【 TiDB 使用环境】
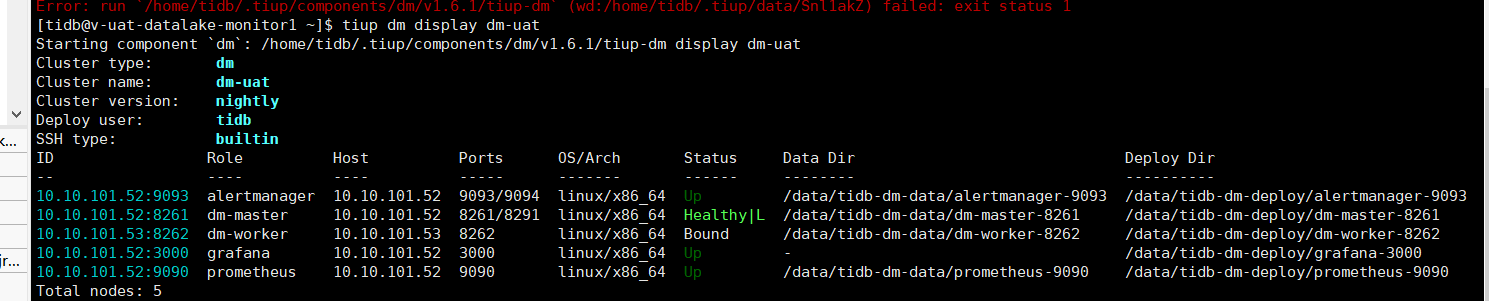
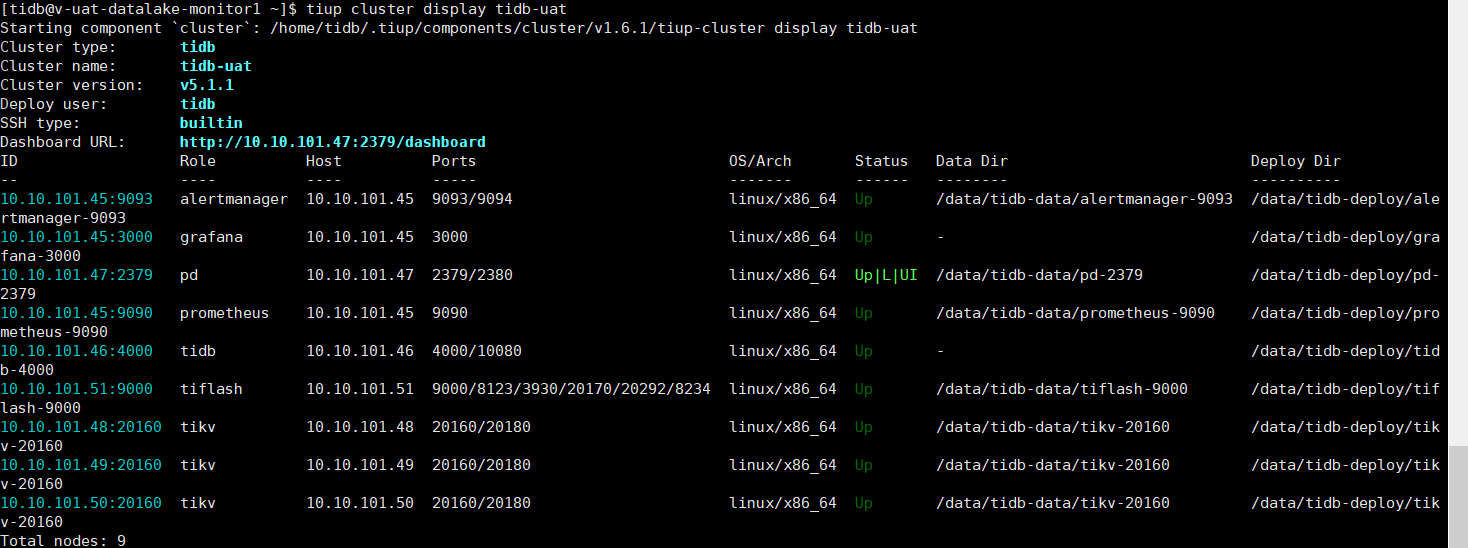
版本信息
TIDB V5.1.1
DM nightly
【概述】 场景 + 问题概述
场景:使用DM nightly,从Mysql5.7全量同步到TIDB V5.1.1
问题概述:
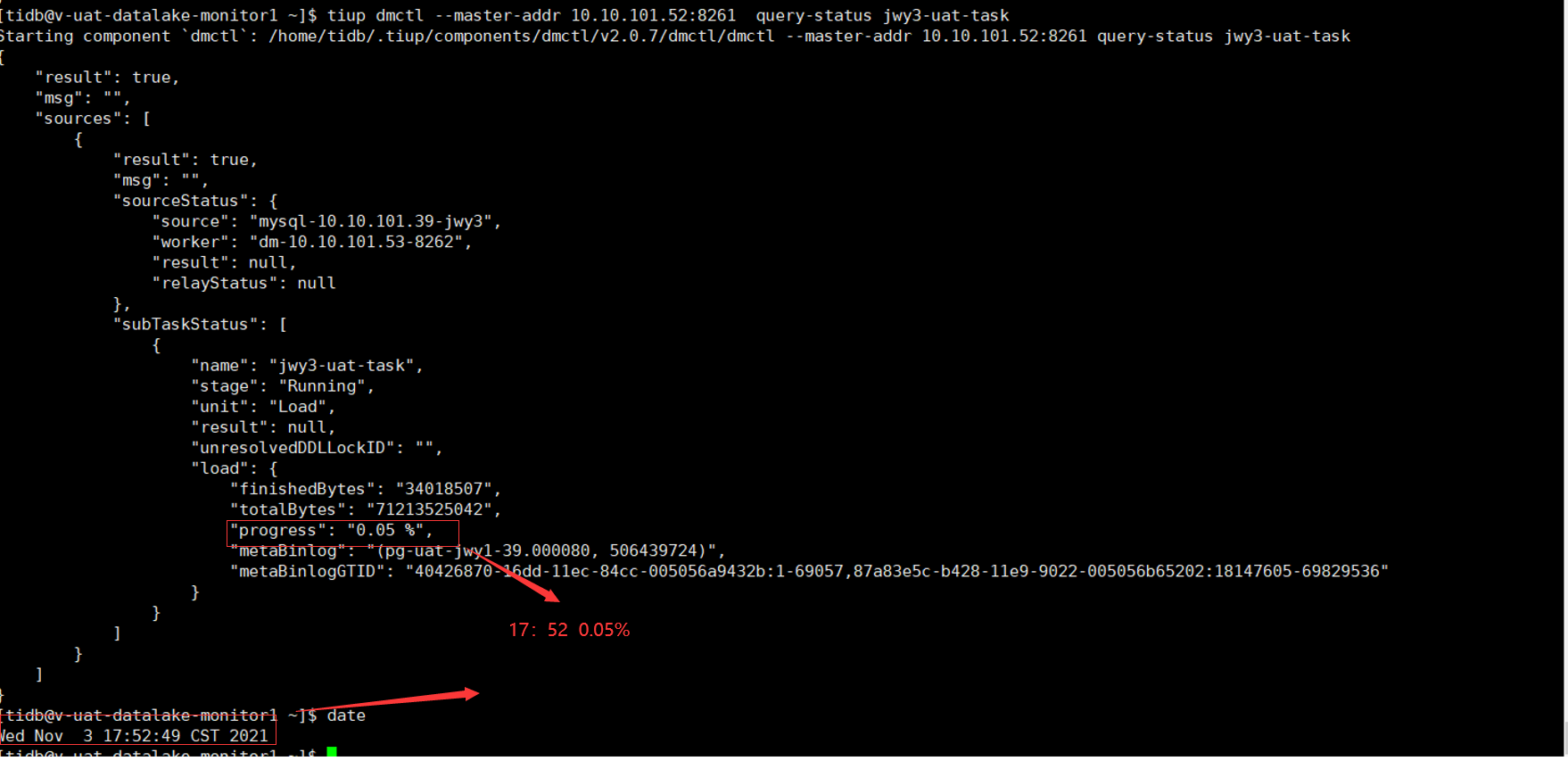
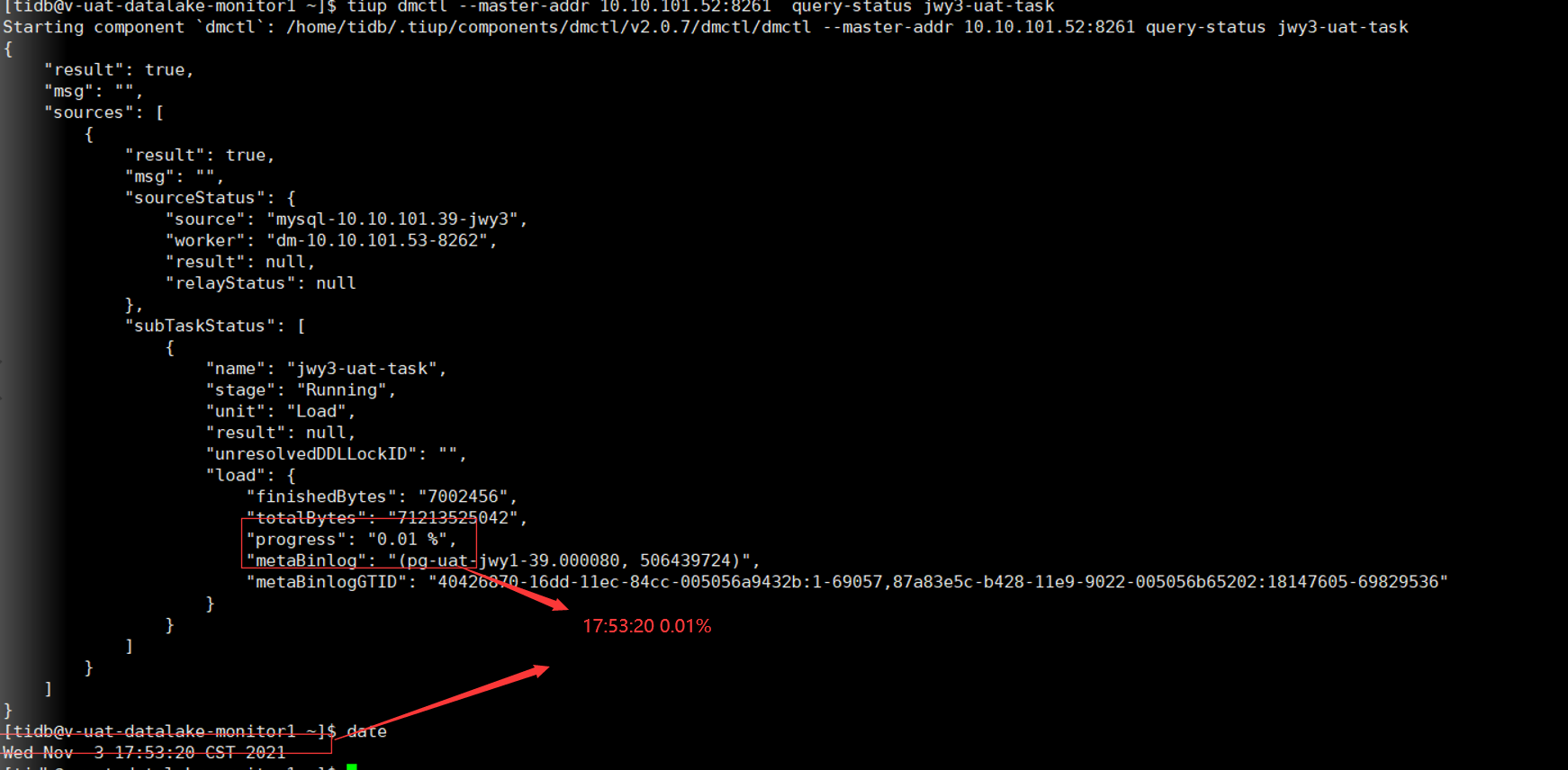
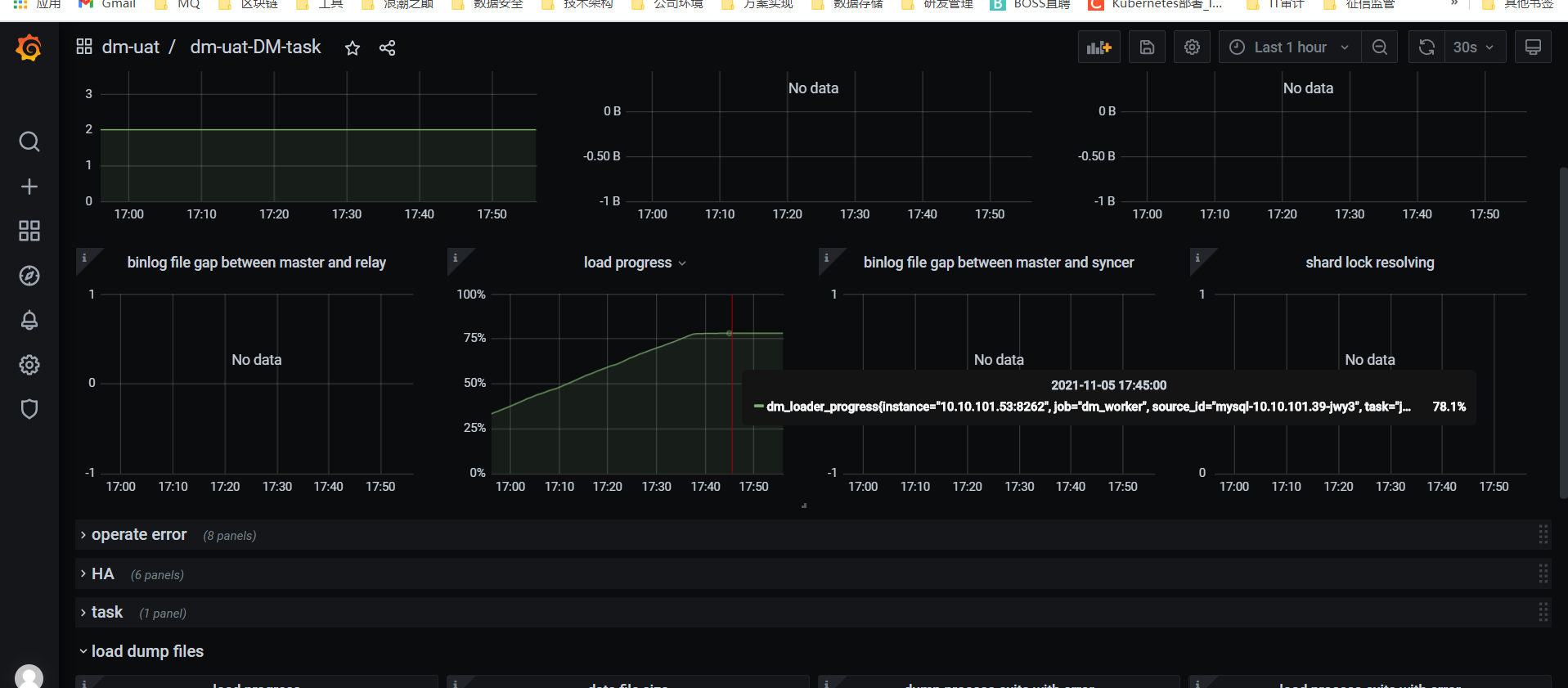
1、使用tiup dmctl --master-addr 10.10.101.52:8261 query-status jwy3-uat-task 时:load进度显示异常;
2、使用DM nightly同步数据非常慢,查看TIDB节点,日志里显示
[WARN] [region_request.go:956] ["tikv reports ServerIsBusy retry later"] [reason="scheduler is busy"]
【备份和数据迁移策略逻辑】
从Mysql5.7全量同步到TIDB V5.1.1
【背景】 做过哪些操作
1、在2021.11.3日,23点左右,修改TIKV参数,增加如下参数配置
tiup cluster edit-config tidb-uat
server.raft-client-grpc-send-msg-buffer: 1024000
storage.scheduler-pending-write-threshold: 1GB
