广泽苍山
2021 年11 月 4 日 05:40
1
【 TiDB 使用环境】
【背景】:
【现象】:
【问题】:
不确定这个是否为Tidb的设计缺陷导致,如果life_time过短不满足safe_point,analyze failed这个判断完全可以前置判断,为什么会产生大量的资源占用?
根据FAQ,调大tidb_gc_life_time 可以解决问题。但是有一点不明白的是,在新版本的说明里面:“如果一个事务的运行时长超过了 tidb_gc_life_time 配置的值,在 GC 时,为了使这个事务可以继续正常运行,系统会保留从这个事务开始时间 start_ts 以来的数据。例如,如果 tidb_gc_life_time 的值配置为 10 分钟,且在一次 GC 时,集群正在运行的事务中最早开始的那个事务已经运行了 15 分钟,那么本次 GC 将保留最近 15 分钟的数”。既然Tidb会为最长的事务保留数据,但为什么还会报这个错误?
对于Tidb server的源码进行浏览也确定了Tidb server的safe point的计算会是以当前集群中执行事务的最小的start_ts为准作为safe point的基准值,那为什么又会产生上面的报错???
【业务影响】:
1 个赞
广泽苍山
2021 年11 月 4 日 05:55
2
补充一下说明我的疑问吧:
1 个赞
广泽苍山
2021 年11 月 8 日 05:43
6
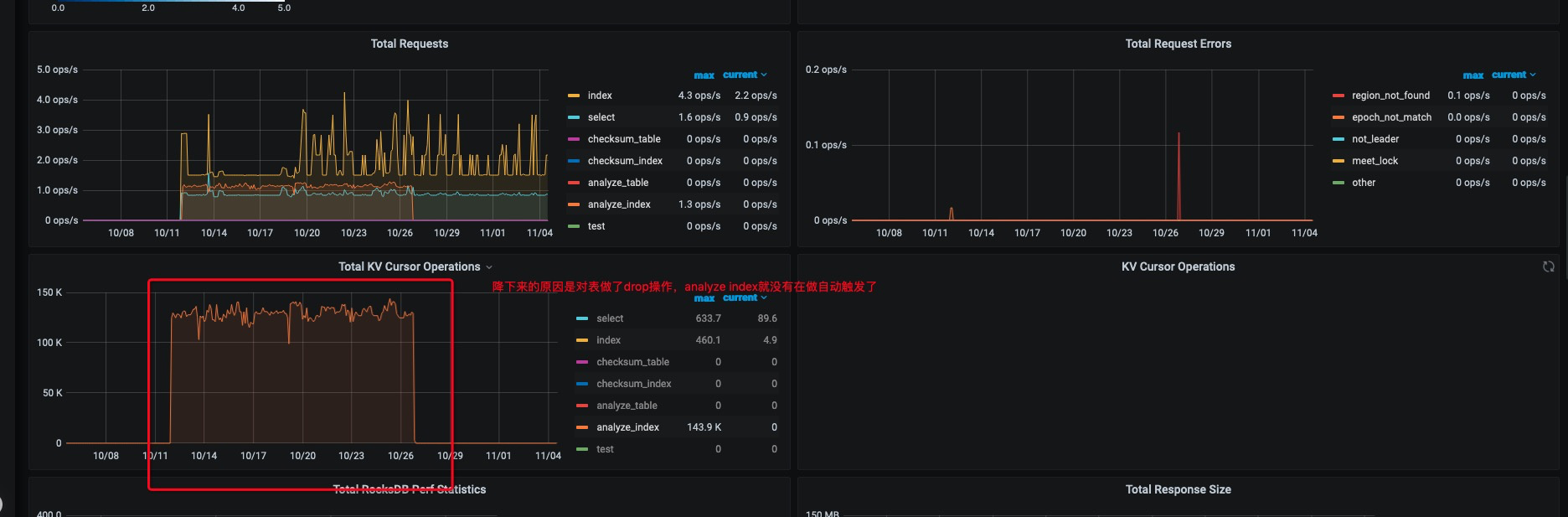
这个问题我们是通过drop 测试的表解决了。但是具体原因还得希望各位大佬能够回答下?
