请问这怎么处理呢

…监控在上面呢,所以呢,现在能确定是哪里的问题吗
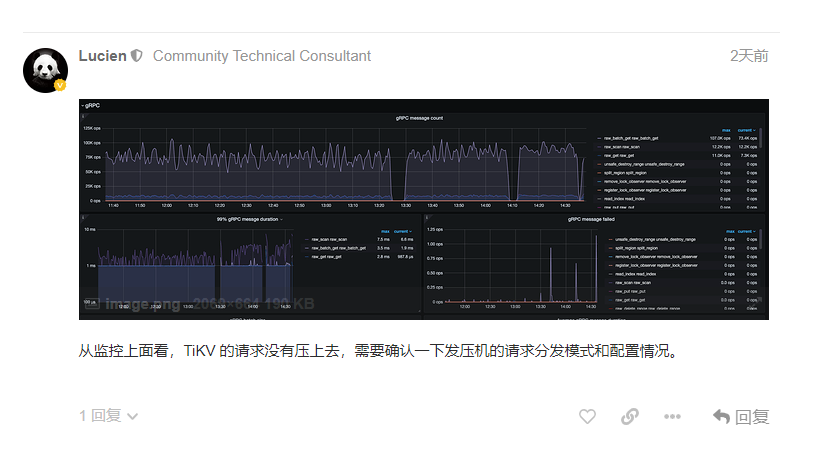
看了下 TiKV 集群有 7 个实例,请问这 7 个 TiKV 实例配置是否一样。他们分别可用多少 CPU,以及他们的 grpc-concurrency, readpool.storage.low-concurrency 配置是什么。
另外也看下 PD leader 进程在测试时 CPU 使用情况

Flink 那边的 TM 进程的 CPU 情况给拿下吧,看下 top -H -p

这是每个tm开100slot时候的cpu使用量,现在有个奇怪的问题是,如果集群里只部署一个tm,这个tm的cpu使用量明显提高,平均不低于30,然后grafana命令最高也能达到下面的情况

