为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
-
【TiDB 版本】:V3.0.6
-
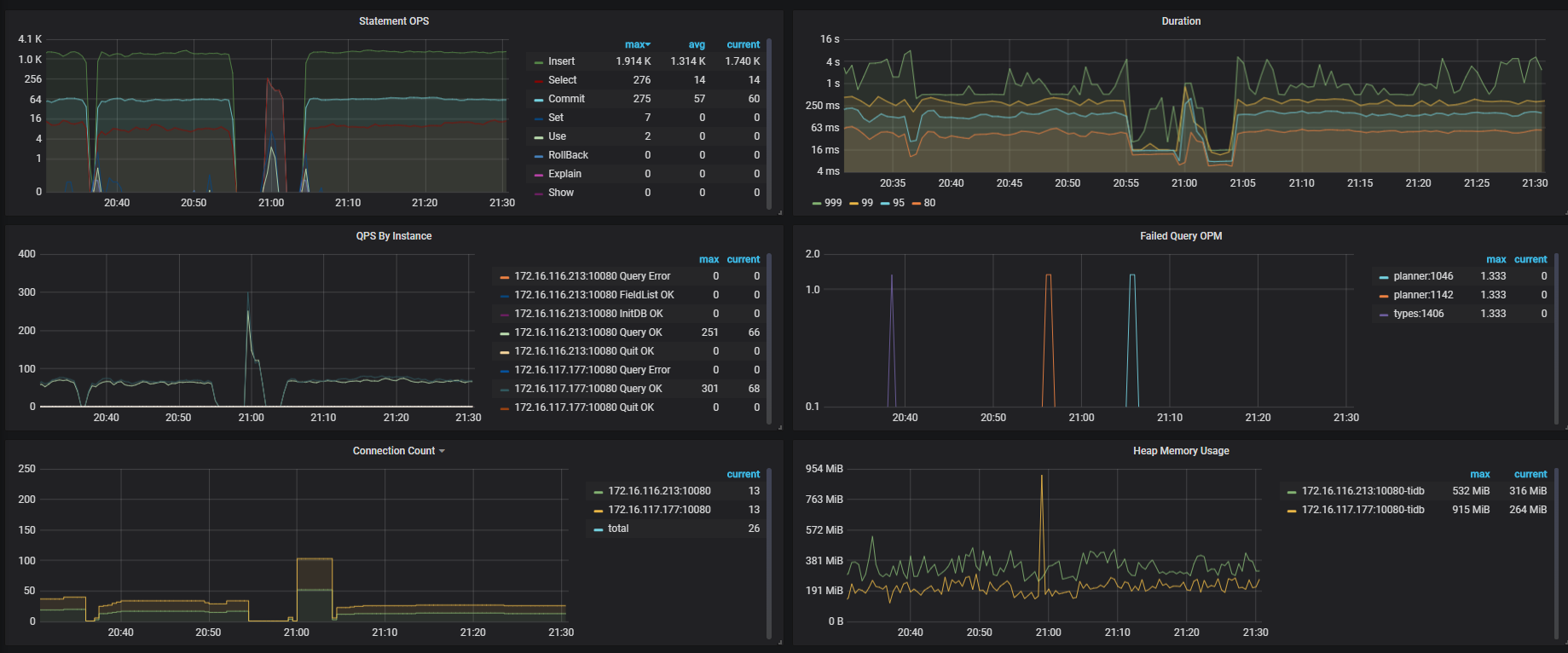
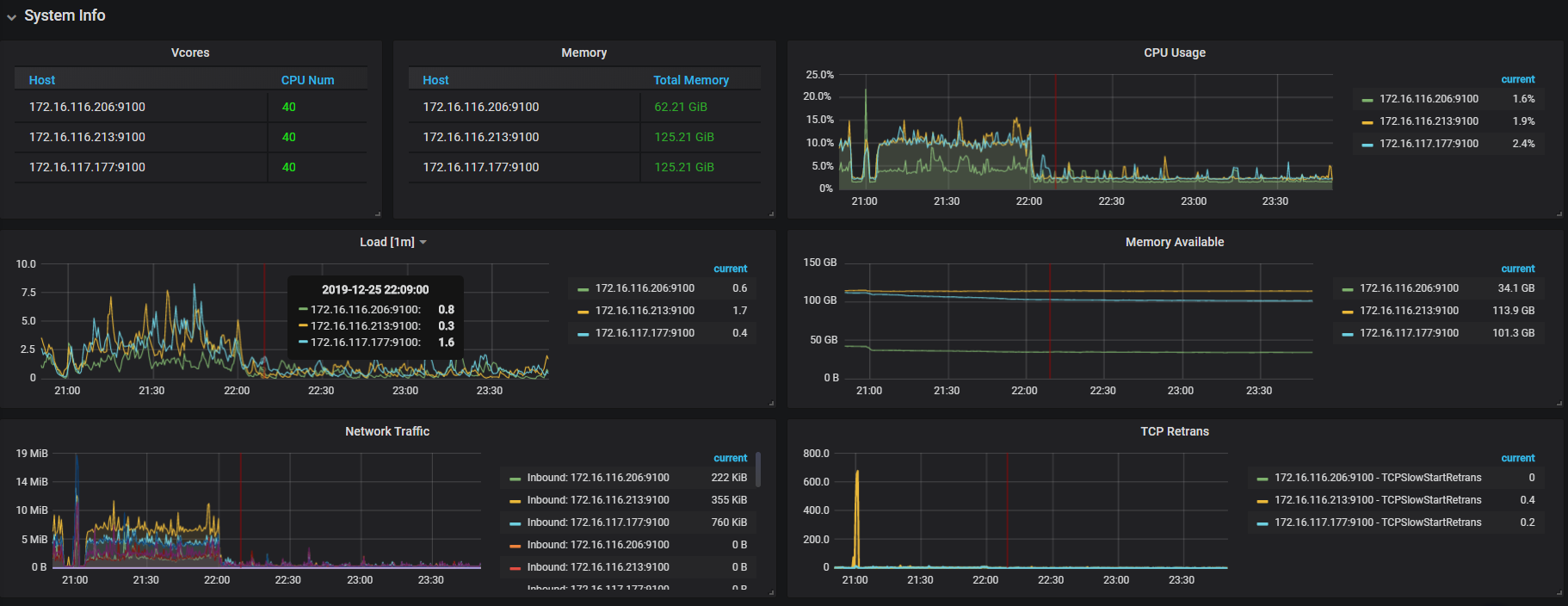
