为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:5.7.10-TiDB-v2.0.11
【问题描述】:tidb 版面升级到3.0最新版本,参考的升级操作步骤为
https://pingcap.com/docs-cn/stable/how-to/upgrade/from-previous-version/
升级命令为 “ansible-playbook excessive_rolling_update.yml”
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出的打印结果,请务必全选 并复制粘贴上传。
yilong
2019 年12 月 26 日 06:54
2
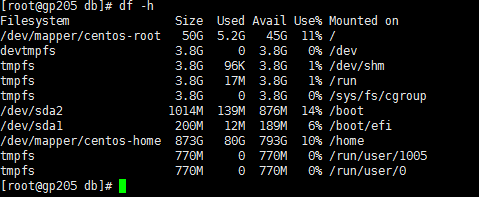
df -h , df -i 看一下升级的服务器是不是磁盘满了?
服务器磁盘剩余空间比较大的,这是测试服务器,tidb安装在/home/tidb下面
我的组网情况是,
yilong
2019 年12 月 26 日 07:23
4
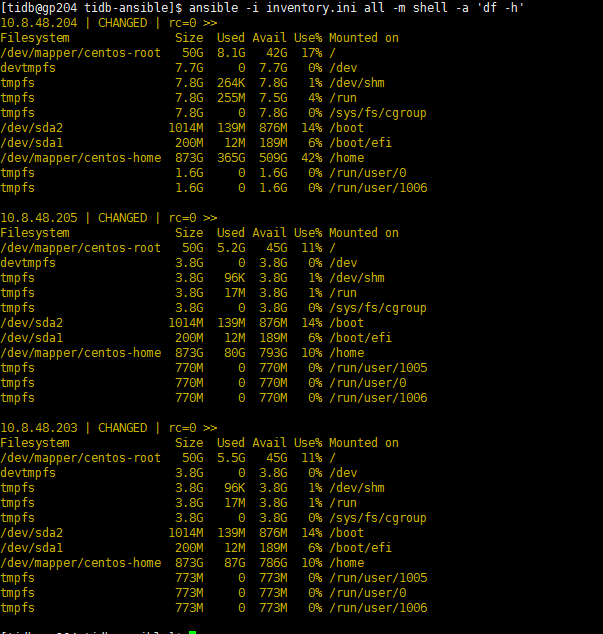
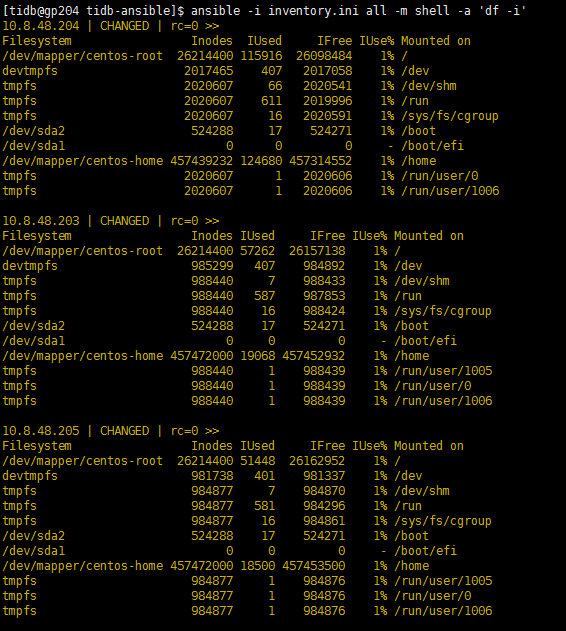
集群拓扑是什么样的呢? 几个tidb,pd? 另外查一下所有机器的df -h 和df -i
yilong
2019 年12 月 26 日 07:37
6
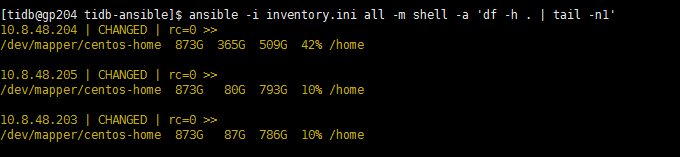
麻烦执行下这个命令 df -h . | tail -n1
yilong
2019 年12 月 26 日 08:09
8
取消升级,在升级命令后增加 -vvv看一下能否打出详细信息,多谢
您好,我再次执行升级,报错如下,需要把tidb集群停止,再升级吗
我把原集群停止后,用命令ansible-playbook start.yml 启动报错,再怎么都启动不起来,可以从哪儿定位呢,我看了log日志,里面也没有关于这个端口启动的错误信息
您好,日志如下ansible.tar.gz (97.3 KB)
