紫光云对象存储
2021 年10 月 29 日 09:07
1
【 TiDB 使用环境】
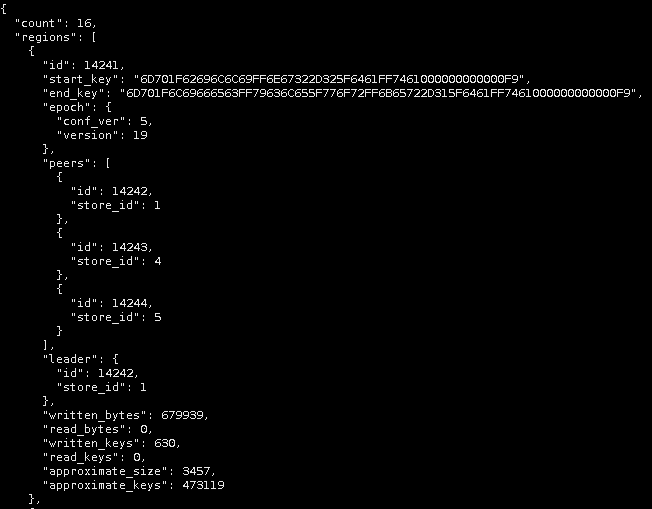
同时pd检测到该region过热,频繁切换leader
【背景】:做过哪些操作
【现象】:业务和数据库现象
【问题】:当前遇到的问题
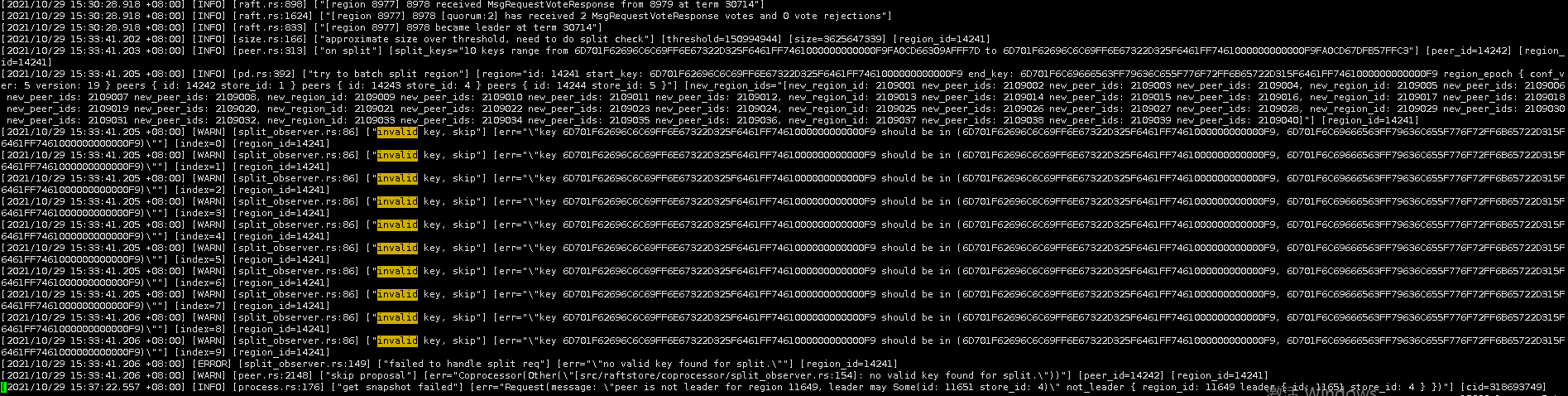
目前我们的分析是前端业务持续写同一个key,由于MVCC机制,在旧value被回收前region会不断变大。由于是写同一个key,region无法分裂,只能通过gc回收。但是由于pd的hot region调度策略,region leader被频繁切换,导致gc被打断,旧value长时间得不到回收。
以上是我们的分析,请问应该如何解决
【业务影响】:
【TiDB 版本】:3.1.0
【附件】:
2 个赞
小王同学Plus
2021 年11 月 2 日 02:16
4
紫光云对象存储:
【TiDB 版本】:3.1.0
这个版本不太推荐,后续方便的话可以升级到 4.0 或者 5.x 版本。
你的 region ID 是 14241 才对
另外推荐使用 pd-ctl 手动 split 该 region,观察下分裂情况。
还想确认下这边业务情况是怎样的?是否是大压力下的追加写?如果写入速度大于分裂速度,很有可能出现大 region 的情况 https://github.com/tikv/tikv/pull/9897
1 个赞
紫光云对象存储
2021 年11 月 2 日 03:21
5
1.因为线上已经跑着业务了,升级的话需要评估风险,后续是会考虑的,不过目前还是倾向于在当前版本解决问题
Meditator
2021 年11 月 2 日 08:55
6
这里看不明白。
紫光云对象存储
2021 年11 月 4 日 01:58
9
感谢提供业务背景信息,大 key 分裂失败对业务的影响是怎样的?