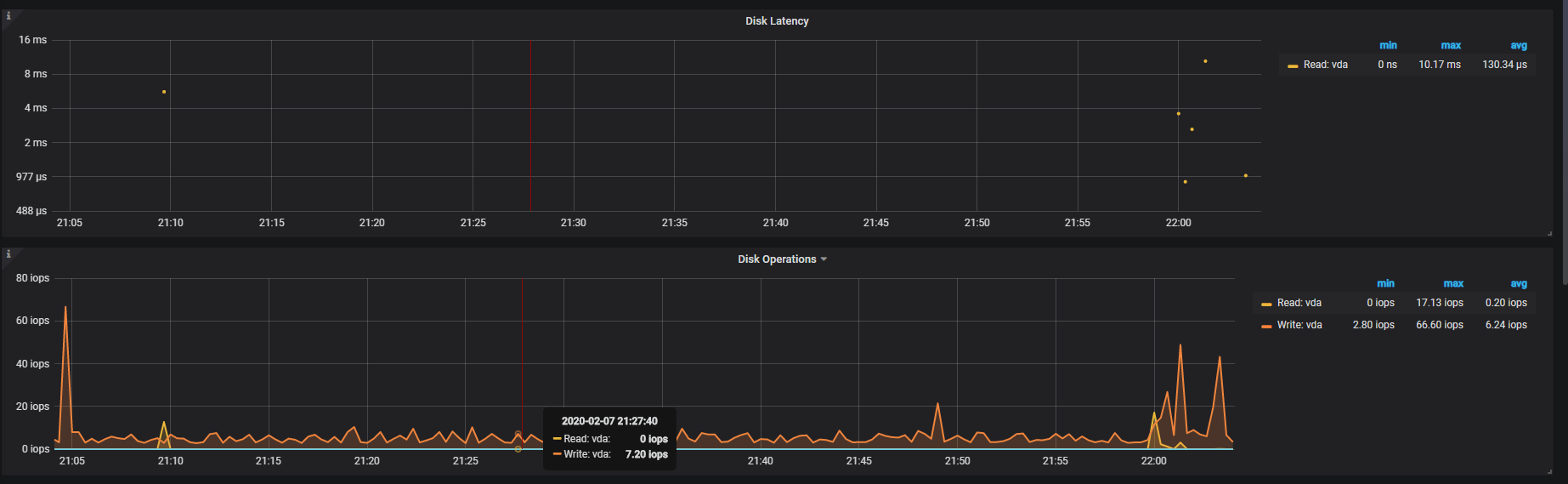
【问题描述】:tidb写入速度越来越慢了,之前upsert能到3000,现在只有2000了。这是info_gathering.py收集的数据
-
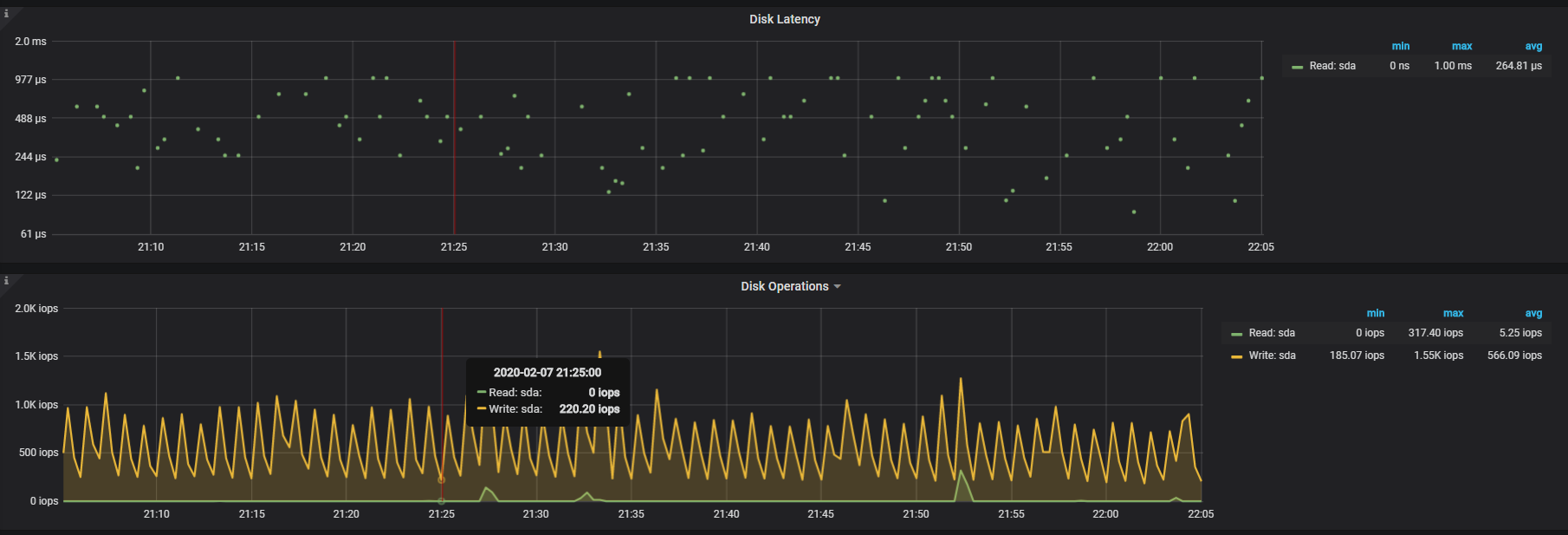
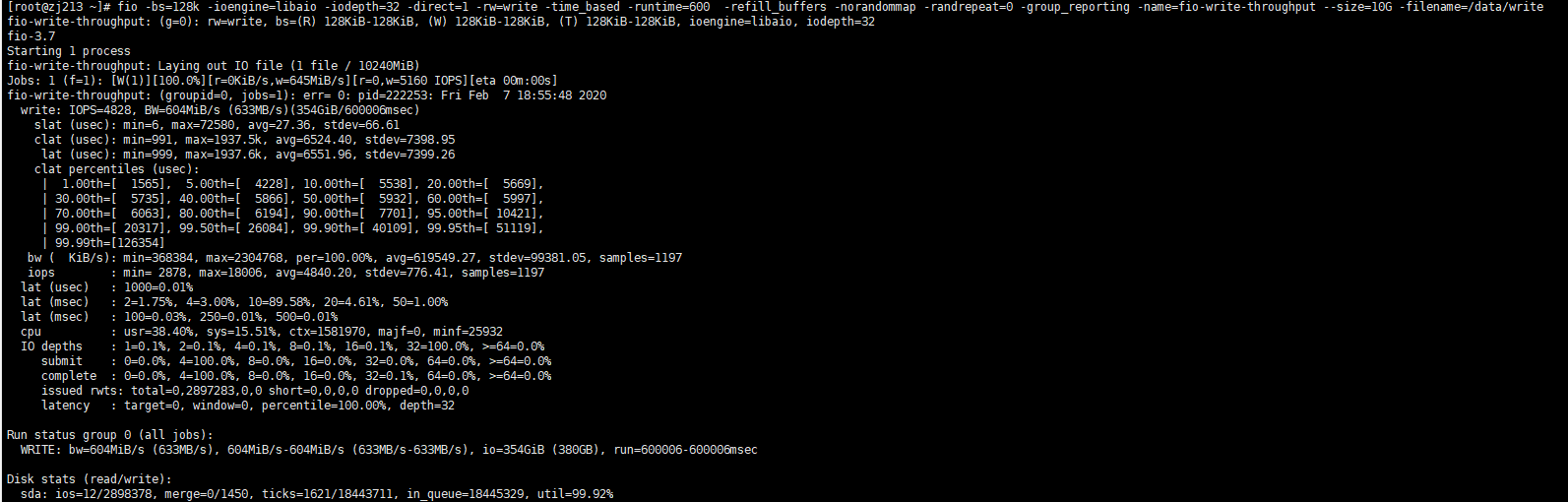