这跟网络带宽有关系吗
用这个 top -H 的命令来看,主要是想知道有没有某个类似于 dispatcher 的线程成为瓶颈了
另外你提到的网络的确也有可能是一个瓶颈点,可以观察下客户端机器上的出口带宽和机器的网卡能力的比值
这个是正在跑的,单个tm的flink集群,开的是100slot
这是监控的带宽,前7个就是tikv所在的服务器
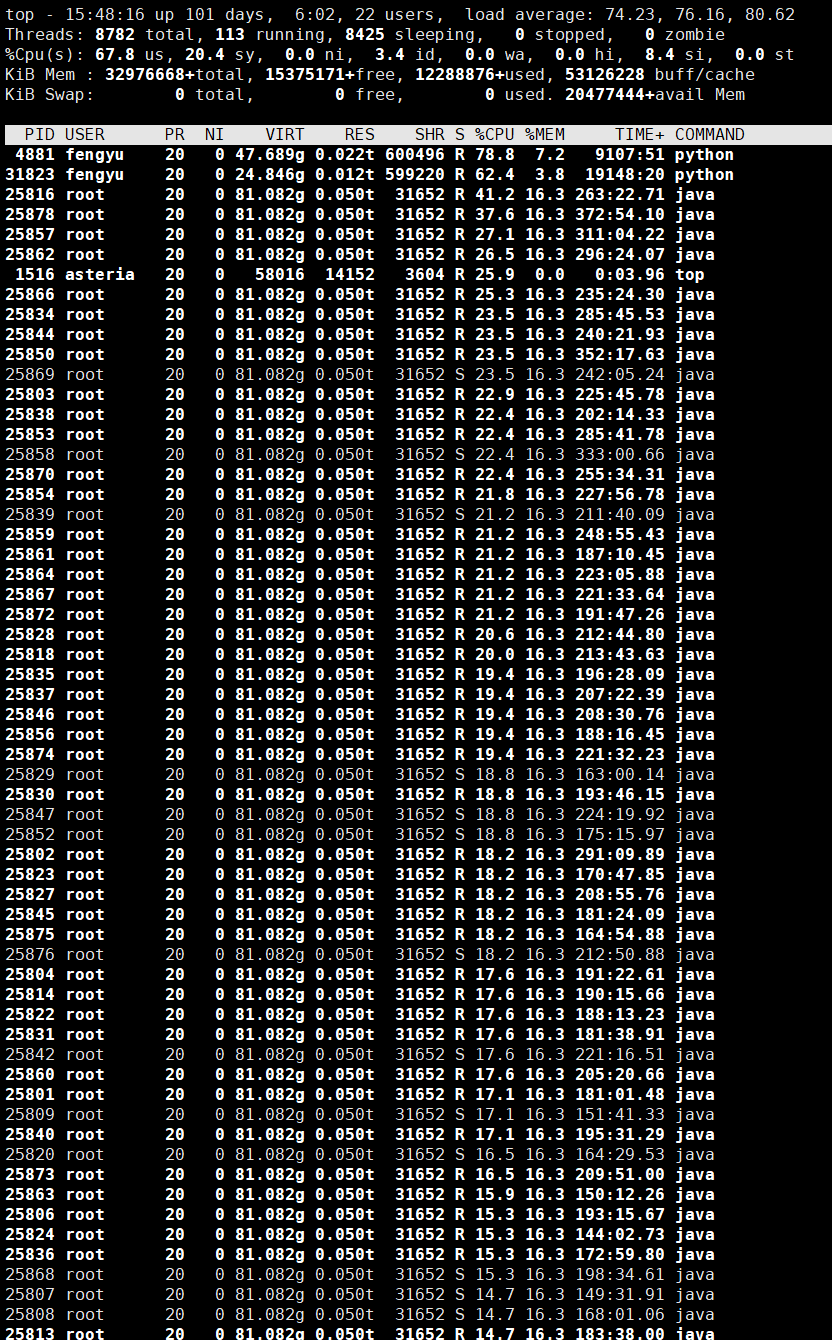
这是监控的带宽,前7个就是tikv所在的服务器

还有一个问题是我现在在用iperf测试服务器之间的网络带宽,请问是应该测tcp还是udp的,tikv-java-client和服务端之间用的是tcp还是udp啊
看上面的线程图如果持续是这样没有某个线程接近 100% 的话那应该不是分发线程瓶颈。
网络角度看的话 TiKV 用的是 TCP 连接,可以拿 iperf 看下 TM 这个机器的入流量是什么情况
现在是测试了tikv(204),flink(125)
这是204做客户端,125做服务端的情况

