h5n1
(H5n1)
1
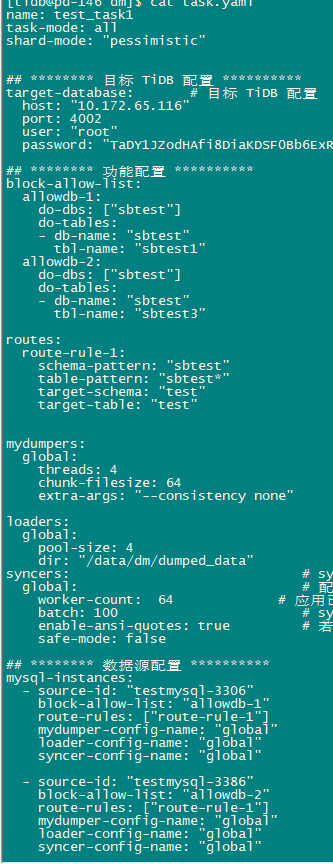
【版本】tidb v5.2.1、 DM v2.0.7 、sysbench 1.0.20,ARM平台
【场景】源端mysql 创建3张表。目标端tidb(20tikv实例、每实例3块普通ssd raid0)创建一张表,表上无唯一性约束,源端2张表sbtest1/3 写入到目标端的test表。源和目标表初始均为空表,目标表16个hash分区。使用sysbench(auto_inc=off) 32线程对源端3张表insert 10分钟。DM使用2个source指向同1个mysql库,每个source同步一张表。
【问题】
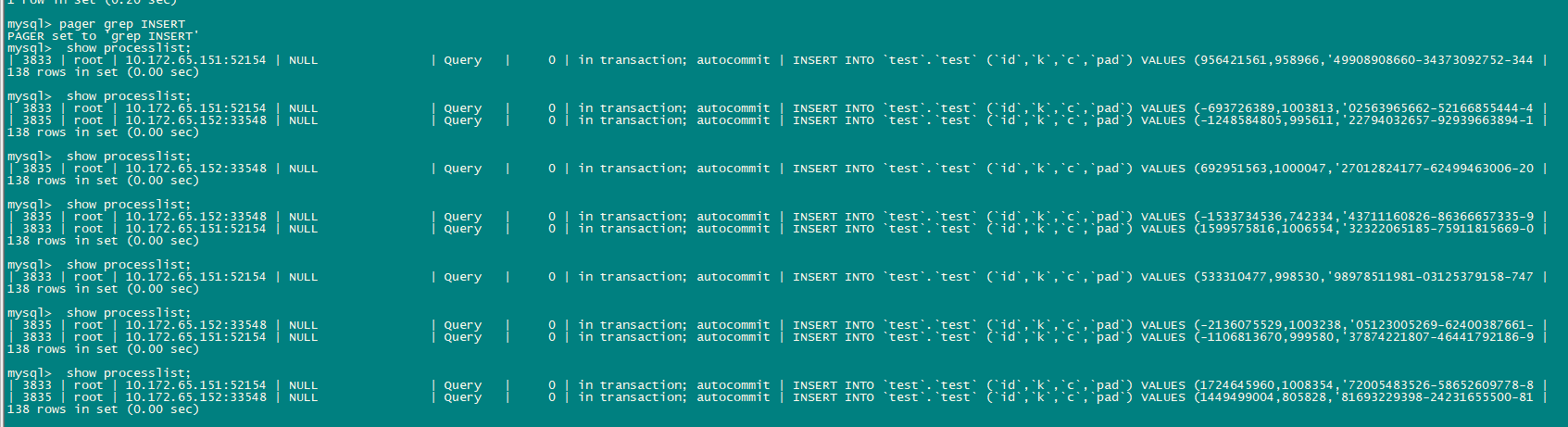
1 、测试发现DM同步延迟太大,show processlist查看tidb只有1、2个会话在执行insert。为什么目标端的并发Insert这么少?
2、测试期间发现tidb duration出现下降的情况,为什么在有压力的情况下该指标反而会下降?
