为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
v5.2.1
【概述】 场景 + 问题概述
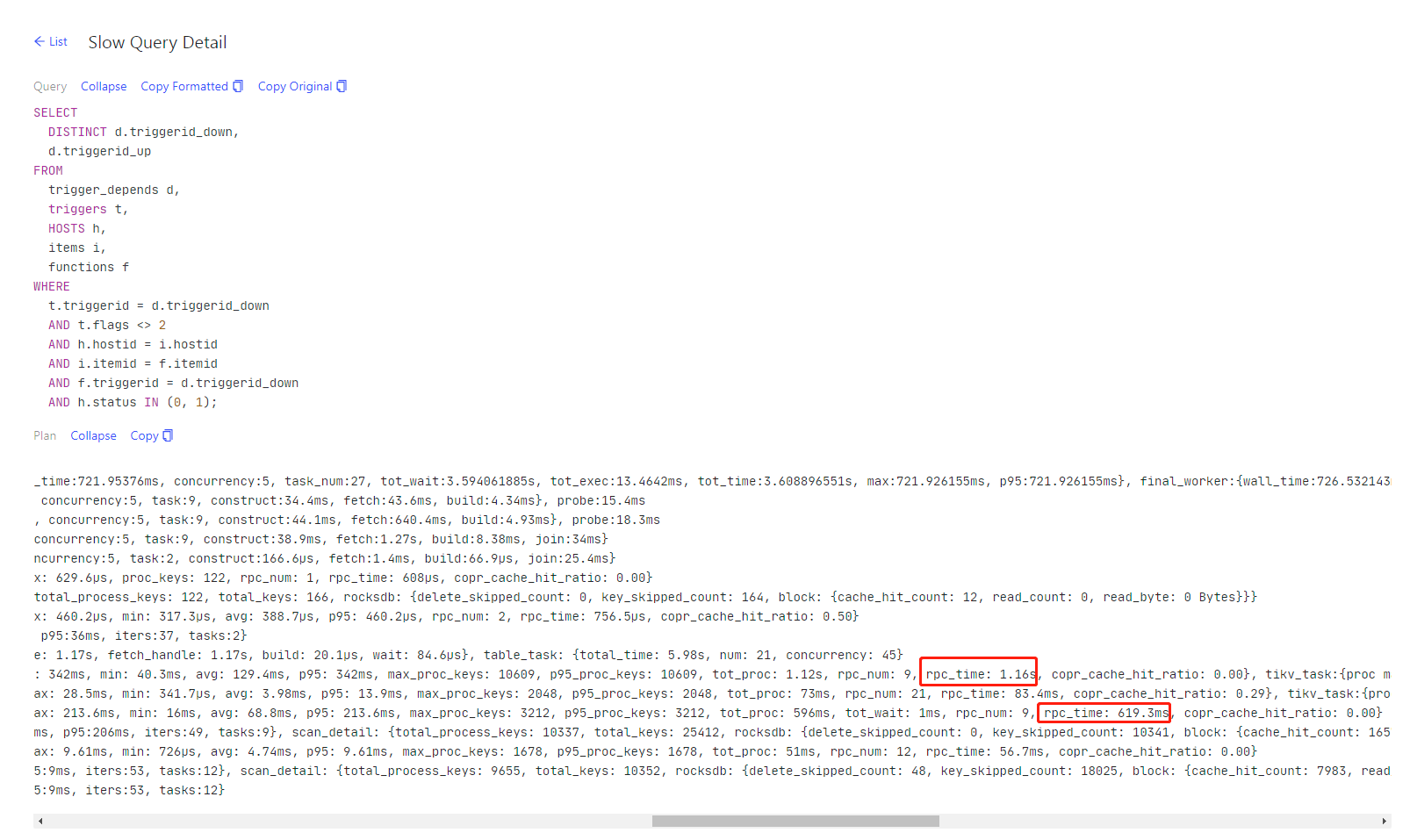
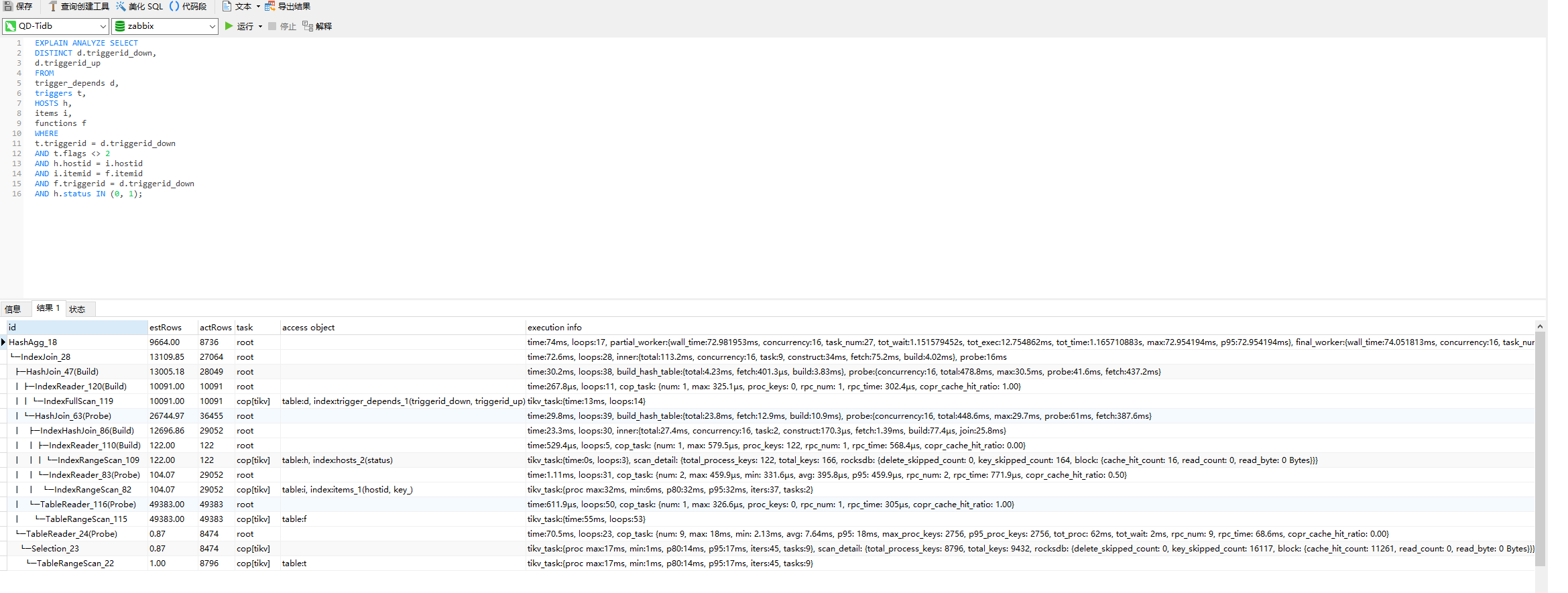
一、SQL语句如下,具体可以看截图:
SELECT
DISTINCT d.triggerid_down,
d.triggerid_up
FROM
trigger_depends d,
triggers t,
HOSTS h,
items i,
functions f
WHERE
t.triggerid = d.triggerid_down
AND t.flags <> 2
AND h.hostid = i.hostid
AND i.itemid = f.itemid
AND f.triggerid = d.triggerid_down
AND h.status IN (0, 1);
这些SQL语句涉及的表都很小,只有一个大于30M,其他的都小于8M。
二、慢查询的一些信息展示不懂,还望解释下:
time:622.8ms, loops:25, cop_task: {num: 9, max: 213.6ms, min: 16ms, avg: 68.8ms, p95: 213.6ms, max_proc_keys: 3212, p95_proc_keys: 3212, tot_proc: 596ms, tot_wait: 1ms, rpc_num: 9, rpc_time: 619.3ms, copr_cache_hit_ratio: 0.00}
这里的loops、cop_task啥意思啊。
cop_task里的num、tot_proc、totwait、rpc_num、rpc_time啥意思啊
三、这个rpc_time时间长可能是什么导致的?SQL慢查询,显示SQL语句 rpc_time时间长
【背景】 做过哪些操作
无
【现象】 业务和数据库现象
无
CREATE TABLE functions (
functionid bigint(20) unsigned NOT NULL,
itemid bigint(20) unsigned NOT NULL,
triggerid bigint(20) unsigned NOT NULL,