广泽苍山
2021 年11 月 9 日 09:31
7
广泽苍山
2021 年11 月 10 日 07:47
9
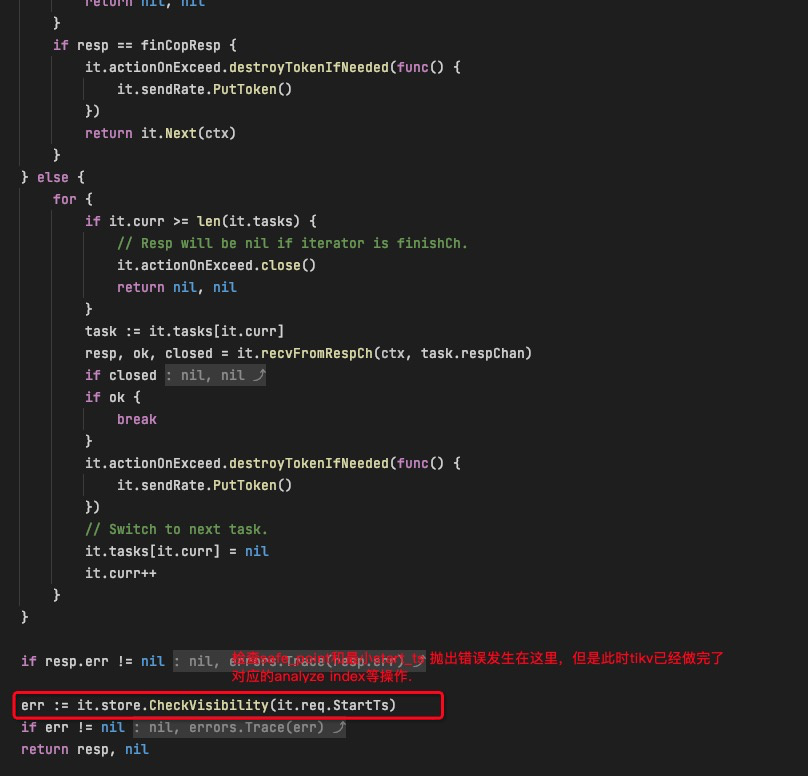
刚刚在研究过程中有了点新的思路,需要辛苦你这边帮忙确认下是不是理解正确。
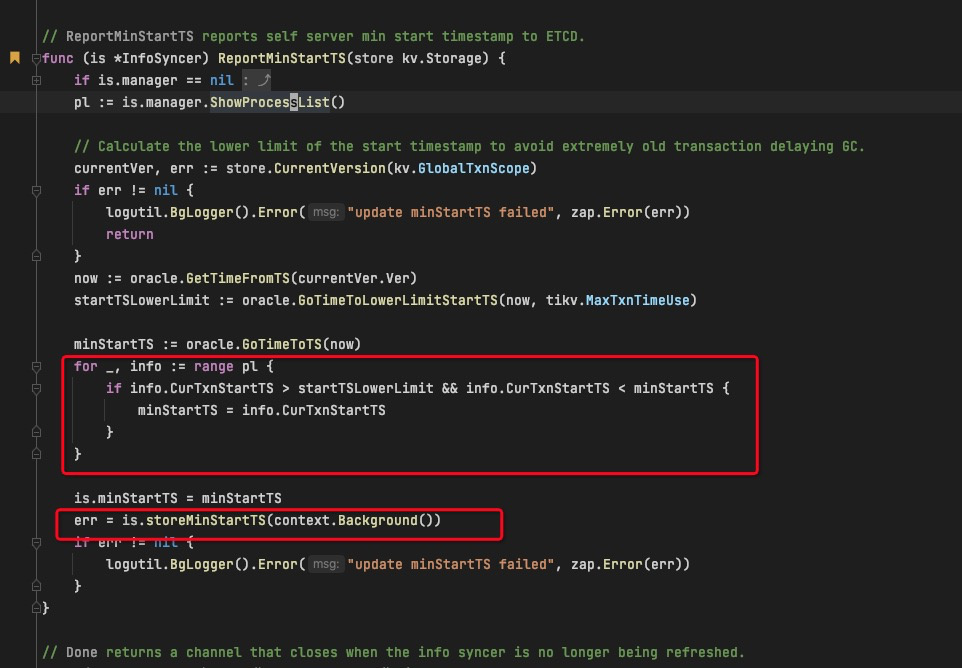
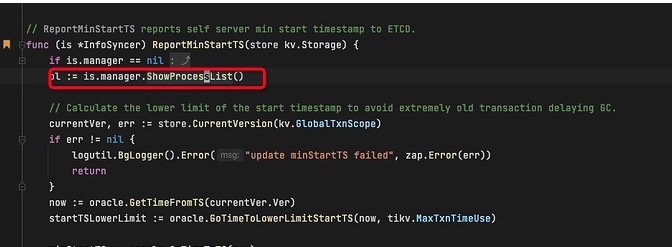
2.tidbserver代码中计算txn最小start_time的操作数据来源使用的是show processlist命令。
3.也就是说自动触发的分析任务analyze table 事务,它的start_time并不会纳入safe_point的计算之中。这也就导致了safe point会超过analyze table的事务的start_time,从而导致anlyze table失败。
不知道我这边的推理是否正确,辛苦tidb的大佬帮我确认,谢谢!@spc_monkey
4 个赞
h5n1
2021 年11 月 11 日 02:03
11
这里的showprocesslist 和mysql 客户端执行的show processlist是否相同? 活跃事务在tidb server内部是怎么组织的,是否有类似于innodb的read view这种结构? 另外看到有一个meta结构,每个未提交的事务信息是否在这里? 谢谢!
1 个赞
system
2022 年10 月 31 日 19:25
13
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。