执行excessive_rolling_update.yml 报错后,我这边在三个尝试了再次滚动升级,然后出现错误信息:
现在通过 ansible-playbook start.yml 启动集群,目前 pd 启动是正常的,现在启动 tikv 并且验证 tikv 服务是否正常报错,连接被拒绝,说明对应节点的 TiKV 服务没有启动:
2019-12-26 16:43:42,043 p=11160 u=tidb | fatal: [10.8.48.204]: FAILED! => changed=false
attempts: 12
content: ''
msg: 'Status code was -1 and not [200]: Request failed: <urlopen error [Errno 111] Connection refused>'
redirected: false
status: -1
url: http://10.8.48.204:20180/status
2019-12-26 16:43:42,044 fail [10.8.48.204]: Ansible Failed! ==>
changed=false
attempts: 12
content: ''
msg: 'Status code was -1 and not [200]: Request failed: <urlopen error [Errno 111] Connection refused>'
redirected: false
status: -1
url: http://10.8.48.204:20180/status
2019-12-26 16:43:42,346 p=11160 u=tidb | fatal: [10.8.48.205]: FAILED! => changed=false
attempts: 12
content: ''
msg: 'Status code was -1 and not [200]: Request failed: <urlopen error [Errno 111] Connection refused>'
redirected: false
status: -1
url: http://10.8.48.205:20180/status
.....
可以通过一下操作分别验证 tikv 的状态是否返回正常:
通过 ssh 登陆到目标 tikv 检查服务状态是否正常(ps -ef |grep tikv-server)以及 tikv 的日志是否有 “Welcome" 关键词且 对应的时间 是否为 ansible-playbook 拉起 tikv 的时间的 log 日志,并反馈 tikv log 的日志报错。
如果 tikv log 中发现 tikv 没有被拉起,同时 tikv 服务不正常,需要确认 tidb-ansible 中 start.yml 执行启动的 tikv 的 systemd 的 service tikv-{{ tikv_port }}.service 是否正确,对应的位置在 /etc/system/systemd/ 下面有启动服务文件,start.yml 中的启动脚本为:
- name: start TiKV by systemd
systemd: name=tikv-{{ tikv_port }}.service state=started enabled=no
become: true
when: process_supervision == 'systemd'
- name: wait until the TiKV port is up
wait_for:
host: "{{ ansible_host }}"
port: "{{ tikv_port }}"
state: started
msg: "the TiKV port {{ tikv_port }} is not up"
注意
最后一次执行的 “excessive_rolling_update.yml ” 的 ansible-playbook 中,实际只操作到 停 PD server ,对 TiKV 没有操作。建议先确认一下集群的 PD、TIKV、TIDB 节点状态是否都是正常的。
我这边重新把tidb集群启动起来了,昨天启动失败,是因为使用了新下载的tidb-ansible文件夹中的start.yml启动,
