1.tidb集群版本:v5.1.1
2.问题描述:集群原本有3台tikv(50、51、52),现在扩容1台tikv(60),扩容过程中先是51这台tikv状态出现disconnect(tiup cluster display tidb-cluster),使用tiup cluster restart命令重启了51恢复正常,后面换成50出现该问题,检查服务发现50的tikv服务一直在自动重启。怎么处理这个问题?
日志:messages.tar.gz (17.1 KB) tikv-log.tar.gz (17.4 MB)
1 个赞
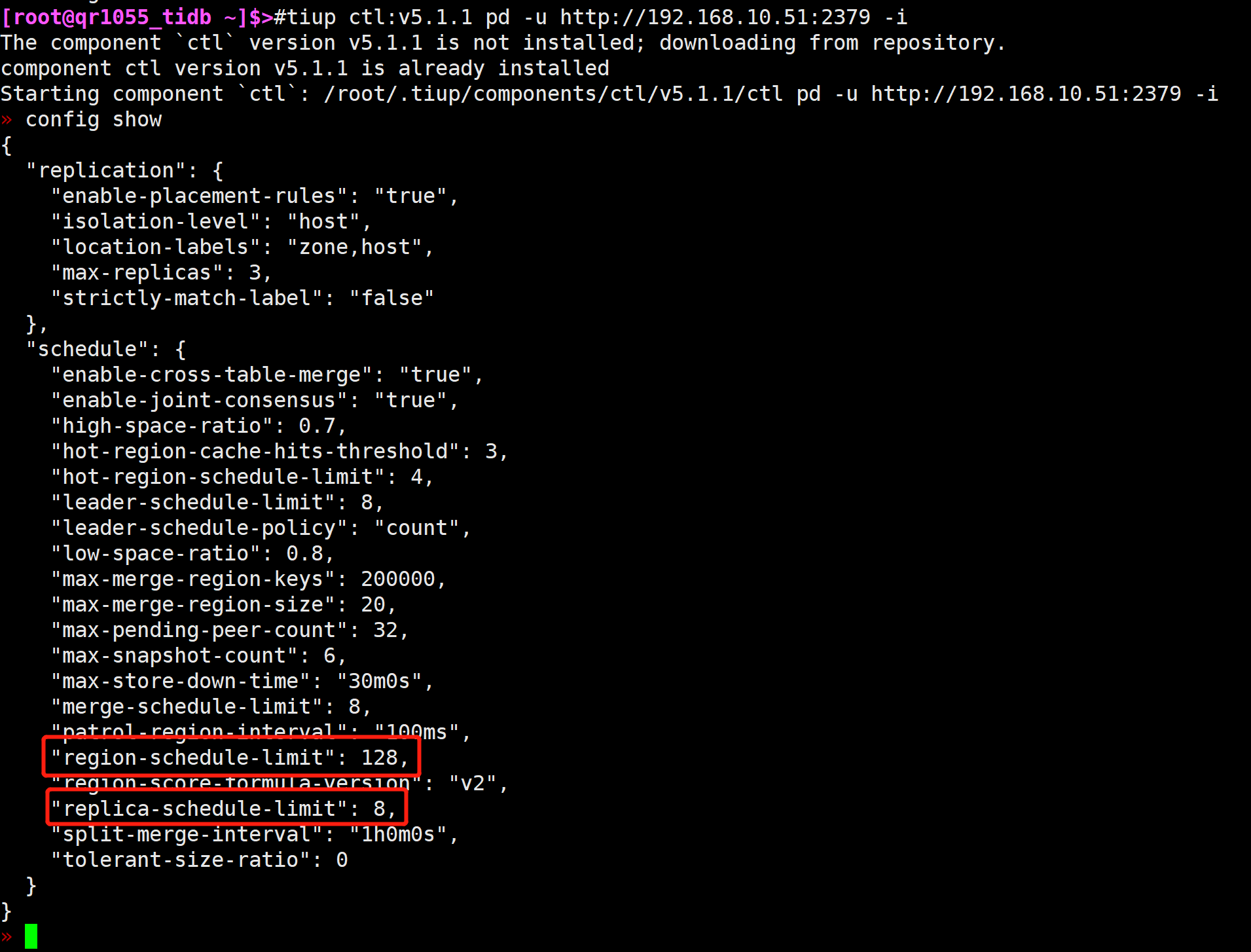
