Limbo
(Limbo)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0
- 【问题描述】:扩容PD节点,进行到使用pd-ctl检查是否添加成功这一步的时候,长时间没有响应
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
yilong
(yi888long)
2
您好:
具体执行了什么命令,能否截图展示一下? 另外请上传PD的日志,多谢
Limbo
(Limbo)
3
pd.rar (369.2 KB) /home/tidb/tidb-ansible/resources/bin/pd-ctl -u “http://172.16.85.49:22378” -d member
yilong
(yi888long)
4
您好:
1. 请问当时执行start_pd.sh成功了吗?
2. 能否反馈一下inventory.ini 和 start_pd.sh的脚本?
3. ./pd-ctl -i -u http://127.0.0.1:2379 举例进入到交互模式下,检查下health状态
https://pingcap.com/docs-cn/stable/reference/tools/pd-control/#简单例子
Limbo
(Limbo)
5
1.执行start_pd.sh后没有提示消息,进程是瞬间结束了,我当时以为成功了
2.start_pd.sh (160 字节) inventory.ini (2.7 KB)
3.执行后,使用health命令如下图
yilong
(yi888long)
6
执行以下,cluster,config show这些命令能成功吗?
yilong
(yi888long)
8
您好:
1. 麻烦反馈下脚本,新机器增加:{deploy_dir}/scripts/run_pd.sh
2. 请反馈一下,pd进入的命令,是使用老的PD-server进入的吗?
./pd-ctl -u : -i
举例 ./pd-ctl -u http://172.16.5.89:2679 -i
Limbo
(Limbo)
9
1.run_pd.sh (654 字节)
2.是用的新的PD进入的
Limbo
(Limbo)
11
1.使用老的PD查看状态,同样报no such host
2是的,在同一机器扩的
Limbo
(Limbo)
13
1.pd.rar (370.2 KB)
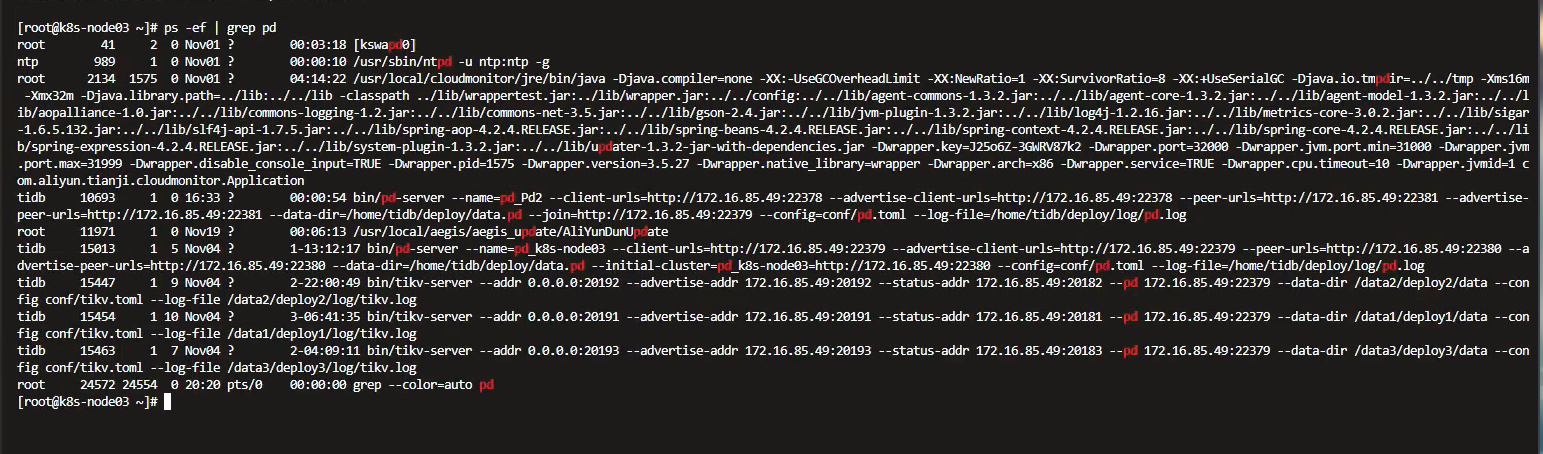
2.存在PD的进程,如图
新的机器待明天添加了
yilong
(yi888long)
14
- 根据第一次反馈的日志,应该是在16:33分添加的pd:
[2019/12/04 16:33:14.837 +08:00] [INFO] [server.go:145] [“start embed etcd”]
[2019/12/04 16:33:14.838 +08:00] [INFO] [etcd.go:117] [“configuring peer listeners”] [listen-peer-urls="[http://172.16.85.49:22381]"]
[2019/12/04 16:33:14.838 +08:00] [INFO] [systime_mon.go:25] [“start system time monitor”]
[2019/12/04 16:33:14.838 +08:00] [INFO] [etcd.go:127] [“configuring client listeners”] [listen-client-urls="[http://172.16.85.49:22378]"]
[2019/12/04 16:33:14.838 +08:00] [INFO] [etcd.go:600] [“pprof is enabled”] [path=/debug/pprof]
