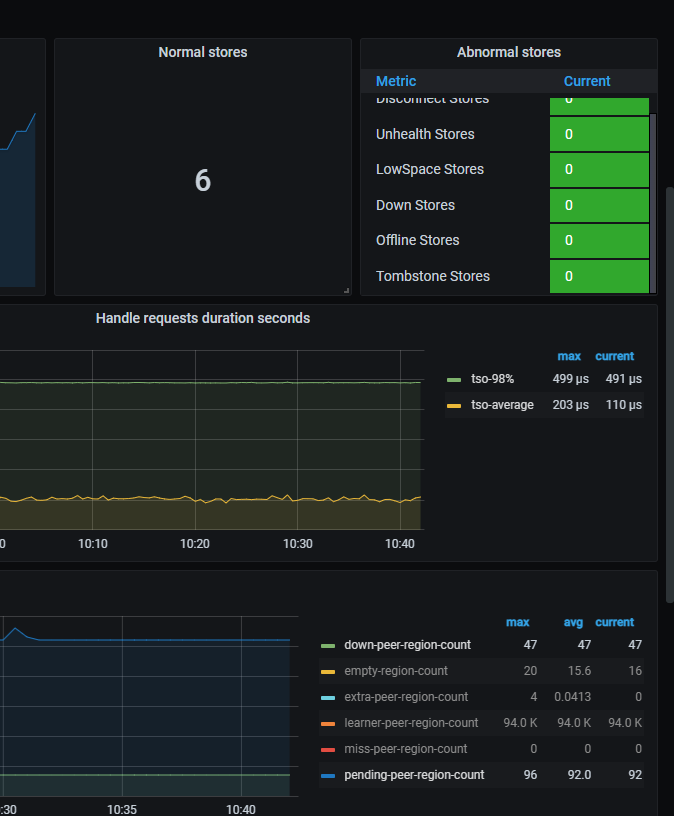
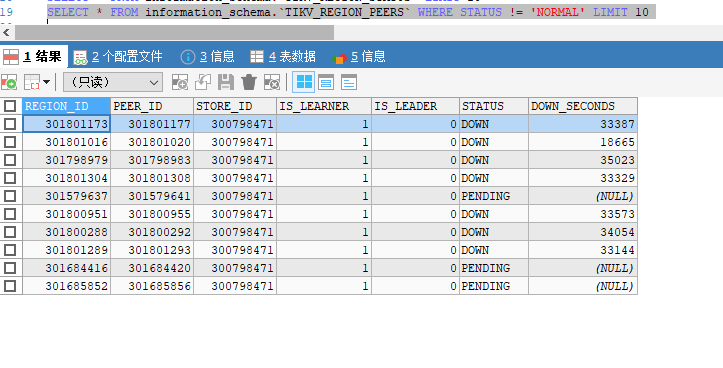
集群正常,但是监控显示 down peer 和pending peer,查表确实有些peer是有问题的,查询偶尔会报错region is unavailable,集群正常,为什么pd没有正确调度修复副本?
这个问题建议先收集下面的信息:
- 明确 down peer,pending peer 分布的 store id
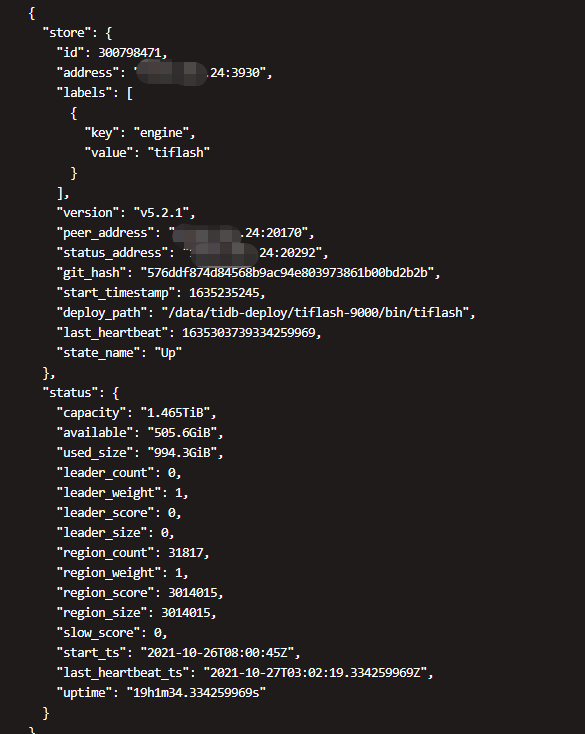
- pd-ctl store {store_id} 查看目标 store 的情况

如果方便的话,可以拿下 pd grafana 的 2 小时的监控,使用下面的方式导出:

请问下,TiFlash 节点 300798471,有出现过因为异常服务终止,然后又拉起的情况吗?
从服务异常终止,到再次拉起,中间隔了多次时间?
昨天下午有一个sql,因为无法下推tiflash,只读取tiflash,在tidb server 计算,跑了1个多小时,这期间,tiflash3个节点经常性的disconnected,时好时坏,这个SQL跑完,过了半个小时近一个小时,tiflash恢复正常,就开始有down peer了
今天就开始各种SQL有问题了,报各种不同的错,我手工修复了peer,所有peer都正常了,但是还是报错
现在的问题是:当前集群中所有的 region 都是正常的状态,TiFlash 以及 TiKV 都没有异常的副本,但是查询 sql 会出现报错~
那么报错的 sql 都是访问 TiFlash 后,出现的报错吗?如果是,请提供下下面的信息:
1、sql 语句文本
2、sql 中目标 table 的 ddl 建表语句
3、sql 中目标 table 的 TiFlash 副本信息,参考文档如下:
https://docs.pingcap.com/zh/tidb/stable/information-schema-tiflash-replica#tiflash_replica
4、执行该 sql 的报错信息
5、执行该 sql 的 tidb server 的 log 日志
另外,集群中有 3 个 TiFlash 节点吗?如果是,请提供下这 3 个 TiFlash 节点的 tiflash.log 以及 tiflash_error.log ~
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。