按你说的,扩容流程没有什么不妥,可以把region-schedule-limit和 replica-schedule-limit调小
config set region-schedule-limit 128
config set replica-schedule-limit 8
至于disconnect,那是可能因为此tikv的压力过大导致的,导致和pd有超过30s的失联,可以看看原有的tikv主机负载情况和请求时延情况。
1 个赞
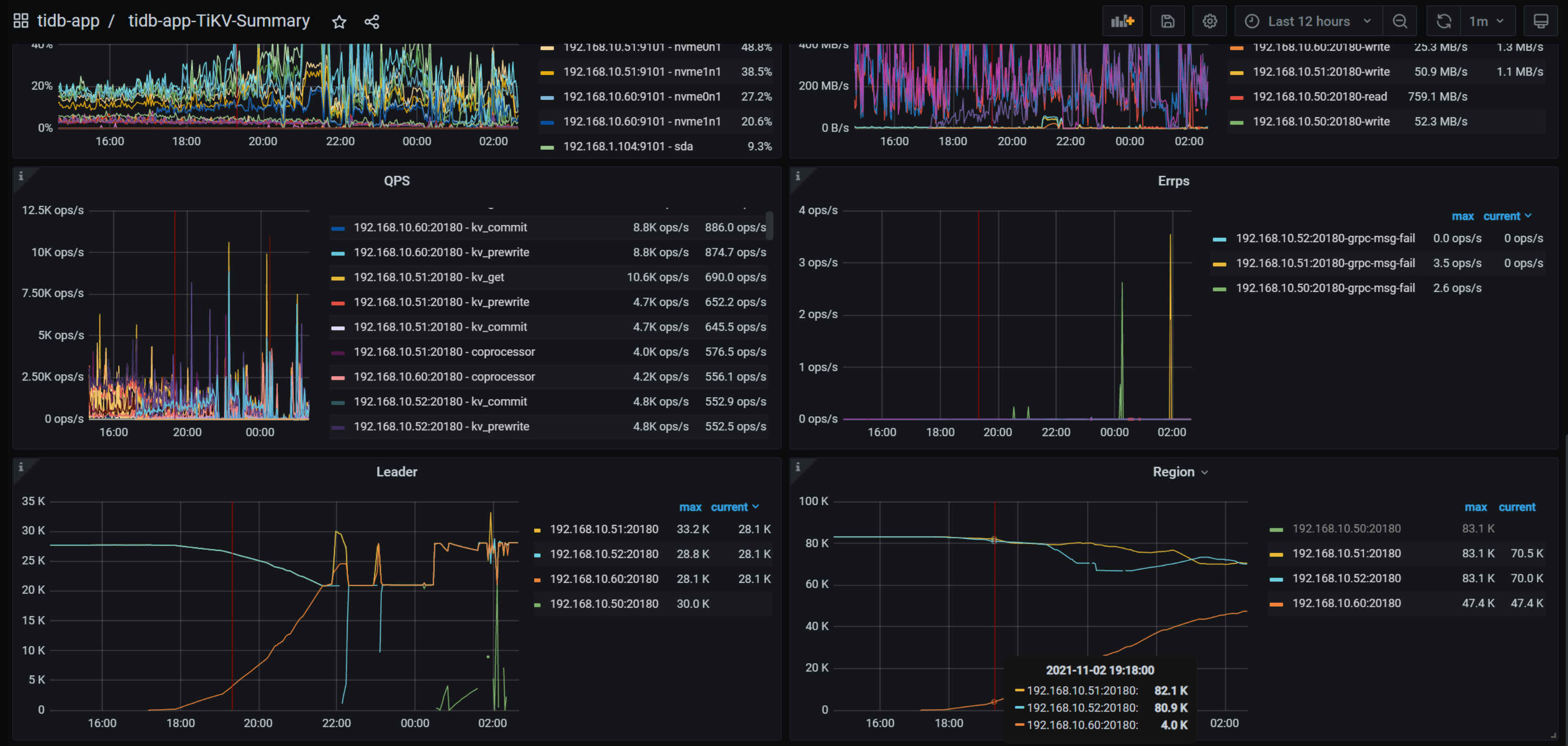
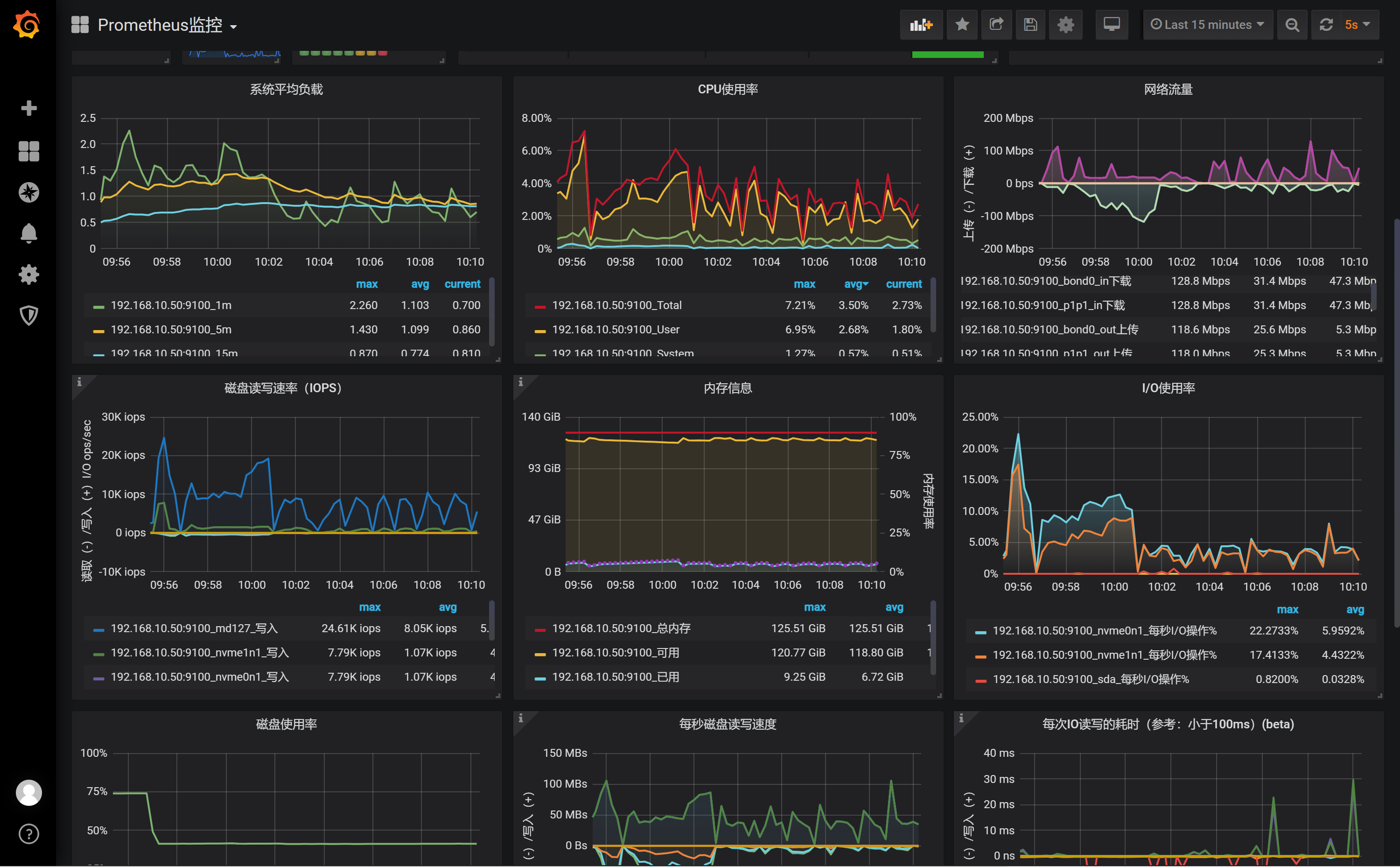
