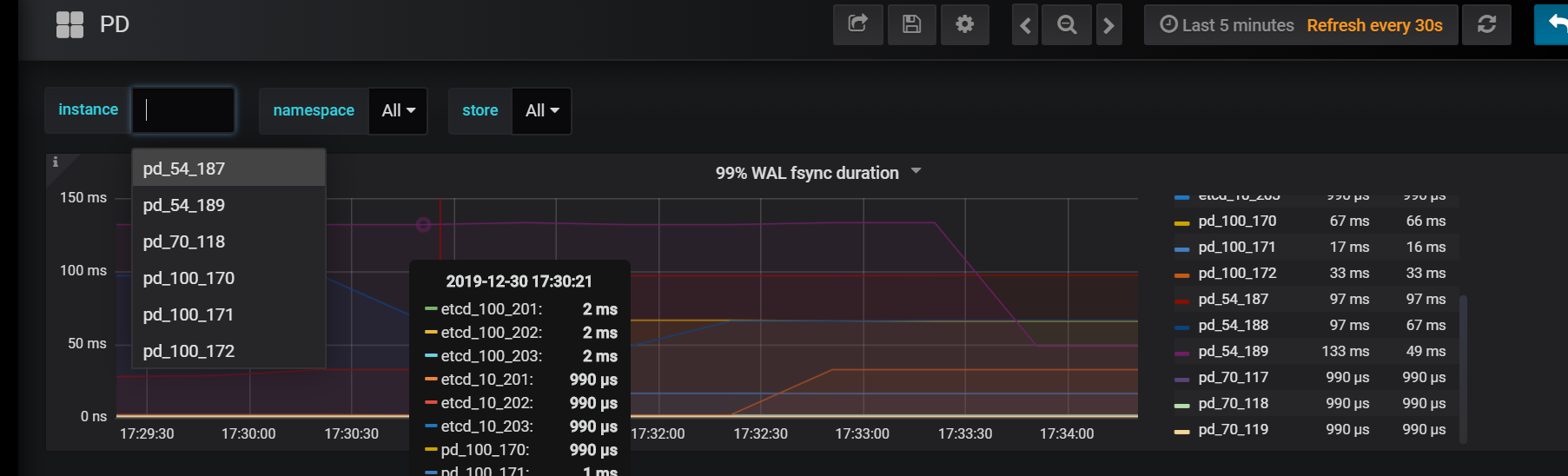
倒也能看。。但是你看100网段的leader和follow都显示。。这领导要是问起来一样的集群怎么有这差异。。不好解释呀
count(delta(pd_tso_events{type=“save”,instance="$instance"}[1m]))改成 count(delta(pd_server_tso{type=“save”,instance="$instance"}[1m])) pd_tso_events在Prometheus里没有收集到数据。。你们试试看吧。。。切换了一下100网段各个pd 现在只显示leader的ip了。。
好的 ![]()