环境:centos
tidb版本:4.0.13
所做操作,将GC时间由1h变为3h,之后又将GC时间由3h调整为1h
现象,单节点的cpu飙升
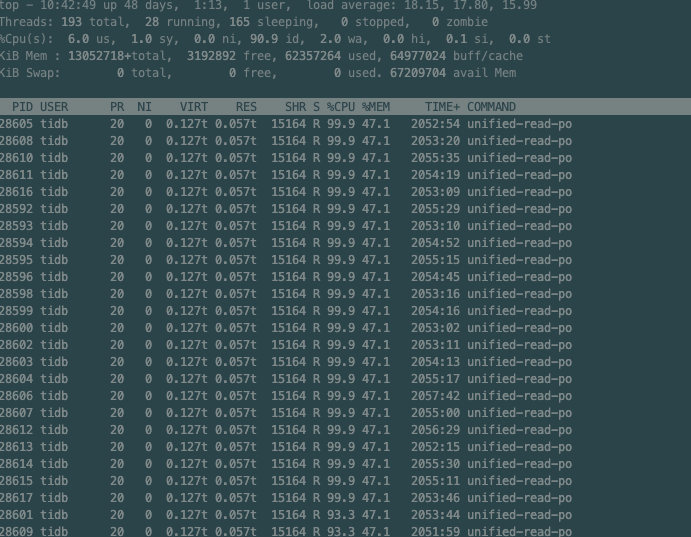
unified read pool cpu
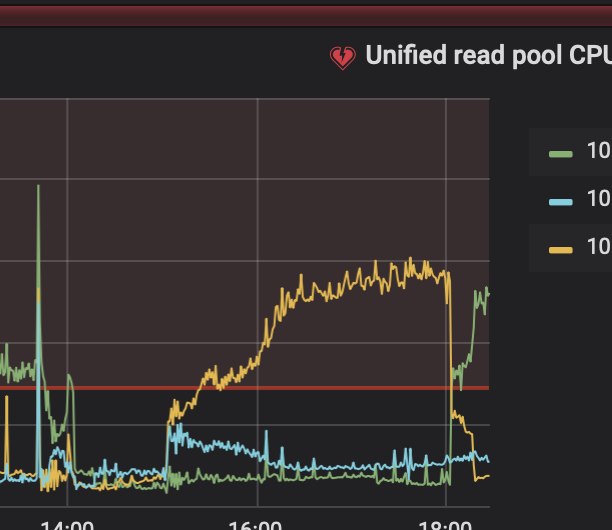
tikv节点cpu

pd-ctl -u http://{pd}:2379 -d region topread [limit]
查了下top100,比较平均,目前不太明白什么情况
环境:centos
tidb版本:4.0.13
所做操作,将GC时间由1h变为3h,之后又将GC时间由3h调整为1h
现象,单节点的cpu飙升
unified read pool cpu
tikv节点cpu
pd-ctl -u http://{pd}:2379 -d region topread [limit]
查了下top100,比较平均,目前不太明白什么情况
这个操作和对应的时间段的 unified pool cpu 的监控发一下吧
可能还是读热点的问题;
操作是
update mysql.tidb set VARIABLE_VALUE=“3h” where VARIABLE_NAME=“tikv_gc_life_time”;
update mysql.tidb set VARIABLE_VALUE=“1h” where VARIABLE_NAME=“tikv_gc_life_time”;
unified read pool cpu
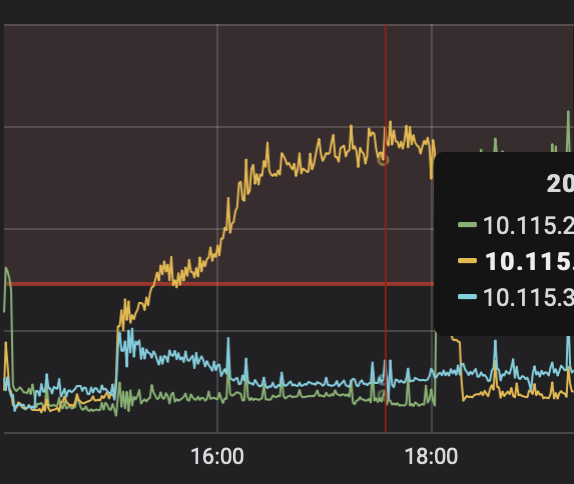
grpc pool cpu
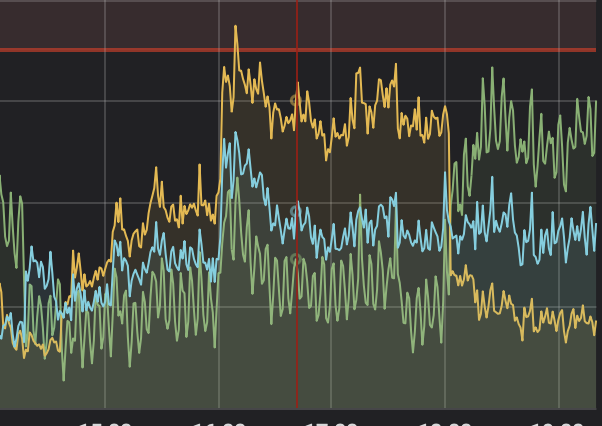
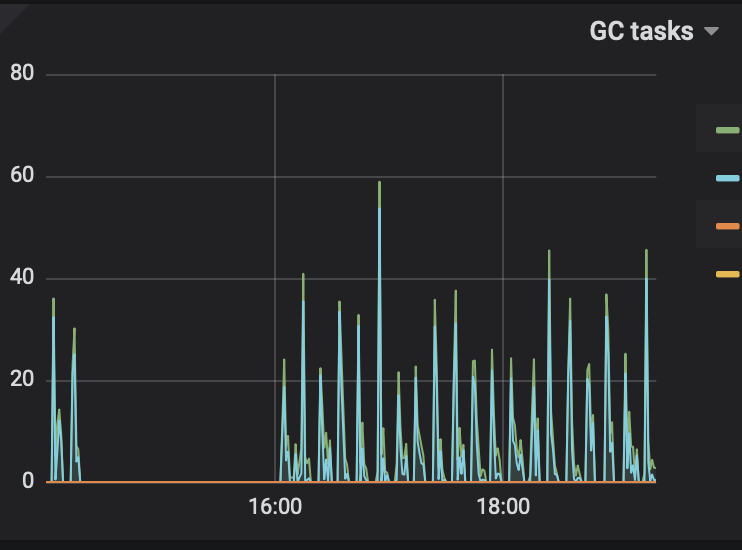
gc task
这个操作对应的时间段可以发一下,需要和你发的监控图一起看。
对应的具体时间段我忘了,没有开全局日志,所以发了个GC tasks有个大概的时间段,空的那段时间是做转变的