3、 第一次测试后进行第二次测试,第二次时延迟只有几分钟,同样show process list也只看得1、2个insert执行,第一次执行开始时有些热点问题,但也不应该导致几十分钟的延迟吧。
第二次测试
小王同学Plus
(小王同学 Plus)
2
表没有主键或者唯一索引,DM是没有办法并发同步的。 看下这个帖子 DM 同步延迟问题
h5n1
(H5n1)
3
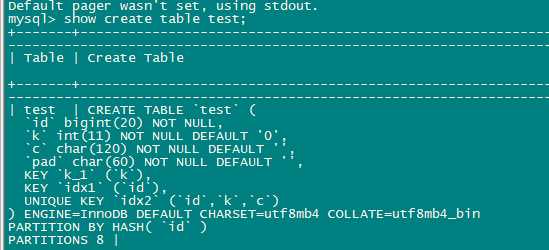
下游表增加了唯一约束,仍然延迟严重,insert并发很低
小王同学Plus
(小王同学 Plus)
5
梳理下你现在的问题是 DM 同步延迟大吗?
1.下游表添加唯一约束,上游表呢?
看了下 DM 相关监控,有一些不全,比如说 看 binlog file gap between master and syncer,该值不断增大怀疑是吞吐不够,还需要 DML queue remain length 进一步判断。
可以调整一下这两个参数观察下延迟情况
- worker-count:默认 16,下游压力不大情况下,可以调高(16 - 1024)
- batch:100,根据 transaction statement size 调节(20-1000)
h5n1
(H5n1)
6
问题有2个 1. 延迟的问题,上游的表都是有主键约束的,sysbench建的 2. tidb的durtation 在数据同步期间比空闲时还降低了,不知道是什么原因。
worker-count 配置的64
小王同学Plus
(小王同学 Plus)
7
batch 有调整过吗?dm-worker 机器配置是怎样的?
这个麻烦用 [FAQ] Grafana Metrics 页面的导出和导入 完整导出下 DM 的监控。
另外 tidb duration 的包括 TiDB 内部执行的一些 SQL,业务空闲时显示的应该是大部分内部 SQL 导致,也可以选择固定时间段通过 dashboard 监控看一下,不过没超过慢日志阈值应该就没有记录
h5n1
(H5n1)
8
batch调整到999后重新测试,监控见附件,关于duration 空闲时有内部活动,非空闲时应该也有内部活动吧。
btjh-TiDB_2021-11-03T09_58_33.463Z.json (6.0 MB) testdm-DM-task_2021-11-03T09_56_40.946Z.json (309.8 KB)
dm worker 用numa绑在16核的node上
小王同学Plus
(小王同学 Plus)
9
从监控上看你这边应该是开启 relay log 了, 如果开启 relay log,会增加一次写磁盘和一次读磁盘操作,建议关闭 relay log
小王同学Plus
(小王同学 Plus)
11
额,这截图信息太少,也看不出来什么的
另外 DM 同步到下游 TiDB 中,可能是下游消费慢,也可能是 DM 吞吐能力不够。如果是消费慢,可以按照文档自行排查 TiDB 写入慢流程排查系列(一)— 前言
h5n1
(H5n1)
12
DM 吞吐能力指的是哪些部分? 该如何调整? 观察着就是tidb上的并发insert太少,每个tikv实例是24核 3-4个SSD的raid0,最大32个write buffer
小王同学Plus
(小王同学 Plus)
13
DM 的处理能力,受 cpu 性能影响较大,在下游无瓶颈的情况下,实测 binlog event qps 在每条 binlog 只有一行 value 时,可达到 20k 以上。
可以通过看 binlog file gap between master and syncer,如果该值不断增大就是吞吐不够,如果该值为 0 而下游数据插入缓慢则为延迟过大。
如果确认是 吞吐能力不够导致的同步慢,可以接下来 查看 DML queue remain length 的监控项。
- DML queue remain length 长时间为 0,说明下游无瓶颈,可通过调大 worker-count 和 batch,增大 DM 同步线程和事务的语句数量。若 binlog event qps 还是没有变化且 DML queue remain length 长时间为 0,可认为 DM 到达瓶颈了。
- DML queue remain length 长时间不为 0,说明 DM 中堆积了一定量的 binlog,下游消费速度跟不上 DM 从上游拉取 binlog 的速度,瓶颈在下游。
你这边修改了 worker count ,是不是没生效?或者上游的表是否没有唯一索引/主键啊?不应该并发数量少才对。
h5n1
(H5n1)
关闭
14
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。