为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:DM版本1.0.3
- 【问题描述】:
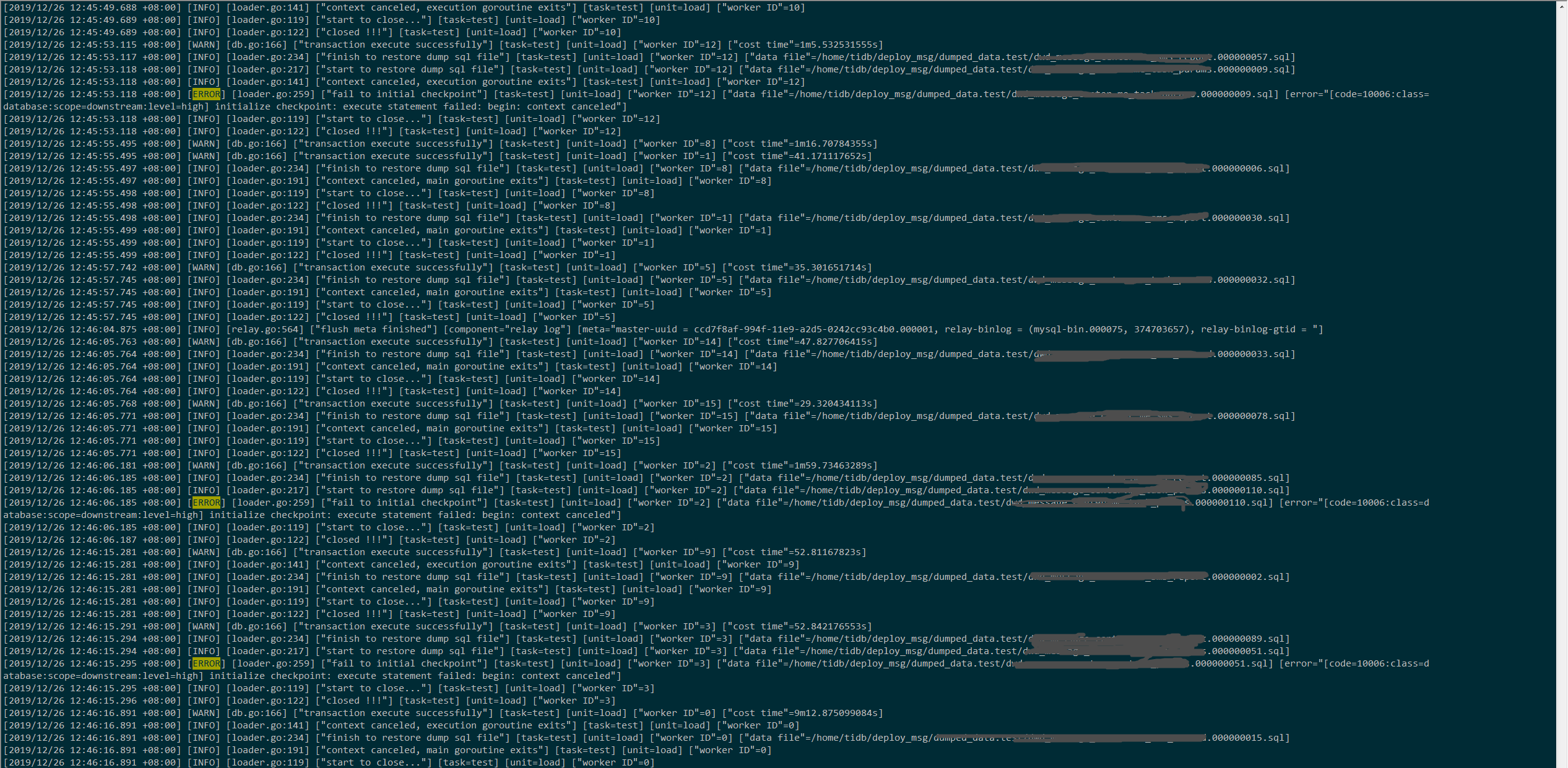
我现在在load状态,升级了1.0.3之后就老是有这个问题。这就两天发现一直会出现这样的执行sql语句失败。
像这样的问题,我直接resume-task就可以直接恢复
但是它老是这样,我不能每一次都手动去resume-task 恢复一下吧。能不能帮我看一下
实际上没有主键冲突呀,如果有主键冲突的话,resume-task 为什么能直接恢复呢
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
1.先解释一下 resume-task 直接恢复的情况。
查看了下全日志中 Duplicate entry ‘8aaaf2fd684c4bf101684f21b93642c3’ for key ‘PRIMARY’,出现大概有 4 次,推测每次同步主键冲突都是有该值造成的。
2.到下游数据库中查看下该值,8aaaf2fd684c4bf101684f21b93642c3,然后在 dump 中的文件中 grep 一下,查看是否只有一条记录或者多条记录,如果是包含多条记录,可能是上游数据存在冲突的情况。如果是一条记录。可以先按照以下步骤收集下信息,然后再将该行从下游删除(避免再次读到该文件继续报主键冲突)
dump 里面这么多sql文件,这怎么找。能不能教教我
cat dump 文件,然后 grep 一下冲突的值。
这样该怎么找
写个简单的 shell 循环判断下
我能不能简单粗暴点,直接把下游所有表都删掉,然后清掉meta,中的load和sync,删掉worker中部署生成的文件夹怎么样。删掉下游建的库和表。下线worker之后重新部署重新同步。能靠谱吗?