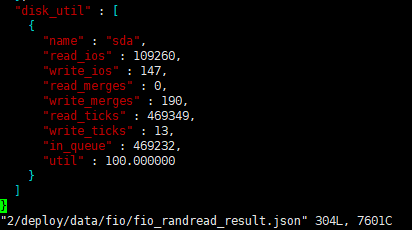
这是其中两个tikv节点的fio信息

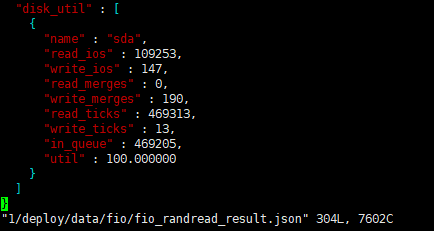
- 这是当前TIDB的监控信息
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:V3.0.6
【问题描述】:tidb写入速度越来越慢了,之前upsert能到3000,现在只有2000了。这是info_gathering.py收集的数据
这是其中两个tikv节点的fio信息
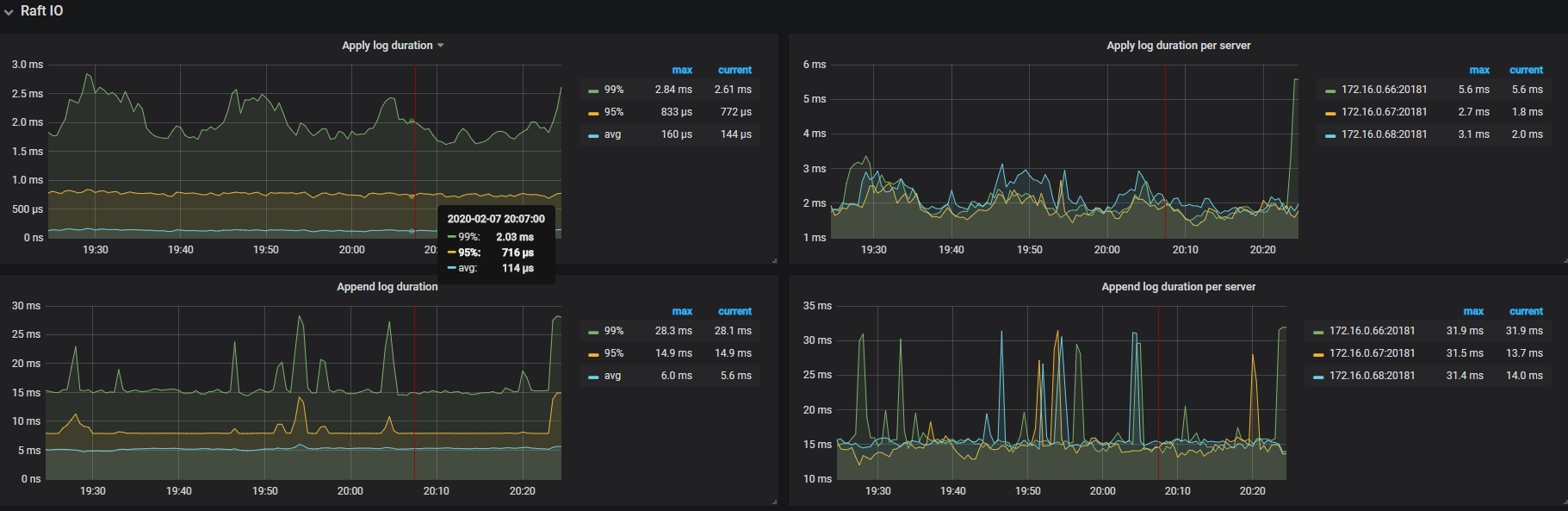
麻烦提供一下以下监控:
