KS贺大伟
2021 年10 月 28 日 03:48
1
Bug 反馈清晰准确地描述您发现的问题,提供任何可能复现问题的步骤有助于研发同学及时处理问题
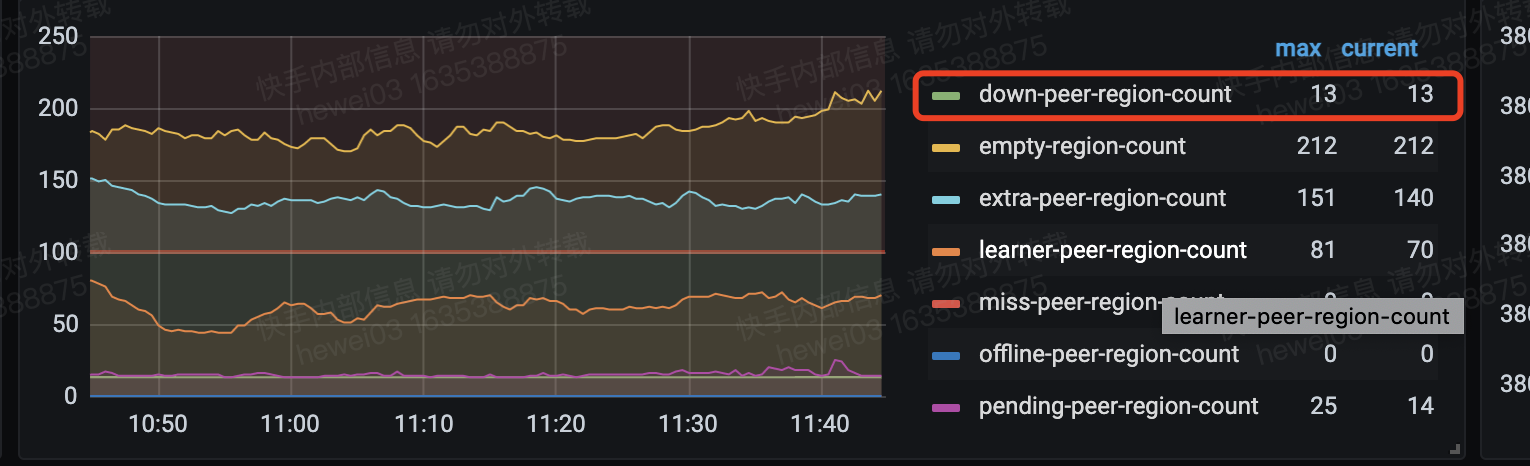
查看region down peer,发现region的down peer和pending peer在同一个store上,PD上手动remove peer,提示成功,但是region信息没有变化,这个store上查看region的信息,提示没有这个region的副本
【 Bug 的影响】
【可能的问题复现步骤】
【看到的非预期行为】
【期望看到的行为】
【相关组件及具体版本】如集群拓扑,系统和内核版本,应用 app 信息等;如果问题跟 SQL 有关,请提供 SQL 语句和相关表的 Schema 信息;如果节点日志存在关键报错,请提供相关节点的日志内容或文件;如果一些业务敏感信息不便提供,请留下联系方式,我们与您私下沟通。
region 221722354
2 个赞
KS贺大伟
2021 年10 月 28 日 03:49
2
补充store 4上查询region信息,提示没有:
1 个赞
KS贺大伟
2021 年10 月 28 日 04:03
3
另外提一个小建议,这region信息中可不可以增加一个last heartbeat time,因为存在一种情况,就是其实region已经没有leader了,但是PD的信息都是leader上报的,导致从PD的视角看,region总是存在leader的,这就造成误导,增加一个heartbeat信息,这样就可以快速判断出这个region其实已经没有leader了,因为上一次心跳距离现在太久了,当集群规模大的时候,尤其是遇到一些问题的时候在,这个信息还是很管用的
1 个赞
KS贺大伟
2021 年10 月 29 日 06:22
5
这个问题通过重启问题store,然后人工在PD上手动remove peer修复。但是我查看TiKV日志的时候发现,这个down peer所在的store一直打印如下的日子,而其他store确没有类似的日志,重启这个store,问题仍然存在。
这里我看到它尝试解析store 9,但是目前PD中没有store 9,应该是一个已经废弃的store,相关的信息在pd上是被清理掉了。
1 个赞
之前对 store9 进行了什么操作?是否有过强制下线和 remove tombstone 等?
1 个赞
通常来说,我们是不建议进行 强制下线+ remove tombstone 的,这样会导致没有下线完成的 region 在其他节点的 peer 仍然残留已经被清除的 store 的 peer 的信息,而 pd 又不知道;
是否尝试通过 pd-ctl 手动删除掉 down peer 信息?
1 个赞
KS贺大伟
2021 年11 月 3 日 10:11
9
手动删除可以清理掉down peer,但是down peer的位置并不是已经墓碑的store
1 个赞
KS贺大伟
2021 年11 月 3 日 10:14
10
之前运维tidb的同学须告诉我,只下线一个store,仍然会有peer调度过去,下线过程非常漫长,因此一般会强制下线,然后标记为墓碑以加速这个过程。
1 个赞
只下线一个store,仍然会有peer调度过去
这个说法是不成立的,下线 store 后就不会将其作为 store 的 target 的,只可能是因为持续写入 split 在 offline 的节点上才可能出现新 peer
强制下线,然后标记为墓碑以加速这个过程。
强制下线和标记为墓碑不会加速这个过程;而且如果 remove tombstone,还会导致没有下线完成的 region 在其他节点的 peer 仍然残留已经被清除的 store 的 peer 的信息,而 pd 又不知道;极其不推荐这样的作法
如果想加速,可以考虑调整 store limit,比如在不影响业务前提下调大剩余可用节点的 add peer limit。
确实下线一个store时间很长,存在很大的风险,期间如果遇到其他的节点异常,那么可能就会造成集群不可用。
对于,“在下线不可用的节点时,再挂掉一个节点”的场景下,强制下线和不强制下线,丢数据风险是一样的;
但是对于,正常缩容,下线可用的节点的时候,强制下线的风险是高于正常下线的。
综上,强制下线不能加速下线速度,而且会在某些情况下带来更高的风险,因此我们不推荐这一方式。
2 个赞
system
2022 年10 月 31 日 19:21
12
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。