修改后,再开始同步,开始比较快,后面同步又非常慢
【问题】 当前遇到的问题
1、使用tiup dmctl --master-addr 10.10.101.52:8261 query-status jwy3-uat-task 时:load进度显示异常;
2、使用DM nightly同步数据非常慢,约60G数据,同步11个小时还没有完成
【TiDB 版本】
V5.1.1
【附件】
相关TIDB DM-wordker日志:
10.10.101.46-v-uat-datalake-tidb.zip (7.9 MB)
10.10.101.48-v-uat-datalake-tikv1.zip (2.5 MB)
10.10.101.49-v-uat-datalake-tikv2.zip (17.5 MB)
10.10.101.50-v-uat-datalake-tikv3.zip (3.5 MB)
dm-worker.zip (9.0 MB)
topology.yaml (761 字节)
监控导出相关json:
tidb-uat-TiKV-Details_2021-11-04T04_13_16.333Z.json (34.7 MB) tidb-uat-PD_2021-11-04T04_12_11.444Z.json (4.5 MB) tidb-uat-TiDB_2021-11-04T04_10_27.630Z.json (3.5 MB) tidb-uat-Overview_2021-11-04T04_08_34.651Z.json (2.6 MB)
2 个赞
这道题我不会
(Lizhengyang@PingCAP)