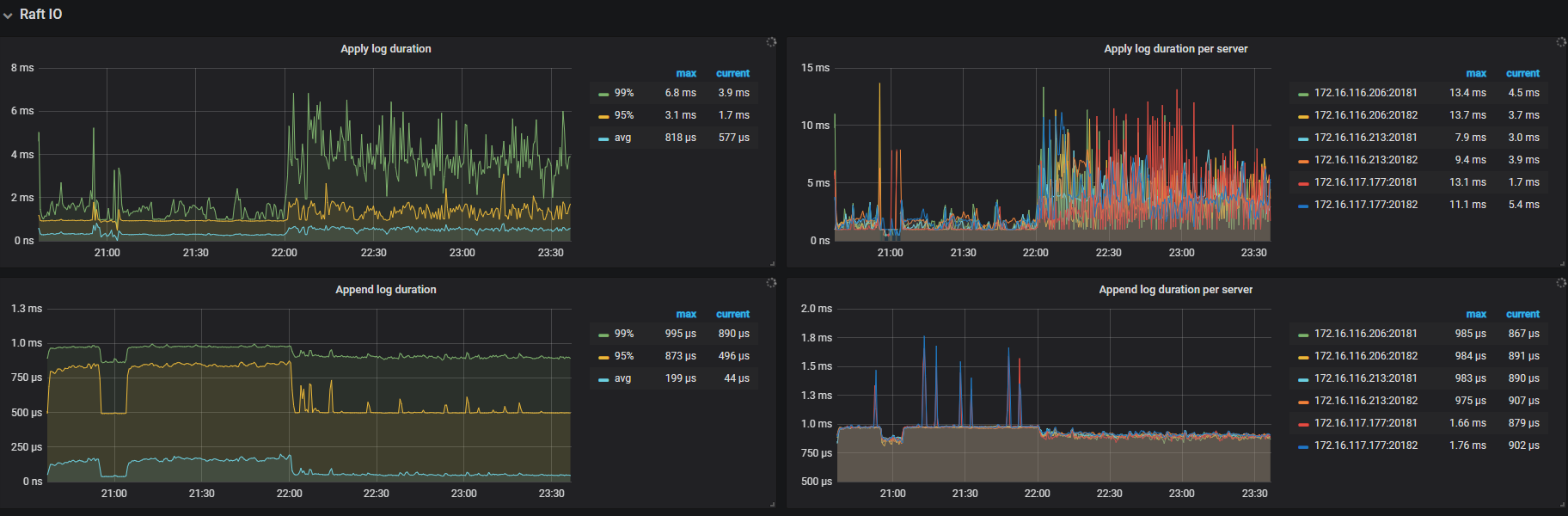
TiKV-Detail -> Raft IO
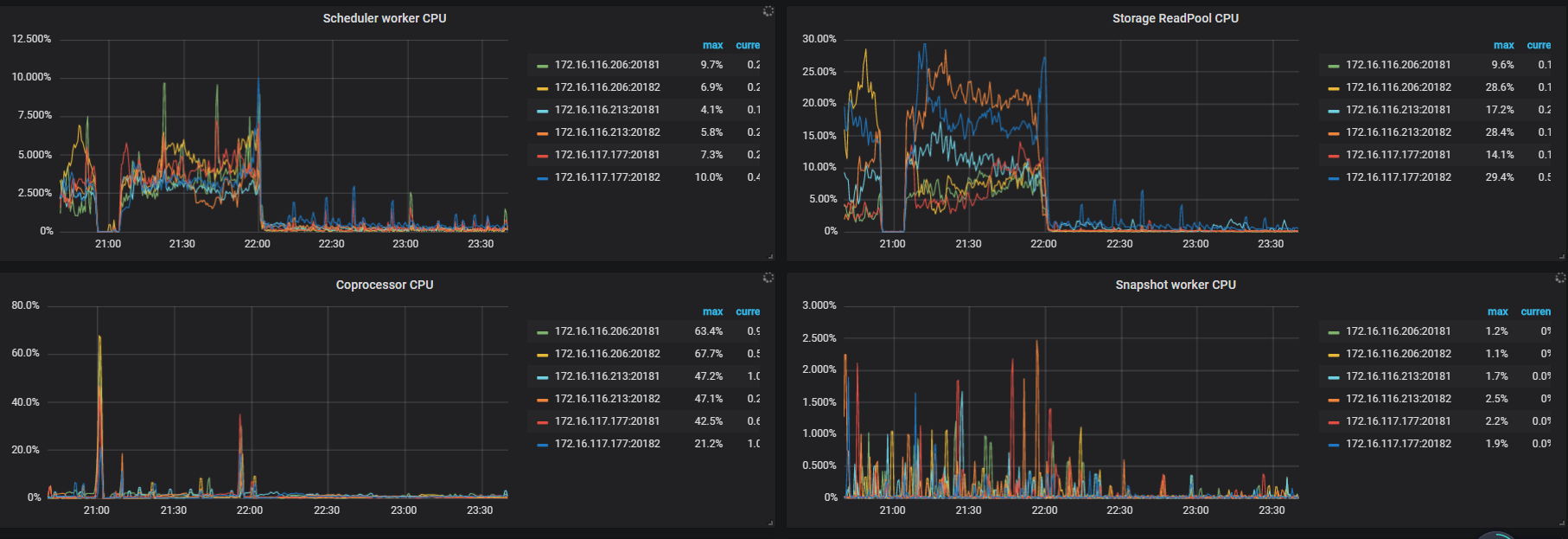
TiKV-Detail -> Thread CPU
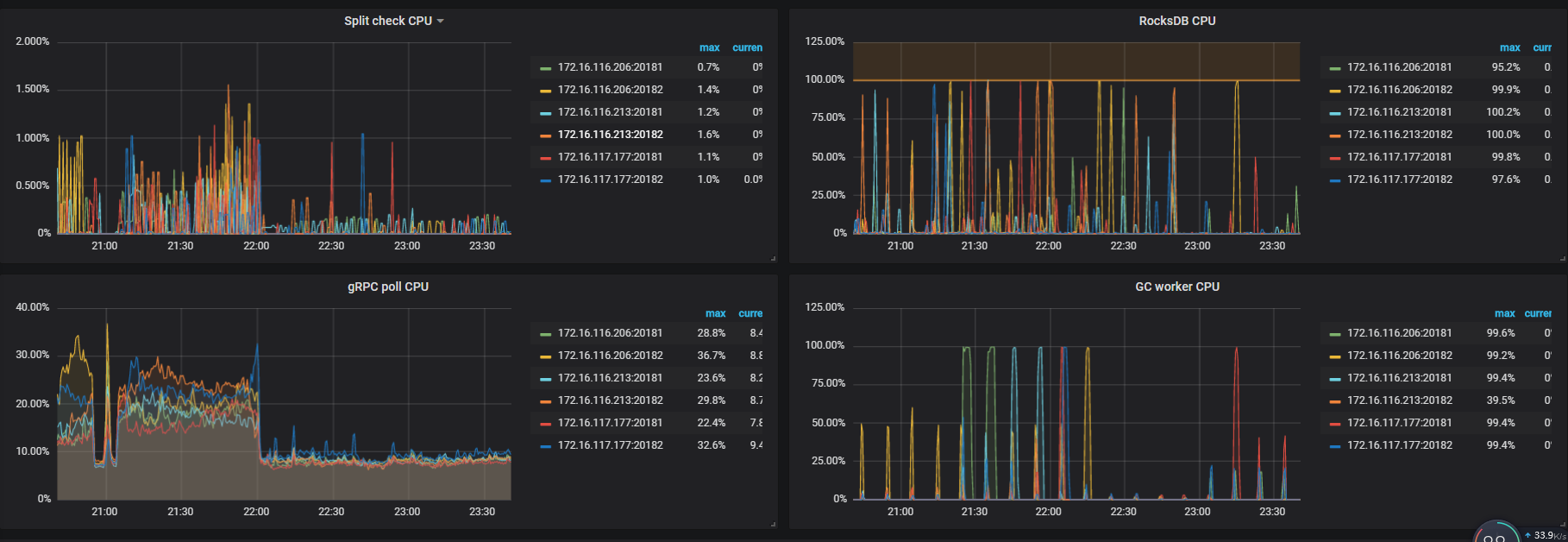
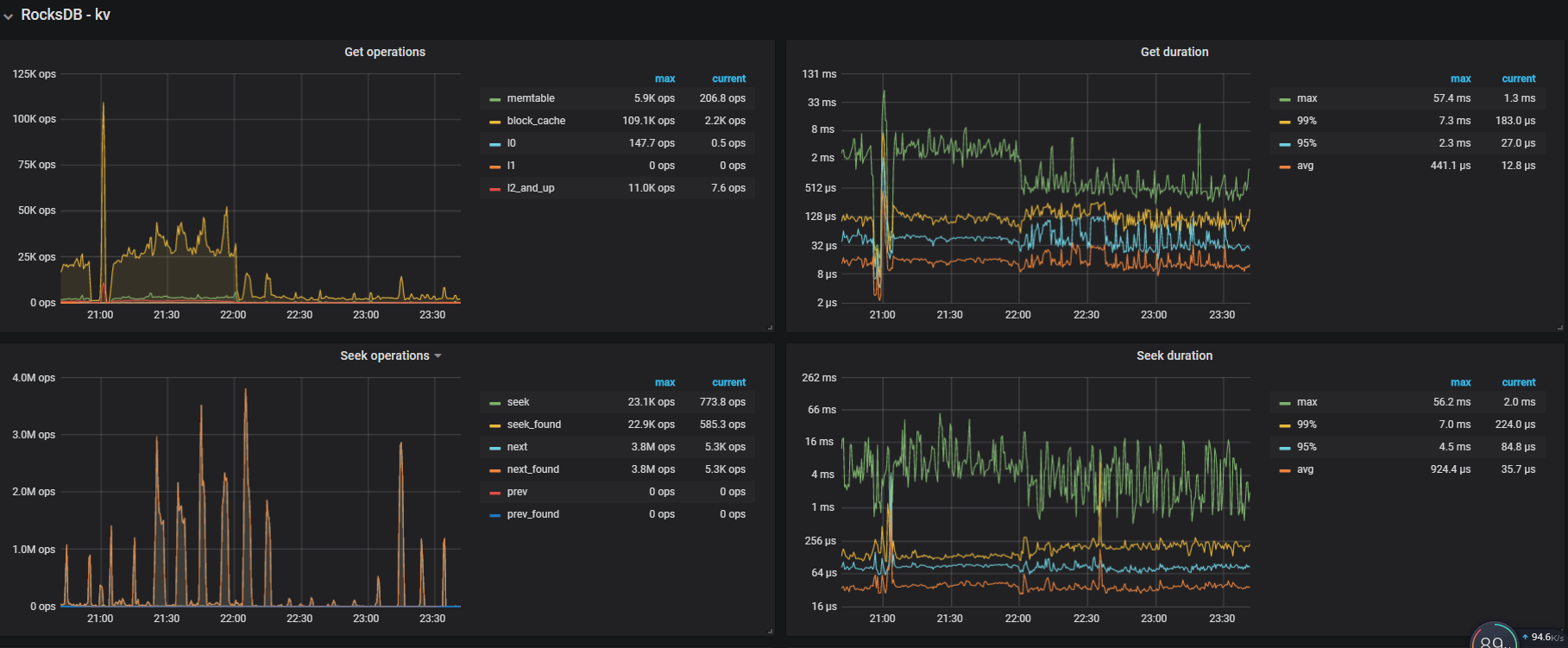
