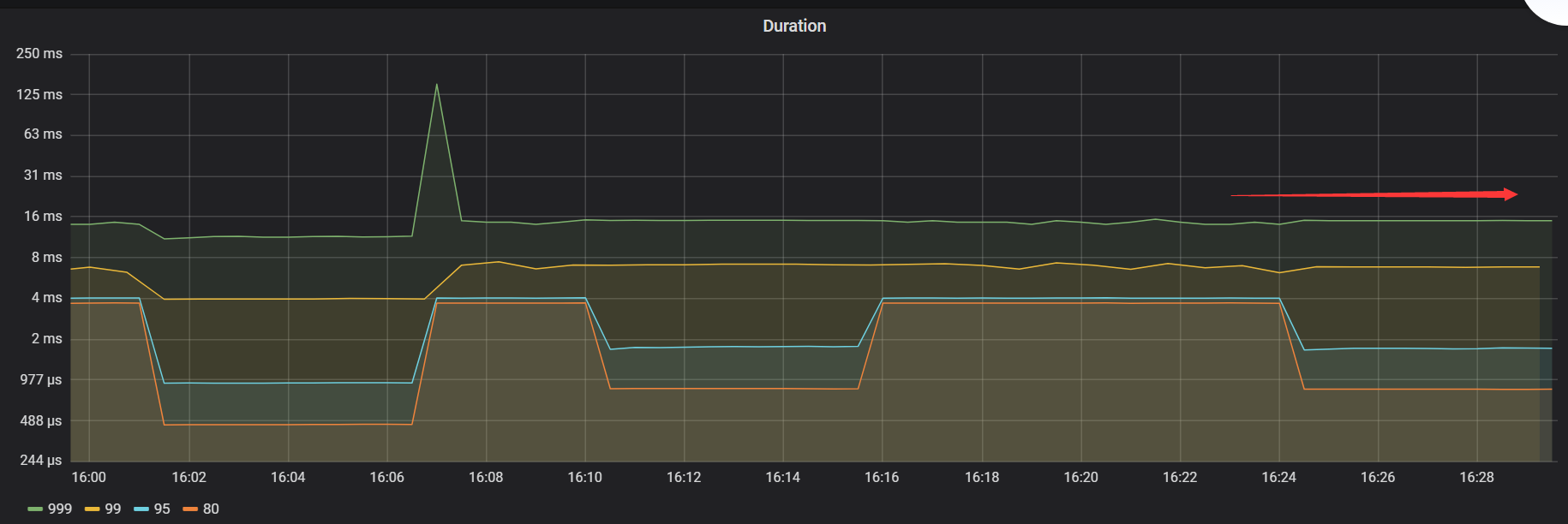
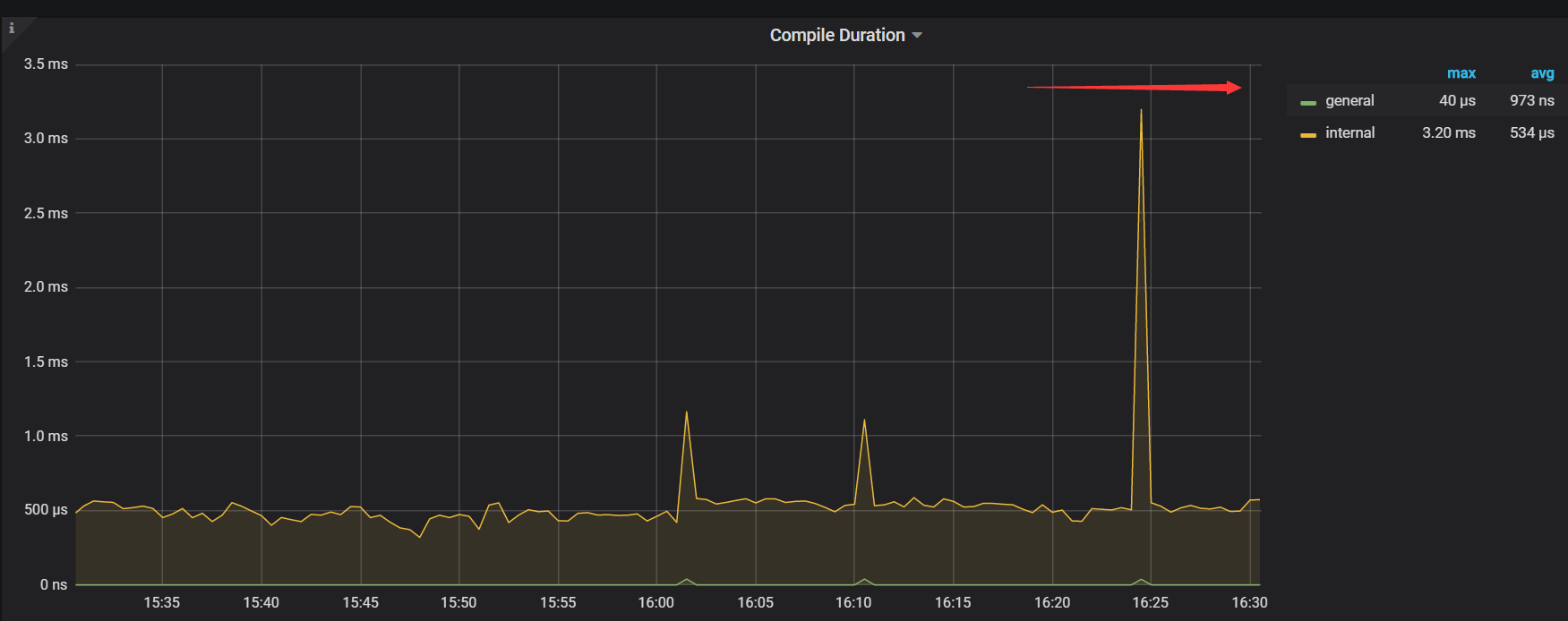
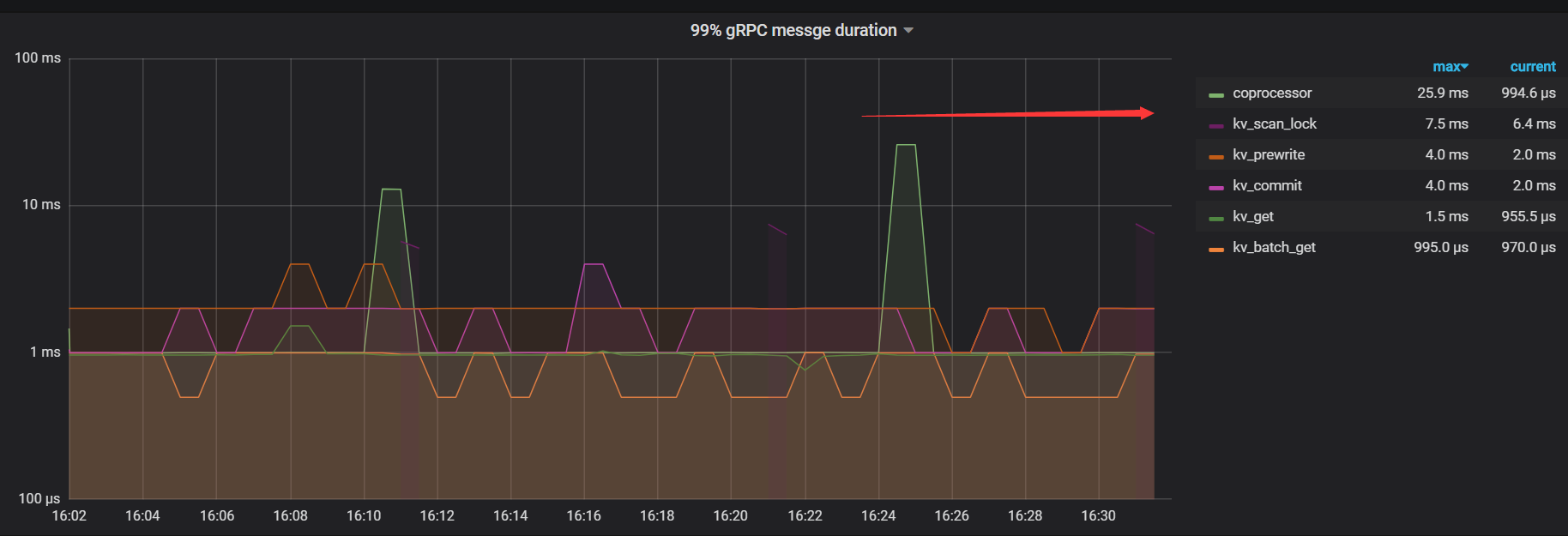
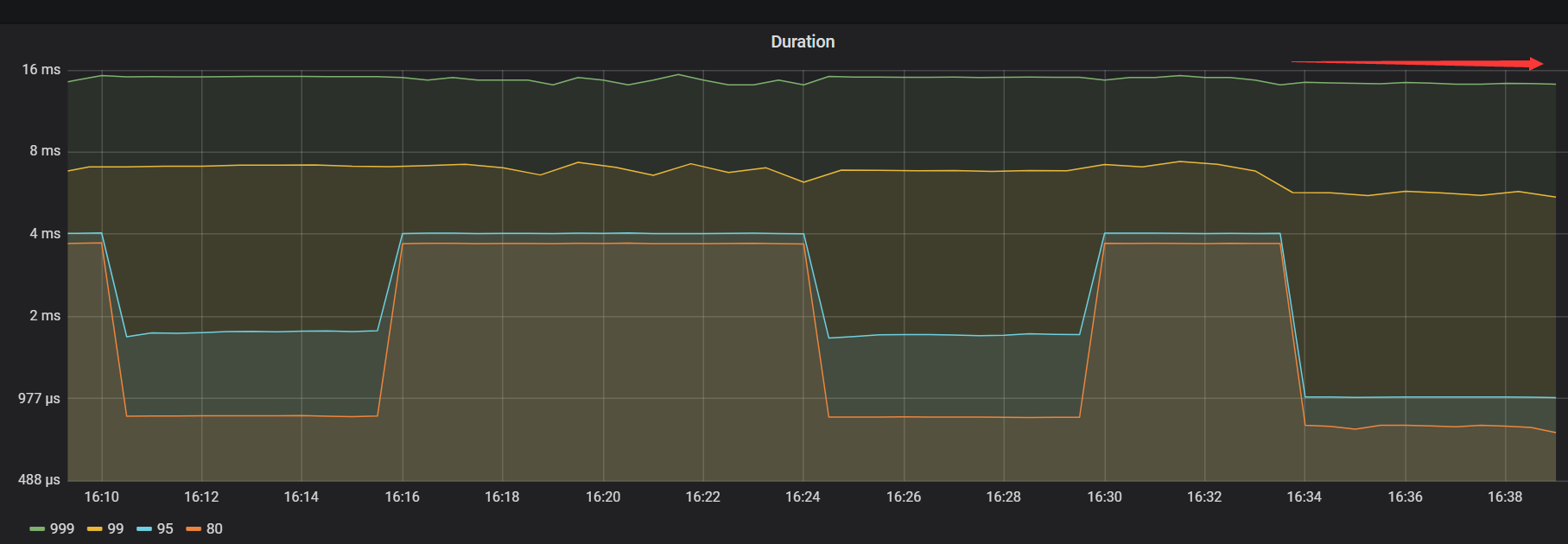
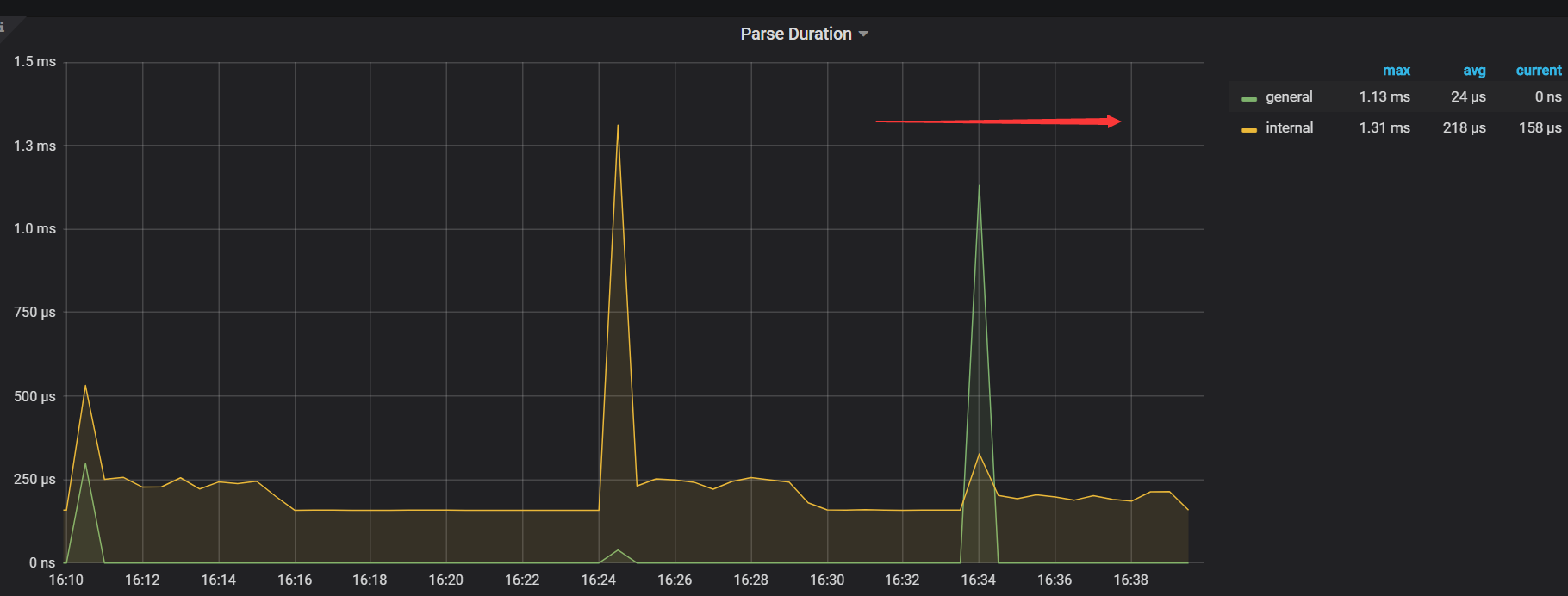
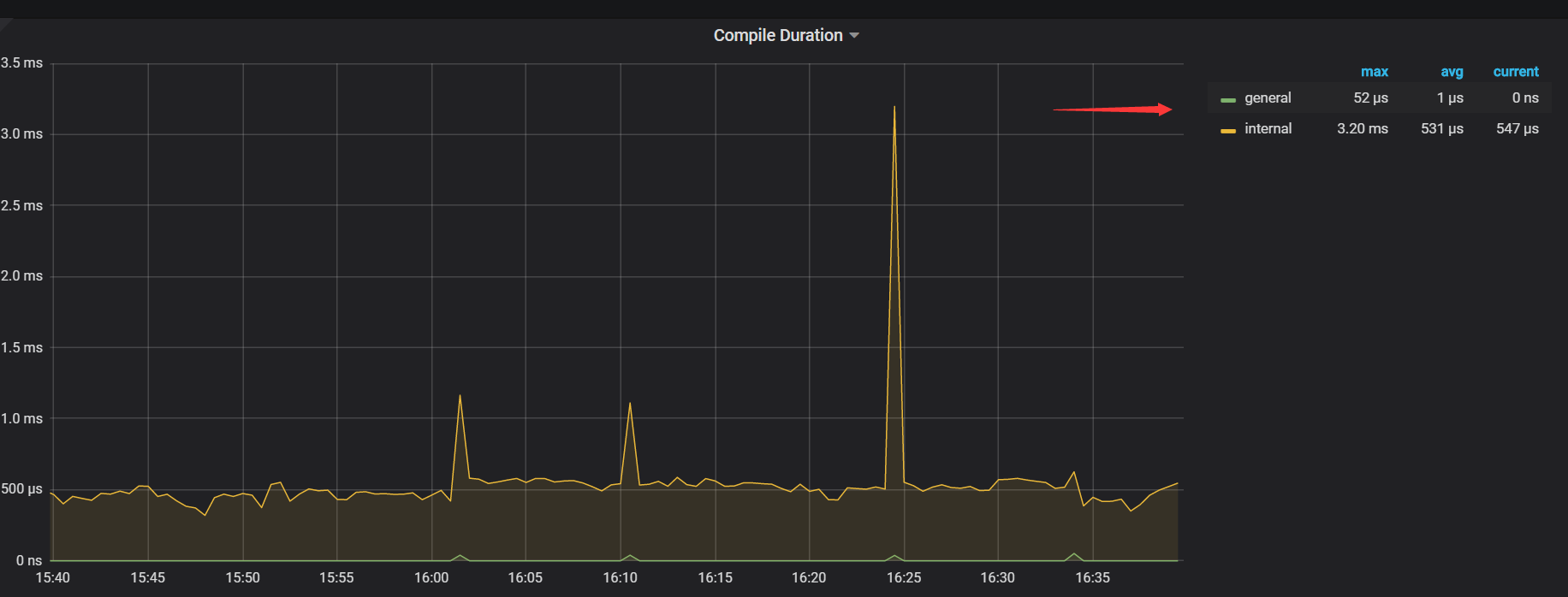
- 【TiDB 版本】:v3.0.5
- 【问题描述】:使用sysbench压测普通ssd和nvme-ssd下tidb的性能表现,结果没有达到预期。
压测环境1
集群拓扑
| 机器 IP | 部署实例 | 硬盘类型 |
|---|---|---|
| 192.168.200.121 | 1*tidb 1*pd | 普通SSD |
| 192.168.200.122 | 1*tidb 1*pd | 普通SSD |
| 192.168.200.123 | 1*tidb 1*pd | 普通SSD |
| 192.168.200.87 | 1*tikv | 普通SSD |
| 192.168.200.88 | 1*tikv | 普通SSD |
| 192.168.200.89 | 2*tikv | 普通SSD |
| 192.168.200.90 | 2*tikv | 普通SSD |
压测环境2
集群拓扑
| 机器 IP | 部署实例 | 硬盘类型 |