[2019/12/04 16:33:14.838 +08:00] [INFO] [etcd.go:297] [“starting an etcd server”] [etcd-version=3.3.0+git] [git-sha=“Not provided (use ./build instead of go build)”] [go-version=go1.12] [go-os=linux] [go-arch=amd64] [max-cpu-set=4] [max-cpu-available=4] [member-initialized=true] [name=pd_Pd2] [data-dir=/home/tidb/deploy/data.pd] [wal-dir=] [wal-dir-dedicated=] [member-dir=/home/tidb/deploy/data.pd/member] [force-new-cluster=false] [heartbeat-interval=500ms] [election-timeout=3s] [initial-election-tick-advance=true] [snapshot-count=100000] [snapshot-catchup-entries=5000] [initial-advertise-peer-urls="[http://172.16.85.49:22381]"] [listen-peer-urls="[http://172.16.85.49:22381]"] [advertise-client-urls="[http://172.16.85.49:22378]"] [listen-client-urls="[http://172.16.85.49:22378]"] [listen-metrics-urls="[]"] [cors="[]"] [host-whitelist="[]"] [initial-cluster=] [initial-cluster-state=existing] [initial-cluster-token=] [quota-size-bytes=2147483648] [pre-vote=true] [initial-corrupt-check=false] [corrupt-check-time-interval=0s] [auto-compaction-mode=periodic] [auto-compaction-retention=1h0m0s] [auto-compaction-interval=1h0m0s] [discovery-url=] [discovery-proxy=]
[2019/12/04 16:33:24.838 +08:00] [INFO] [backend.go:85] [“db file is flocked by another process, or taking too long”] [path=/home/tidb/deploy/data.pd/member/snap/db] [took=10.000125447s]
我想看在这之后的日志,但是第二次反馈的只是到12月4号,日志反馈的不全,多谢。
2. 请查看pd-ctl使用的ip和端口是否正确,感觉使用的不对: ./pd-ctl -u http://172.16.85.49:22379 -i ,进入后执行cluster,或者store看下是否成功.
3. 如果第二步还报错,如果这是一个测试环境,没有什么数据,能否尝试kill掉这个10693添加的进程,看下第二步能否成功.
Limbo
(Limbo)
15
/home/tidb/tidb-ansible/resources/bin/pd-ctl -u “http://172.16.85.49:22379” -i
应该没有错吧,确实是报错的,日志确实就这些了,kill掉进程后,依然报错,如图
yilong
(yi888long)
16
你的引号是中文的,这里别打引号了,类似这样就行
[root@test4 ~]# /home/tidb/ryl/tidb-ansible/resources/bin/pd-ctl -u http://172.16.x.xx:xxxx -i
» cluster
{
“id”: 6739710192564496981,
“max_peer_count”: 3
}