启动成功后,再次升级,报错信息如下,和昨天是一样的。
昨天就是看到这个错误信息,才把tidb集群stop掉的。结果还是不行
1、请再次上传下 upgrade 的日志
2、再检查下 pd 的服务现在使用正常:
https://pingcap.com/docs-cn/stable/reference/tools/pd-control/#下载安装包
3、生产环境建议 pd 节点为 3 个,确保 pd 节点的高可用,pd 节点负责分配全局的 tso,peer id,region id 以及调度相关,如果 pd 节点不可用,会影响 tidb 的正常使用。
1 upgrade日志ansible.tar.gz (111.2 KB)
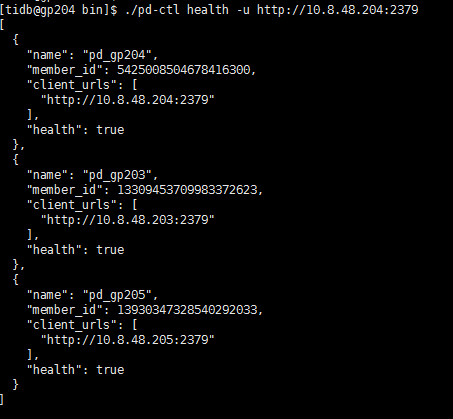
2 用升级下载下来的tidb-ansible/resource/bin/pd-ctl执行health命令,使用的是127.0.0.1,找不到端口
但是用另外一个命令,又能连接的上
3 这个是测试环境,就是测试版本升级,成功之后再在生产环境执行升级操作
1、请使用 ./pd-ctl member -u http://10.8.48.204:2379 以及 ./pd-ctl health -u http://10.8.48.204:2379 看下当前 pd 的健康状态是否正常
2、查看下 203 这个节点 pd 的日志,在升级时间点前后是否有报错信息
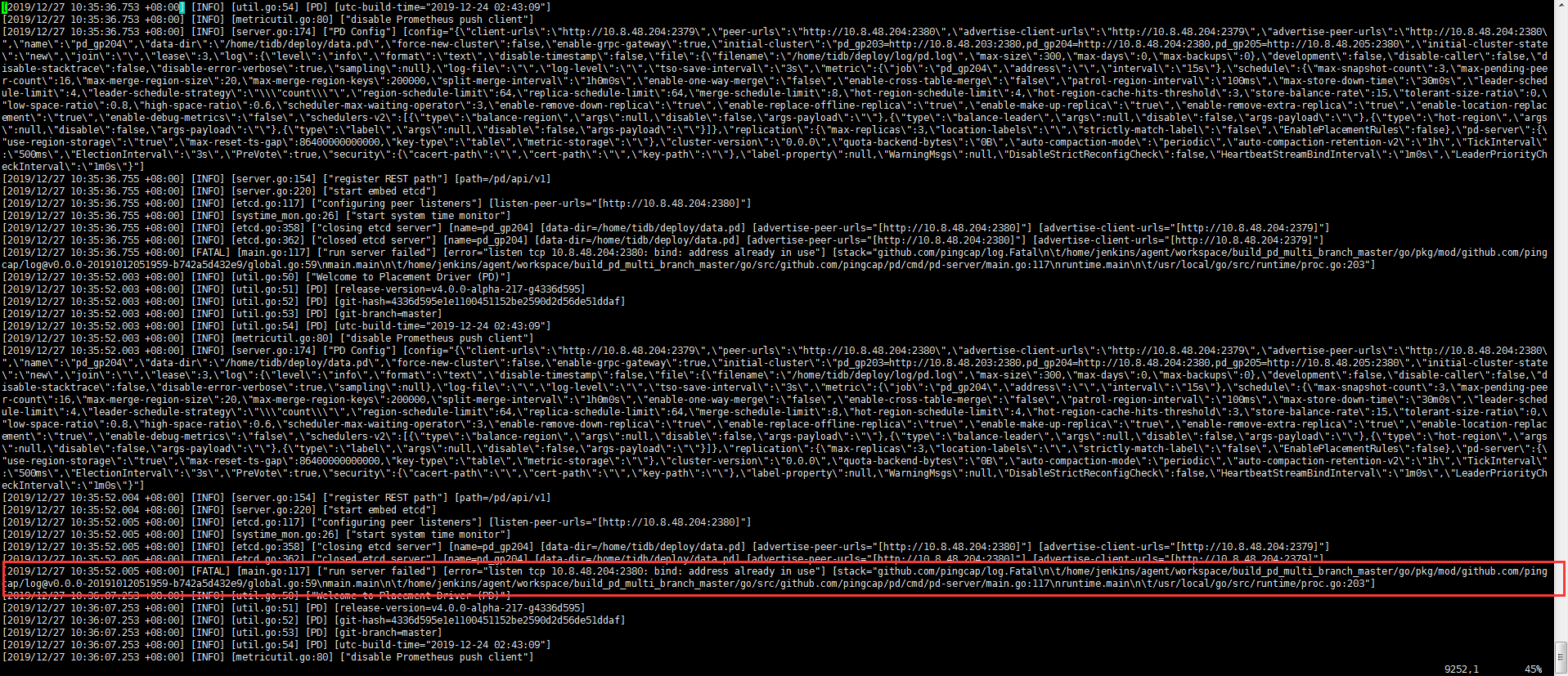
1、请将 203 、204 这两台服务器 pd 节点升级前后的日志文件上传下。
2、检查下各个 pd 服务器 2380 端口的占用情况
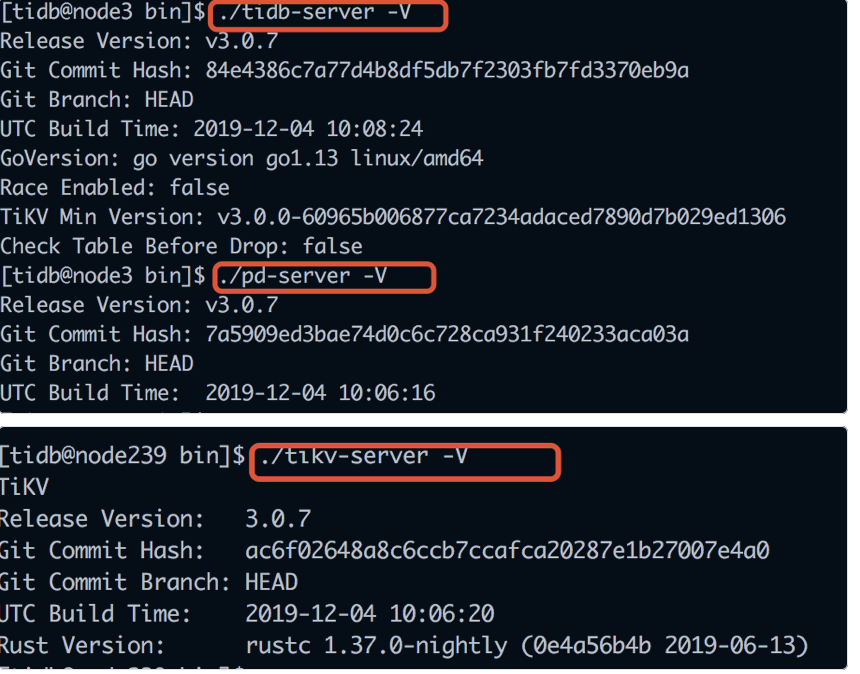
3、检查下 pd 节点,tikv 节点,以及 tidb 节点的版本分别是什么,分别在 tikv、pd、tidb 节点的 bin 目录下执行下述命令:
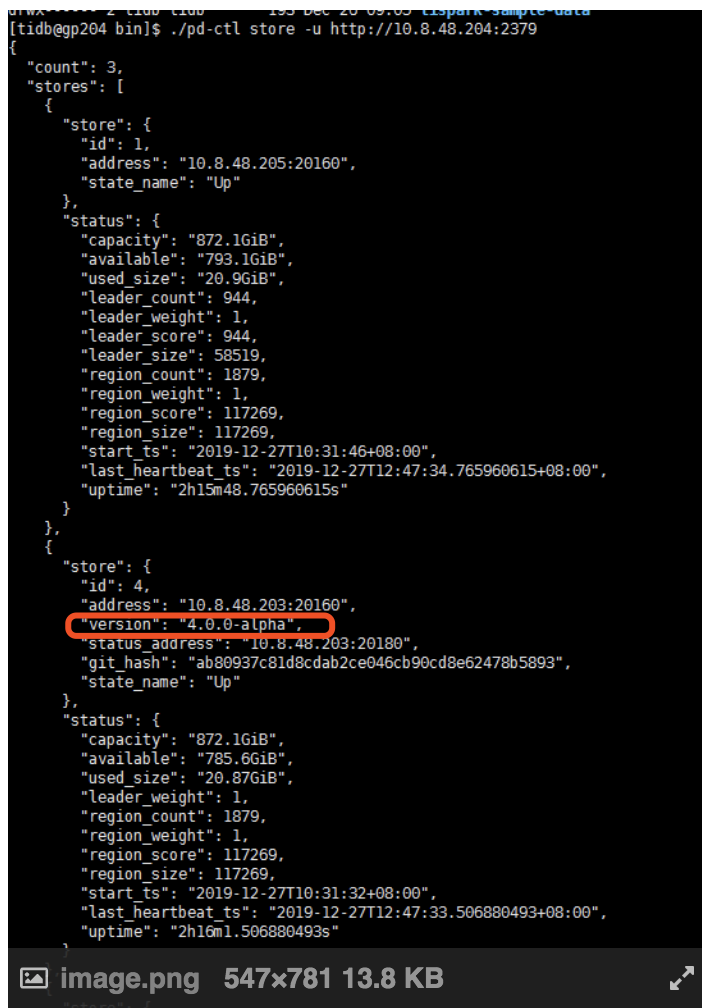
另外,从上面的截图看,store 有些节点已经变为 4.0.0 alpha 版本