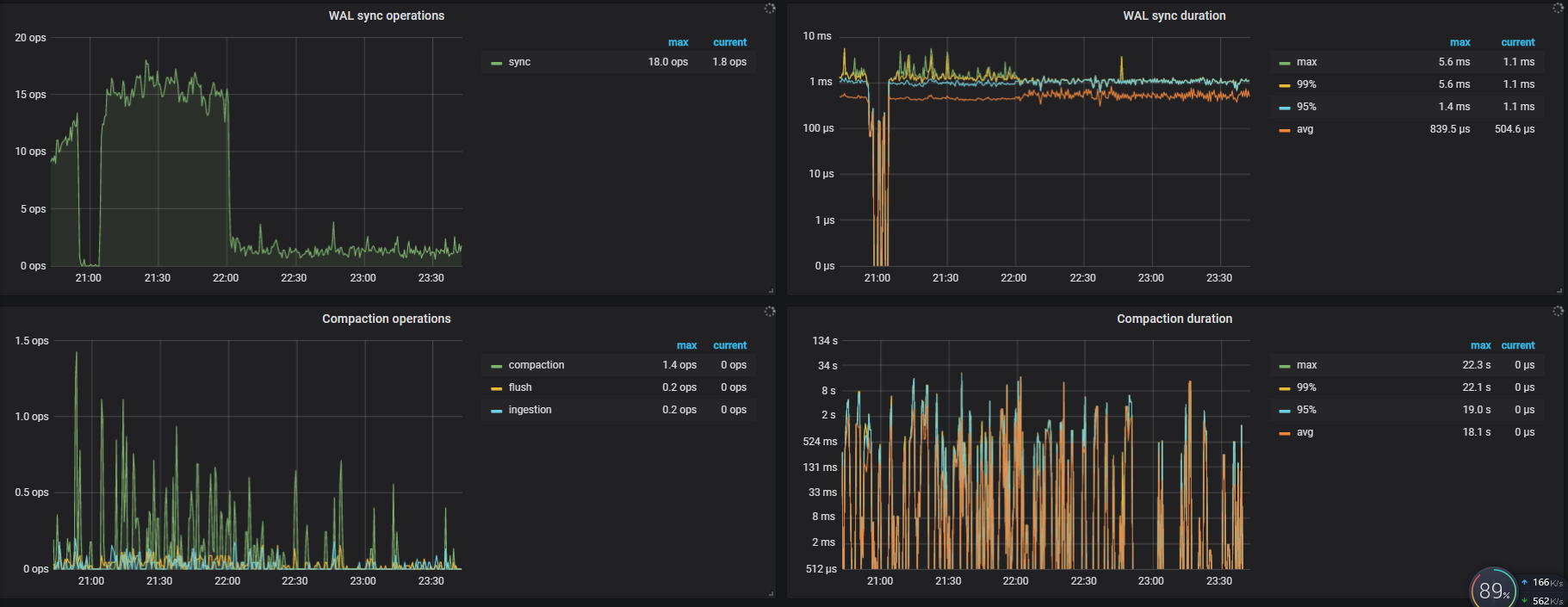
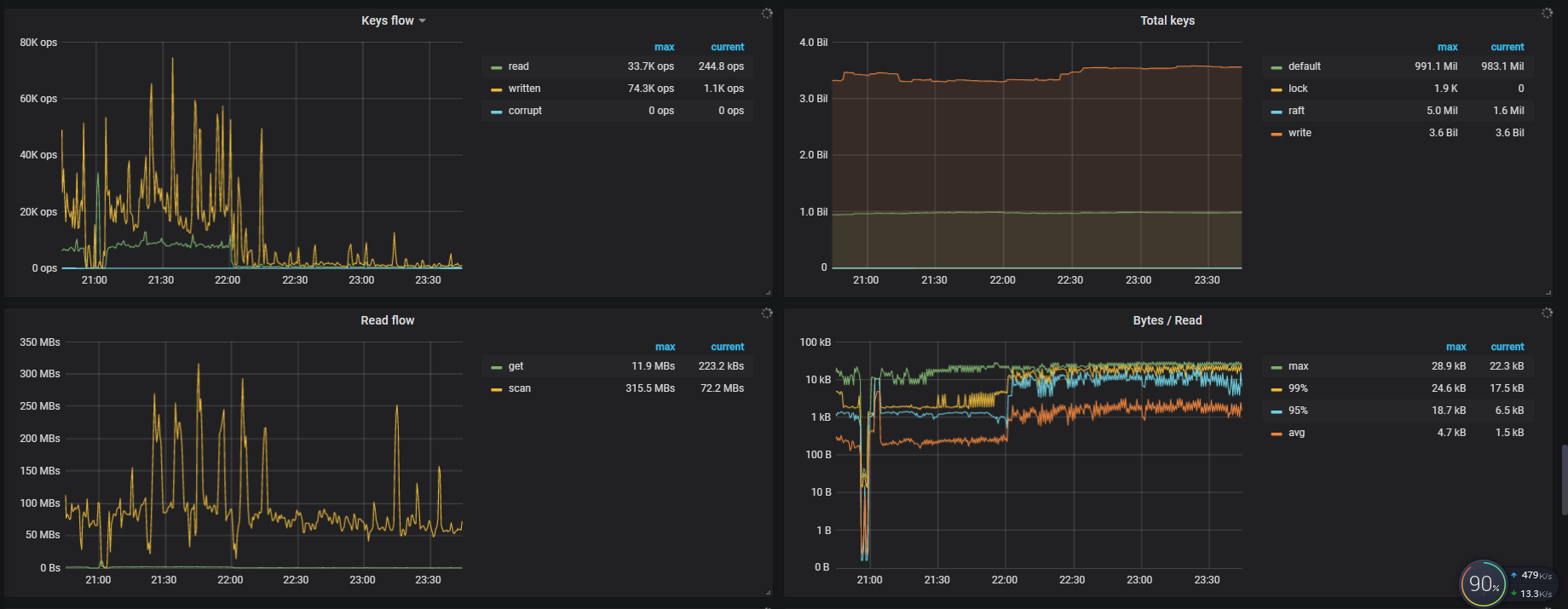
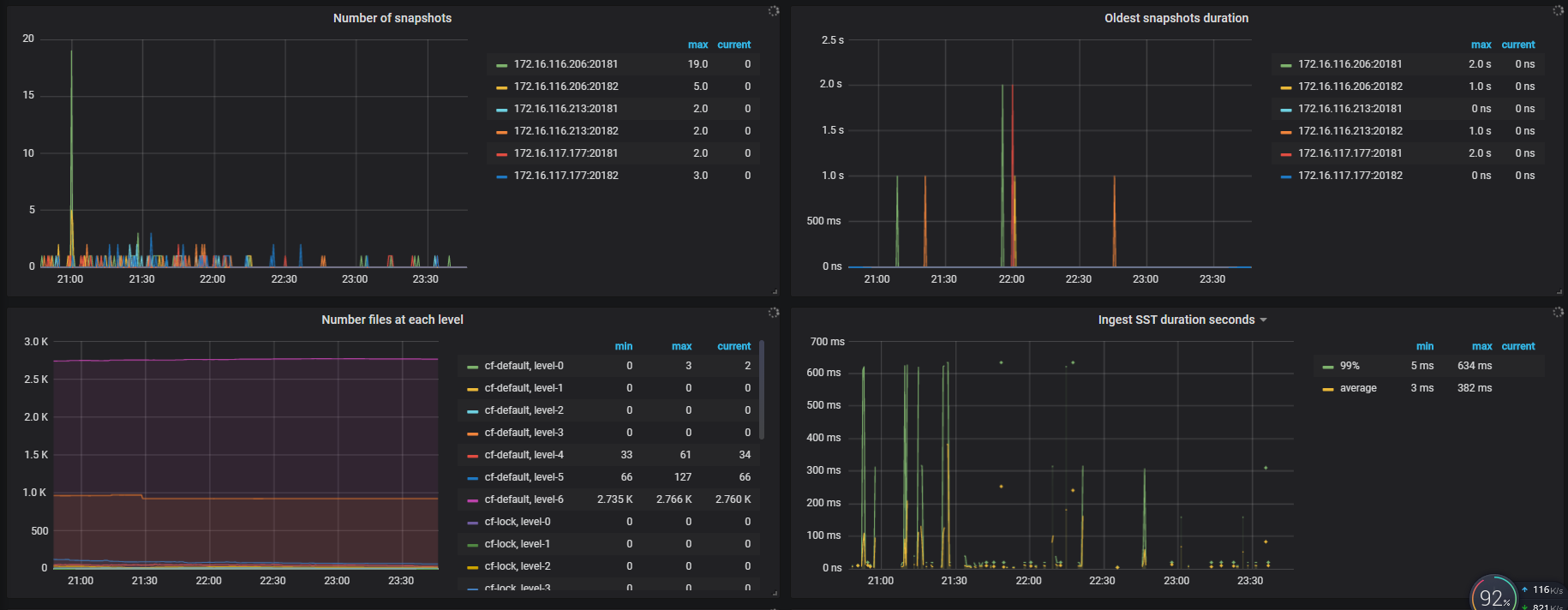
TiKV-Detail -> RocksDB KV