我们没有更改region-schedule-limit和 replica-schedule-limit这2个参数,之前只是调大了store limit,全部调到了500,现在调回了50,但是50这个tikv节点还是会自动重启。查了下50这个tikv节点的服务器监控,并没有压力大的问题。

1 个赞
补充:
1.这是刚记录的tikv的WARN日志,tikv每重启一次就会产生一个300M日志文件,重启太频繁产生了很多日志文件,现在只能先把这台的tikv服务停掉了,有什么解决办法可以解决吗?
日志:tikv_stderr.tar.gz (39.5 KB) tikv-log-2.tar.gz (21.6 MB)
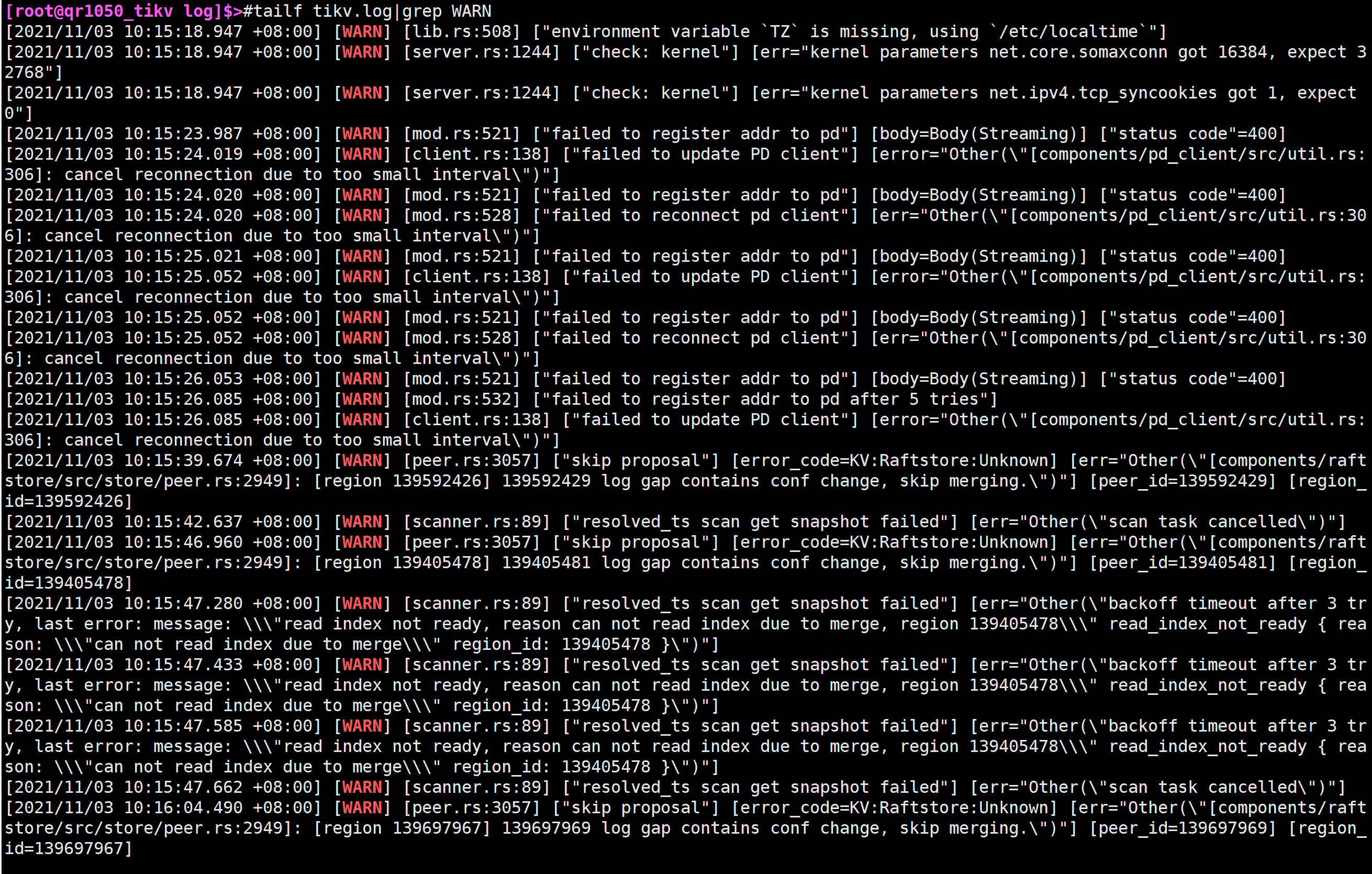
2.今年上半年的时候tidb集群从华为云迁移到了本地机房,当时为了控制流量设置了tikv的location-labels:zone和host,当时把isolation-level设置为了zone,做完迁移后改成了host,一直延续到现在,不知道跟这个有没有关系。
2 个赞
如果只是不想生成警告日志的话,可以把日志级别改成error,这样就只会输出错误日志了。
2 个赞
现在问题的关键不是日志,而是tikv一直自动重启,一重启就会生成一个300M的归档日志,把tikv自动重启的问题解决了就不会频繁产生日志了。
2 个赞
看下系统日志 是什么导致的重启
2 个赞