|---|---|---|
| 192.168.100.1 | 1*tidb 1*pd | 普通SSD |
| 192.168.100.2 | 1*tidb 1*pd | 普通SSD |
| 192.168.100.3 | 1*tidb 1*pd | 普通SSD |
| 192.168.100.4 | 3*tikv | NVME-SSD |
| 192.168.100.5 | 3*tikv | NVME-SSD |
| 192.168.100.6 | 3*tikv | NVME-SSD |
| 192.168.100.7 | 3*tikv | NVME-SSD |
测试方案
使用 Sysbench 向集群导入 16 张表,每张数据 100万 。起 3 个 sysbench 分别向 3 个 TiDB 发压,请求并发数逐步增加,单次测试时间 5 分钟。
压测集群1和2使用tidb版本和配置文件完全相同。
相关配置参数如下:
| 参数名 | 配置文件 | 默认值 | 更改值 |
|---|---|---|---|
| oom-action | conf/tidb.yml | log | cancel |
| apply-pool-size | conf/tikv.yml | 2 | 4 |
| store-pool-size | conf/tikv.yml | 2 | 4 |
| high-concurrency | conf/tikv.yml | 8 | 6 |
| normal-concurrency | conf/tikv.yml | 8 | 6 |
| low-concurrency | conf/tikv.yml | 8 | 6 |
压测结果
- oltp_update_index
| 集群1/普通ssd | Th | TPS | QPS | avg.latency(ms) | 95.latency(ms) | max.latency(ms) |
|---|---|---|---|---|---|---|
| oltp_update_index | 16 | 1504.23 | 1504.23 | 10.63 | 34.95 | 1307.99 |
| oltp_update_index | 32 | 3234.50 | 3234.50 | 9.89 | 36.24 | 5593.29 |
| oltp_update_index | 64 | 5341.42 | 5341.42 | 11.98 | 41.85 | 7173.03 |
| oltp_update_index | 128 | 7015.08 | 7015.08 | 18.24 | 95.81 | 8879.73 |
| 集群2/nvme-ssd | Th | TPS | QPS | avg.latency(ms) | 95.latency(ms) | max.latency(ms) |
|---|---|---|---|---|---|---|
| oltp_update_index | 16 | 2901.37 | 2901.37 | 5.51 | 6.55 | 5412.96 |