Overview 面板中的监控
从 fio 压测的情况来看,磁盘性能似乎是瓶颈
所以建议:
写入慢只能靠SSD解决了吗?
也可以考虑添加磁盘,扩容 tikv 节点分担节点压力
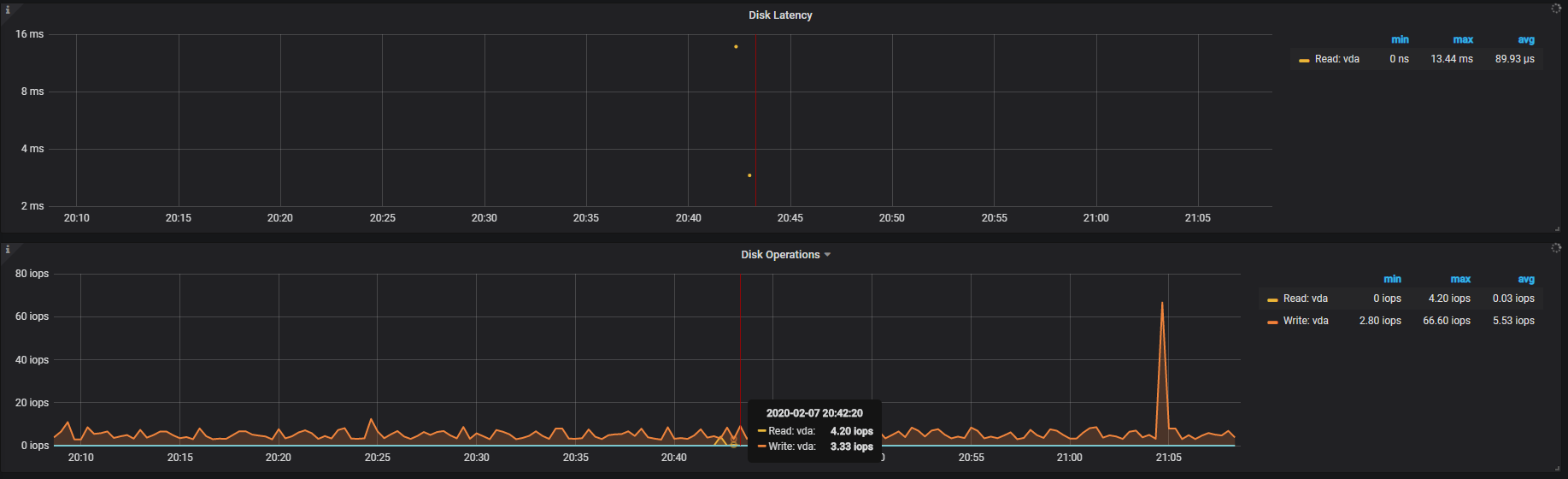
您好,这是我三台腾讯云主机(SSD)的tikv随机读写检测结果,感觉性能很差,有什么好的建议吗?