把leader-scheduler-limit先改成0,tidb有coprocessor缓存,每次leader迁移,缓存失效。会导致tikv重新扫一遍。你先不让leader动,先让replica复制到新扩的tikv上以后,再动leader。这样试试。
2 个赞
50的tikv还是会重启,只不过重启的频率低了,变到5分钟一次
2 个赞
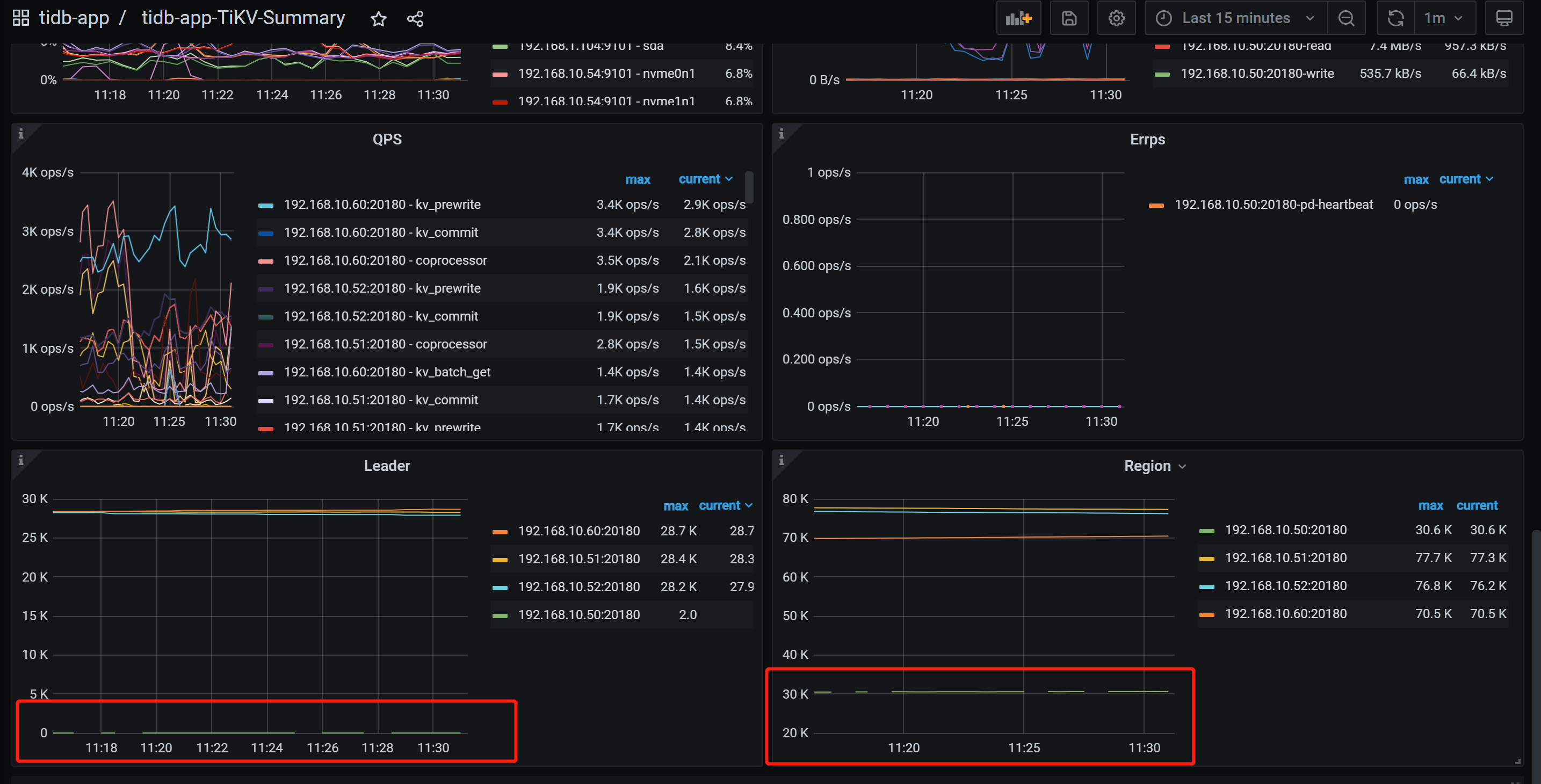
监控导出来看下?
2 个赞
2 个赞
TiDB、PD的麻烦都发一下,发detail吧,summary看不出来问题。
2 个赞