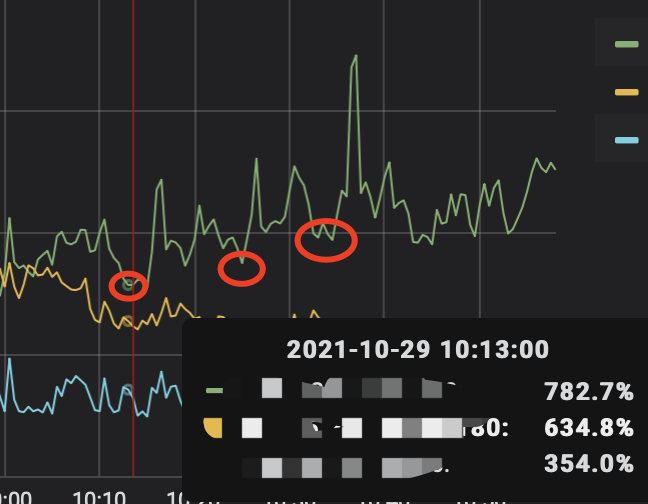
再确认一下飙升的时间点是将 GC 从 1h 调整 3 h 以后吗?
飙升时间是从3h到1h这个操作,应该是几个版本堆积到一起GC的效果,这个时候的慢查寻可能尤为明显,读热点在一张订单表上,之前也有分布不均的情况,然后我在13:30左右的时候还有个br备份的定时任务
目前 v4.0 的 GC 大量的 tombstone key 数据是会有影响到,
v5.0 有一个新特性,可以参考一下 https://docs.pingcap.com/zh/tidb/stable/garbage-collection-configuration#gc-in-compaction-filter-机制
应该想问的是:为什么三个tikv中,只有1个tikv cpu负载比较高? 如果gc引起的,应该理论上三个tikv的负载都会相应飙升才对,目前看 只有一个tikv 在某段时间内 负载居高不下。
应该按热点来排障,其次某个时刻hot read引起某个tikv cpu飙升,为什么没有发生hot schedule?
unified pool cpu 升高很有可能是读数据热点,可以看一下对应的 tikv log 监控,里面会有 slow query 或者 expensive query的 table id 以及时间,结合时间找到对应的 SQL 或者 region 数据应该没有问题。
我这里在看看吧,目前还没有定位到实际的问题
gc-worker
rocksdb:low[0-5],
请教下大佬,这俩是做啥的,第一个应该是gc的么,只会gc的时候调用么,第二个是干啥的
我gc设置一小时一次,但是kv节点上一小时看到了多次这个,
每当这两个出现的时候我的cpu就会有一次凸起,这两个应该会影响下推,进而导致读变慢,导致cpu升高吧,我这里再补充下,gc-worker大概懂了,
按照这两个的配置,我的gc应该再3,13,。。。53时间工作,而cpu的升高也如此,
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。