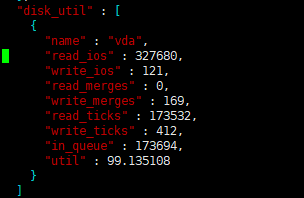
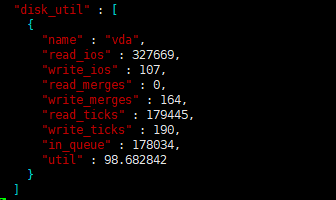

根据腾讯云上现有用户的生产环境部署经验,建议 TiKV 选择本地 SSD 的高 IO 型主机,如 IT3.4XLARGE64(高IO型IT3,16核64GB,单盘 3.7TB)或者 I2.2XLARGE32(高IO型I2,8核32GB,单盘最大 500GB)
好的,谢谢了
append log 表示写 raft log 的耗时,延迟过高通常是由于写盘慢了,可以检查 RocksDB - raft 的 WAL Sync Duration max 值来确认。
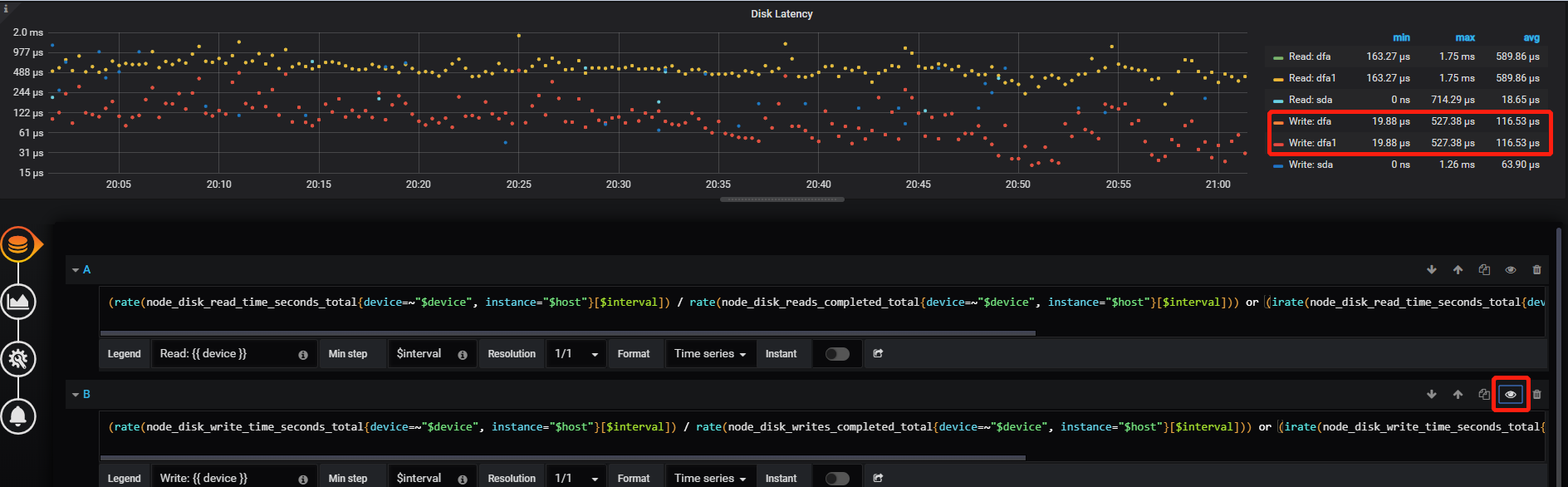
如果 Thread CPU - raftstore cpu(3.0 版本默认线程数为 2 )没有瓶颈(超过 160%)的话,可能是磁盘本身的延迟比较高,可以确认下 disk performance 监控下面写操作的 disk latency 是否过高。
再确认下 disk latency 的延迟,通常应该在几十到几百 μs。
普通 SSD 盘通常是多块磁盘组成的虚拟云盘,在读写延迟上可能比本地普通磁盘要高;对于盘的性能请用 fio 命令进行基准测试,包括 iops 和读写延迟等指标,同样规格的机器由于后端硬件的差异,也可能存在误差,以实测结果为准,如与标称指标不符,可以向云厂商反馈问题;对延迟有要求的业务,TiDB 集群建议部署在本地 nvme 盘。
1、从顺序写的测试结果看,SSD 的 iops、吞吐量要明显高于普通盘,ioutil 100% 负载下,写延迟也明显比普通盘更低,这说明 SSD 能承载更高并发和吞吐量的业务写入;
2、查询性能主要取决于热数据的缓存命中率,如果 block cache 缓存命中率较高,磁盘的性能差异的影响不大;如果缓存命中率不高会从磁盘读更多的数据,需要比较读磁盘的延迟差异。