| oltp_update_index | 32 | 6963.94 | 6963.94 | 4.59 | 7.04 | 5226.1 |
| oltp_update_index | 64 | 15294.37 | 15294.37 | 4.18 | 9.06 | 5734.01 |
| oltp_update_index | 128 | 23273.00 | 23273.00 | 5.42 | 12.98 | 5784.94 |
- oltp_read_only
| 集群1/普通ssd | Thread | TPS | QPS | avg.latency(ms) | 95.latency(ms) | max.latency(ms) |
|---|---|---|---|---|---|---|
| oltp_read_only | 16 | 458.93 | 7342.85 | 34.85 | 57.87 | 927.79 |
| oltp_read_only | 32 | 1091.66 | 17466.51 | 29.31 | 51.94 | 835.90 |
| oltp_read_only | 64 | 1951.38 | 31222.07 | 32.79 | 55.82 | 813.86 |
| oltp_read_only | 128 | 2766.83 | 44269.25 | 46.25 | 73.13 | 811.33 |
| 集群2/nvme-ssd | Thread | TPS | QPS | avg.latency(ms) | 95.latency(ms) | max.latency(ms) |
|---|---|---|---|---|---|---|
| oltp_read_only | 16 | 381.96 | 6111.38 | 41.88 | 51.94 | 293.21 |
| oltp_read_only | 32 | 987.16 | 15794.56 | 32.41 | 50.11 | 263.07 |
| oltp_read_only | 64 | 2107.97 | 33727.51 | 30.35 | 38.94 | 163.70 |
- oltp_point_select
| 集群1/普通ssd | Thread | TPS | QPS | avg.latency(ms) | 95.latency(ms) | max.latency(ms) |
|---|---|---|---|---|---|---|
| point_select | 16 | 16271.09 | 16271.09 | 0.98 | 1.27 | 789.89 |
| point_select | 32 | 31336.17 | 31336.17 | 1.02 | 1.55 | 813.70 |
| point_select | 64 | 61653.91 | 61653.91 | 1.04 | 1.86 | 332.33 |
| point_select | 128 | 94153.67 | 94153.67 | 1.36 | 2.91 | 249.50 |
| 集群2/nvme-ssd | Thread | TPS | QPS | avg.latency(ms) | 95.latency(ms) | max.latency(ms) |
|---|---|---|---|---|---|---|
| point_select | 16 | 8955.51 | 8955.51 | 1.79 | 2.03 | 294.20 |
| point_select | 32 | 20544.23 | 20544.23 | 1.56 | 2.11 | 206.22 |
| point_select | 64 | 43274.29 | 43274.29 | 1.48 | 2.07 | 41.62 |
| point_select | 128 | 100254.56 | 100254.56 | 1.28 | 2.14 | 47.70 |
- 压测CPU
结果:压测集群1和2的cpu性能无明显区别
- 压测nvme-ssd
nvme-ssd的读写性能较普通sdd有明显提升,但是提升了4倍。
总结
从压测结果来看:
1)单独压测硬盘性能,nvme-ssd有了加大的性能提升
2)压测tidb集群,使用nvme-ssd硬盘的集群在读性能表现来看居然没有使用普通sdd的性能好。
不知道是不是使用上有什么问题,或者还需要做什么优化才能提升tidb的性能?