2
参数 storage.scheduler-pending-write-threshold 不建议设置的过大,上面日志信息提示的报错是 ServerIsBusy,你可以先参考这篇文档排查下:
https://docs.pingcap.com/zh/tidb/stable/tidb-troubleshooting-map#43-客户端报-server-is-busy-错误
1 个赞
1、storage.scheduler-pending-write-threshold 这个是推荐多少合适? 256M
2、同时我看到日志里提示的 ["tikv reports ServerIsBusy retry later"] [reason="scheduler is busy"]
是否主要为scheduler is busy这部分
1 个赞
这道题我不会
(Lizhengyang@PingCAP)
4
需要提供监控数据看下,包括 overview/tidb/pd/tikv-details 监控数据,导出方式参考:https://metricstool.pingcap.com/#backup-with-dev-tools
1 个赞
这道题我不会
(Lizhengyang@PingCAP)
6
1.首先你这边集群的配置有点低,tikv 是 8c 16G ,磁盘类型和网络带宽看起来也是不符合标准的,测试性能肯定会遇到很多问题;
2.apply sync CPU 有瓶颈,apply log duration 很高,可以调大参数 apply-pool-size ;
3.scheduler latch duration 也很高,上游是 MySQL 分库分表合并过来的数据吗?
1 个赞
1、这块是用来做测试环境的用的是虚拟化的机器,因为业务和数据量不是太大,所以缩减了内存,磁盘类型和网络带宽应该是满足要求用的是 SSD+千兆网络
2、 可以调大参数 apply-pool-size 我改为4试下。
3、是把上游8个Mysql数据库,原样同步过来
1 个赞
这道题我不会
(Lizhengyang@PingCAP)
8
1 个赞
请问这参数是在哪设置,找了一圈,只看到说明,没有找到修改示例
1 个赞
这道题我不会
(Lizhengyang@PingCAP)
10
1 个赞
您好,问题仍存在,相关操作和日志已经上传,麻烦帮忙分析,谢谢
最新进展 时间2021-11-5 18:17
1、三台TIKV内存,已经从16G调整为32G;
2、已经修改 raftstore.store-pool-size: 4 目前所使用的 topology.yaml 的相关参数主要如下:
topology.yaml (795 字节)
server_configs:
tidb:
mem-quota-query: 8589934592
performance.txn-entry-size-limit: 62914560
tikv:
raftstore.raft-entry-max-size: 15M
raftstore.store-pool-size: 4
server.raft-client-grpc-send-msg-buffer: 1024000
storage.scheduler-pending-write-threshold: 300M
3、DM集群采用的V2.0.7 并增加 了load参数
loader-thread: 8
目前存在的问题:
1、DM同步无法正常同步结束 数据量66G左右,卡在78.2%
2、tidb日志节点报
[WARN] [region_request.go:956] ["tikv reports ServerIsBusy retry later"] [reason="scheduler is busy"]
最新日志如下:
pd-log-10.10.101.47.zip (413.7 KB)
tidb-log-10.10.101.46.zip (1.2 MB)
tikv-log-10.10.101.48.zip (1.6 MB)
tikv-log-10.10.101.49.zip (1.8 MB)
tikv-log-10.10.101.50.zip (2.2 MB)
监控面板Json:
tidb-uat-Overview_2021-11-05T10_15_10.632Z.json (1.5 MB)
tidb-uat-PD_2021-11-05T10_11_01.663Z.json (2.6 MB)
tidb-uat-TiDB_2021-11-05T10_14_04.427Z.json (2.7 MB)
tidb-uat-TiKV-Details_2021-11-05T09_59_54.055Z.json (20.5 MB)
目前问题已经解决
在tikv中发现存在如下日志
然后修改了
server.max-grpc-send-msg-len: 104857600
目前同步正常了
参见:
2 个赞
system
(system)
关闭
16
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。