tidb-app-TiDB_2021-11-03T07_27_03.380Z.json (4.0 MB) tidb-app-PD_2021-11-03T07_28_52.398Z.json (162.2 KB) tidb-app-TiKV-Details_2021-11-03T07_30_57.649Z.json (19.7 MB)
2 个赞
我也没看出什么问题,只看到0点20的时候,你的集群的delete和replace增多了很多。tikv50就挂了。
tikv50的apply log在0点20的时候慢一些。
现在集群如果没恢复的话,可以试试,先把schedule leader放开,然后
scheduler add evict-leader-scheduler xxx
把50上的leader先驱逐出去。然后分析下tikv的日志,看看什么原因。
继续坐等tidb的大神们回答。很遗憾没帮上忙![]()
2 个赞
@Kongdom 版主大人,安排个大神解决下撒![]()
1 个赞
@小王同学Plus 呼叫支援~
1 个赞
需要确认下以下几个信息:
- 1.麻烦确认下这台 tikv 第一次 Panic 的时间(精确到时间点),获取第一次 Panic 重启前后的 tikv 日志
- 2.这台机器首次 welcome 重启时,应该也是 Panic 的信息,获取到 Panic 中的 region, find . -name “tikv.log*” |xargs grep “region ID”,(获取 region ID 的方式见截图)