name varchar(12) NOT NULL DEFAULT ‘’,
parameter varchar(255) NOT NULL DEFAULT ‘0’,
PRIMARY KEY (functionid) /*T![clustered_index] CLUSTERED */,
KEY functions_1 (triggerid),
KEY functions_2 (itemid,name,parameter),
CONSTRAINT c_functions_1 FOREIGN KEY (itemid) REFERENCES items (itemid) ON DELETE CASCADE,
CONSTRAINT c_functions_2 FOREIGN KEY (triggerid) REFERENCES triggers (triggerid) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
CREATE TABLE trigger_depends (
triggerdepid bigint(20) unsigned NOT NULL,
triggerid_down bigint(20) unsigned NOT NULL,
triggerid_up bigint(20) unsigned NOT NULL,
PRIMARY KEY (triggerdepid) /*T![clustered_index] CLUSTERED */,
UNIQUE KEY trigger_depends_1 (triggerid_down,triggerid_up),
KEY trigger_depends_2 (triggerid_up),
CONSTRAINT c_trigger_depends_1 FOREIGN KEY (triggerid_down) REFERENCES triggers (triggerid) ON DELETE CASCADE,
CONSTRAINT c_trigger_depends_2 FOREIGN KEY (triggerid_up) REFERENCES triggers (triggerid) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
【业务影响】
无