这个问题已经两天了,在解决不了我就要费了。
在配置文件里把 remove-meta: false 改成 true,重启 task 任务试下。
哪个配置文件里面,我怎么没有找到这个配置呢
重复的原因最好还是确认一下,dump文件中如果有两个重复的值,那么就算删除了重新导入,下次还是会有冲突,所以根据这个报错的主键,先在所有dump出的.sql文件中grep一下,看是不是只有一条记录。
好,我知道了。但是任务我已经停掉了,正在重新dump中,看看这次还会不会是这样。
我知道怎么回事了,是因为在中途过程中因为磁盘IO读写巨量增大导致TiDBdown掉了,我重启了一下TiDB节点。所以导致在load的过程中执行失败了,然后我恢复了一下task任务,load的时候 变成了之前的两倍,所以才会一直主键冲突。
变成了之前的两倍,所以才会一直主键冲突。
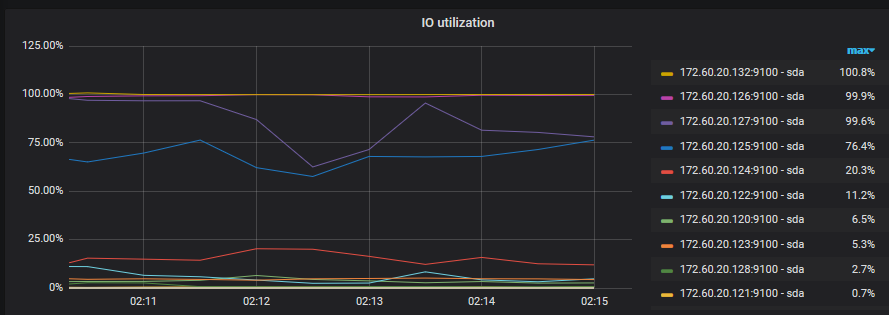
我还有一个问题求解答,就是我在load的时候往表中写数据,load的特别慢,两个小时才load进去了15%。磁盘IO占用直接飙升到
从监控看132,126,127这几个的IO都达到了接近100%,磁盘非常繁忙. 总共导入多大数据量的数据? tikv多少节点? 导入的数据是否有自增id,或者时间的索引列?
您好:
如果表上都有自增id主键,建议在导入ddl信息之后,可以提前划分reigon,参考split region信息
https://pingcap.com/docs-cn/stable/reference/sql/statements/split-region/#split-region-使用文档
我这里也遇到同样的问题,关键是mysql的所有表都是有自增主键的,同步中除主键冲突错误,还有大量的表已存在错误,这个问题比较头疼,load数据经常中断
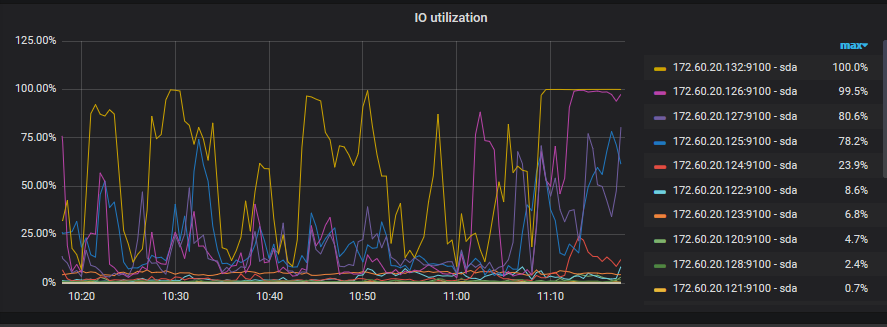
除此之外我这里还有这样的错误,如下图:
没有具体错误,然后同步任务也中断了,resume-task就又可以同步了,不知道是什么原因
resume-task可以重新同步是因为,loader的时候随机扫的.sql文件,但是当扫描到重复的地方还是会中断。 所以你需要从源头上把重复的数据处理了