- 3.对这个 TiKV 当前 data/snap 目录 ls -lh|grep region ID 并贴一下结果吧。(也是用第一次 Panic 的获取到的 region ID)
比如这个
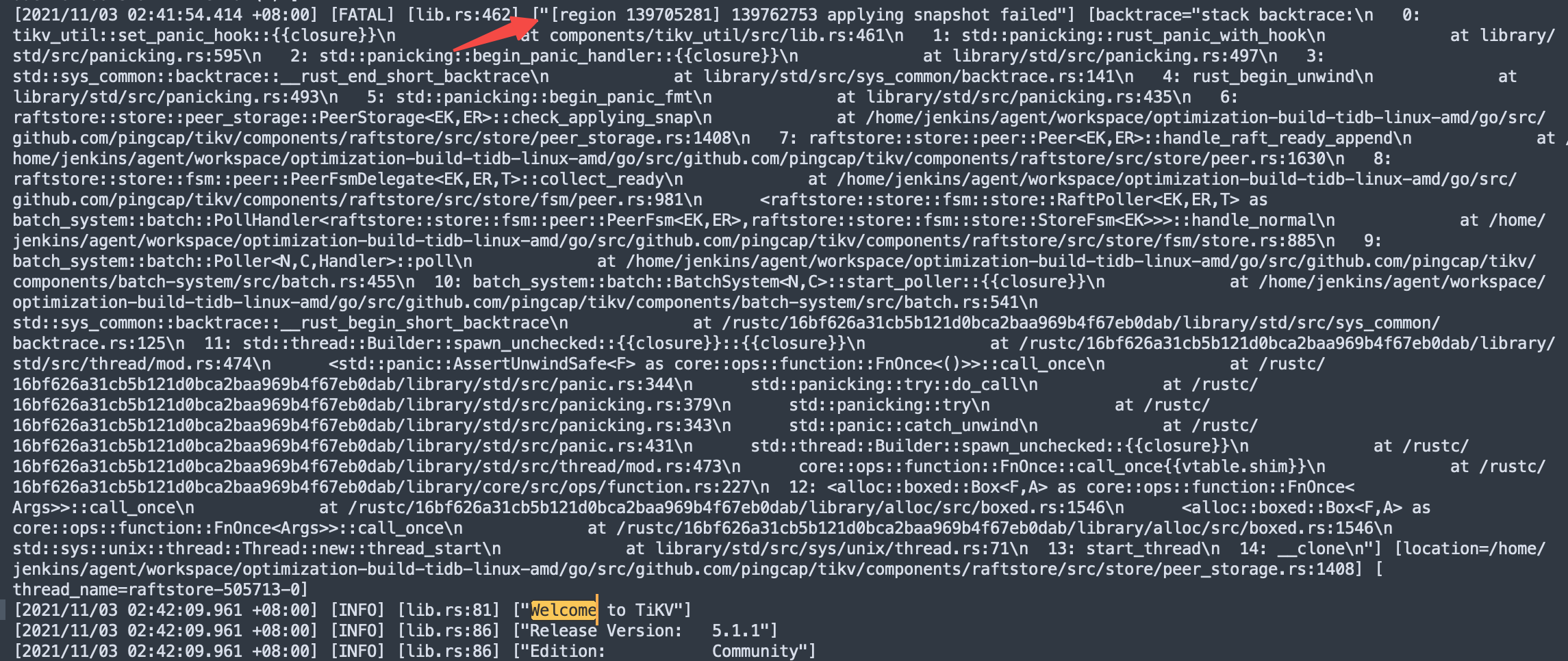
通过日志这块我看到的是第一次重启是 2021/11/03 02:41,日志有点少~
2 个赞
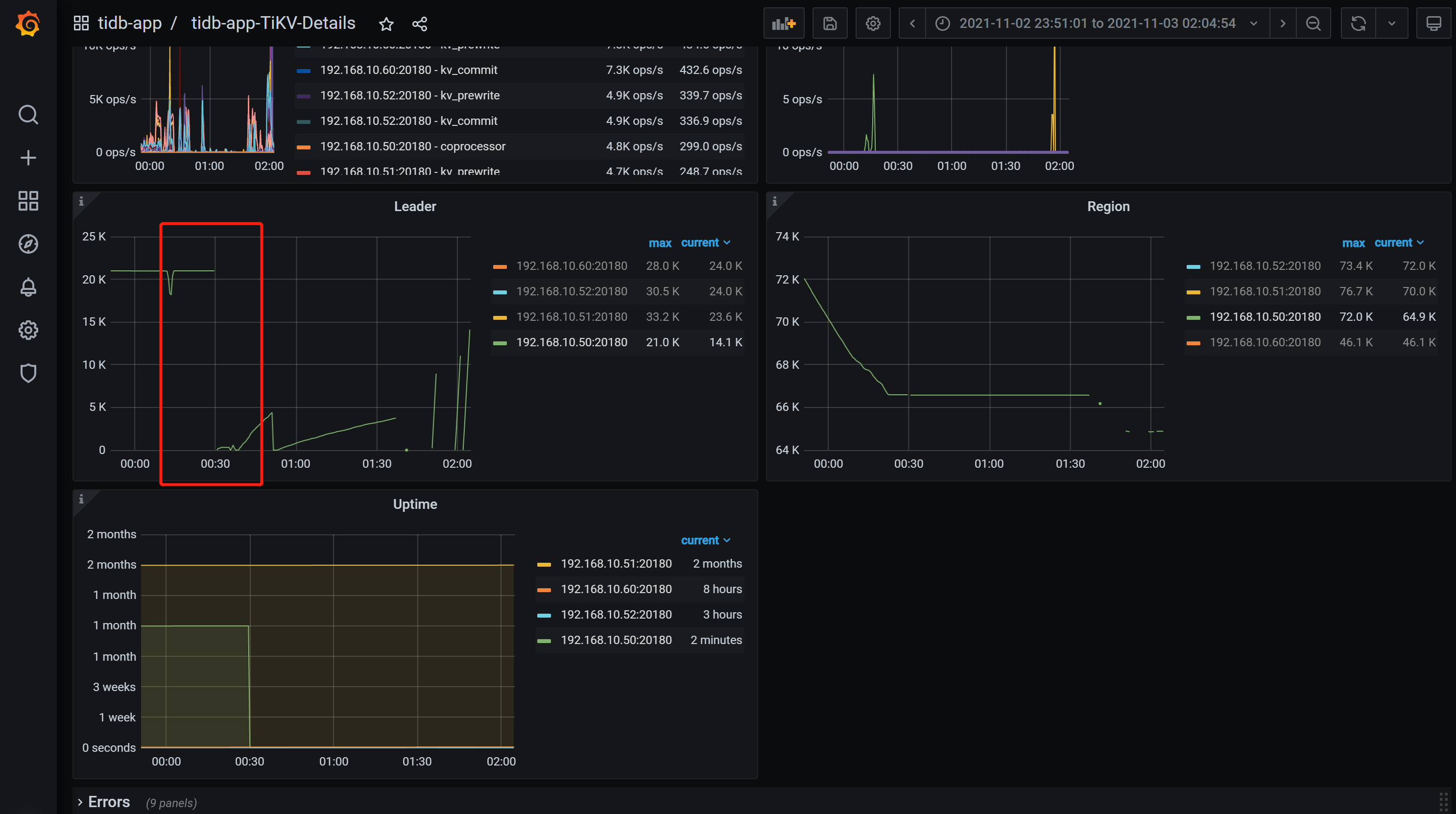
没有找到FATAL日志,第一次重启的大致时间在监控中可以找到,该时间前后的日志文件tikv.log.tar.gz (45.3 MB)
1 个赞