这是反过来125做服务端,204做客户端的情况
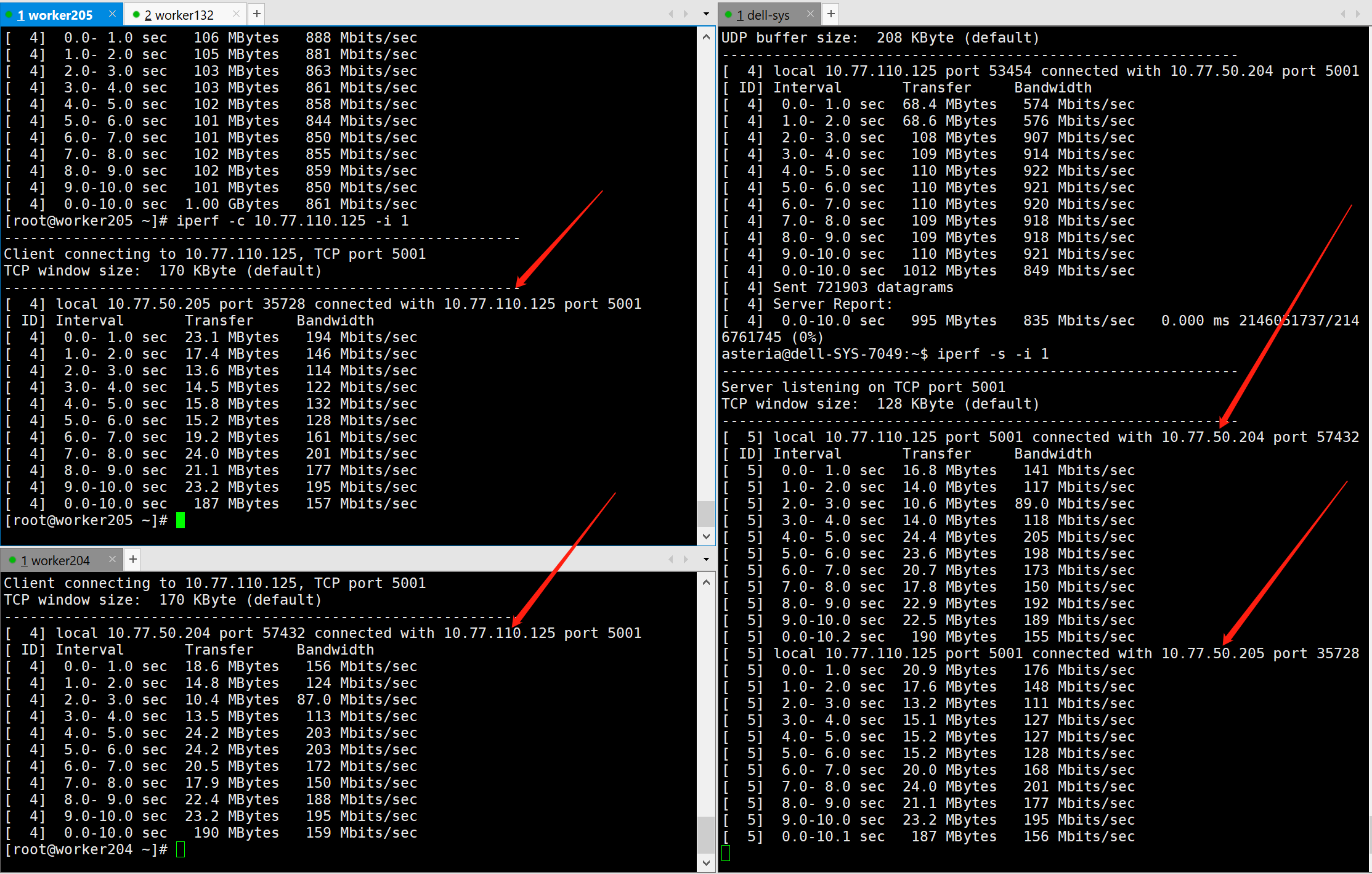
和上面实时流量监控来看,应该瓶颈在网络上,那么我想请问,现在是得提高哪个方向的网速呢
这个有点奇怪,正常来说双向是一样的带宽。问一下你们团队的基础设施团队看看这个网络有没有什么问题?
是这样,有个问题是,我现在部署都是在k8s上面部署的tikv节点和flink节点,那我用iftop命令监控实时网络的时候,是检测哪个网卡呢,对外访问服务器Ip的那个网卡吗
现在这个问题是因为这个吗
监控进程的流量用分配给具体容器的那个应该就行
1 个赞
我可能找到问题了
我想问一下,请问tikv-java-client和tikv-server之间的tcp传输,是建立一个tcp连接tikv-java-client(客户端)<->tikv-server(服务端)传输数据,还是建立两个tcp连接tikv-java-client(客户端)->tikv-server(服务端)和tikv-java-client(服务端)<-tikv-server(客户端)传输数据的?
TCP 连接本身是双向的,一个连接可以在两个方向上发送数据。在目前的通讯模型下,数据读取是由客户端发起由服务端返回的。
另外问下最后定位到是什么问题呢?
应该还是网络的问题,是不是不应该在tikv节点所在的机器上部署flink集群,这样会占用网络带宽是吗?
Flink 读的数据不只会在自己的机器上,也可能会跨机器读取。如果网络带宽不够成为瓶颈,就会影响到系统的吞吐。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。