目前业务没有明显影响,就是经常收到prometheus的告警,“TiKV approximate region size is more than 1GB”。担心有未知的影响,所以还是希望能找到原因,从根上解决问题
集群的拓扑是 tidb+tikv+pd 还是只有 tikv+pd ?
只有tikv+pd
这个问题还有几点疑问:
监控数据导出工具:
作者:Kennytm Chen 、Rick lee
如果监控信息不方便上传到帖子中,可以以私信的形式发我
2、如果是写入的速度大于 split region 的速度,那么可能需要升级到带有这个 https://github.com/tikv/tikv/pull/9897 的 TiDB 版本。但是在升级之前是否有其他跳过的方式,这边内部确认下,有信息会跟帖回复
请再尝试下下面的方式是否可以导出:
1、chrome 安装这个插件 https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
2、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
3、使用这个 full-page-screen-capture 插件进行截屏保存
gopher
2021 年11 月 9 日 03:03
13
你好这个插件下载出问题了我在虚机上进行的部署和面板监控下载页面出错同时在Dashboard上页面很久也没加载成功
gopher
2021 年11 月 9 日 05:59
14
你好照着做了以后还是这个页面我的导出好像没问题每一步都照做了,怎么又回到了这个页面
gopher
2021 年11 月 19 日 02:43
15
[gc worker] skipping garbage collection because gc interval hasn’t elapsed since last run 你好现在实验环境一直报错,gc的间隔默认是10m0s,现在的实验写入超过阈值144后就会启动gc,这个时间小于gc默认的间隔,所以gc报错需要怎么解决
理论上,如果使用的是 TiKV+PD 这样的架构。那么理论上,在 TiKV-Details 监控中,GC 是没有监控数据的 ,GC 的触发是由 TiDB Server 的 GC Owner 来触发(tikv-client 调用 GC 手动或外部触发除外),然后再由各个 TiKV Server 从 PD 获取 gc safepoint 然后再进行 GC 操作。
所以,现在的问题是确认下 GC 和 Region 分裂报错的必然联系 ~
另外,如果 tikv.log 中出现 split 的报错。和业务行为的相关性比较大,我们的业务行为是一个持续追加写,并且业务压力会比较大,那么在较早的版本中,会出现这个现象。如果 TiKV-Details 的监控导出有异常,那么可以提供下述 metric 在出现你上面描述的问题时间区间的截图 :
TiKV-Details --> Server --> Approximate Region size
dbaspace
2021 年11 月 25 日 10:50
19
为什么会设置这么大的REGION 难道是因为写入大 减少发生9005问题么
gopher
2021 年11 月 26 日 03:17
20
你好现在的实验环境是TIKV+PD+TIDB的架构依旧是上述这样的错误信息和相同的实验现象。
首先,根据之前沟通的架构,生产环境为 TiKV+PD,并没有 TiDB 节点。而现在你那里的线下测试环境是 TiDB+TiKV+PD,两个不同的架构,GC 的逻辑本身就不同。所以,不建议将两个不同架构的问题混在一起查看,这样可能会引起混淆 。
其次,针对生产环境 TiKV+PD 架构,出现的 Region 上 GB,且 batch split 失败的现象,建议你那里拿下生产环境, 出现你上面描述的问题时间区间的截图 :
TiKV-Details → Server → Approximate Region size
TiKV-Details → Grpc → gRPC message count